数据库几算法的GPU设计+新闻::基于GPU的OLAP数据库
文章目录pgstrom加速与案例分析加速效果哦pgstrom加速与案例分析加速效果哦
·
数据库中几个常用算法的GPU并行化设计
-
- Select
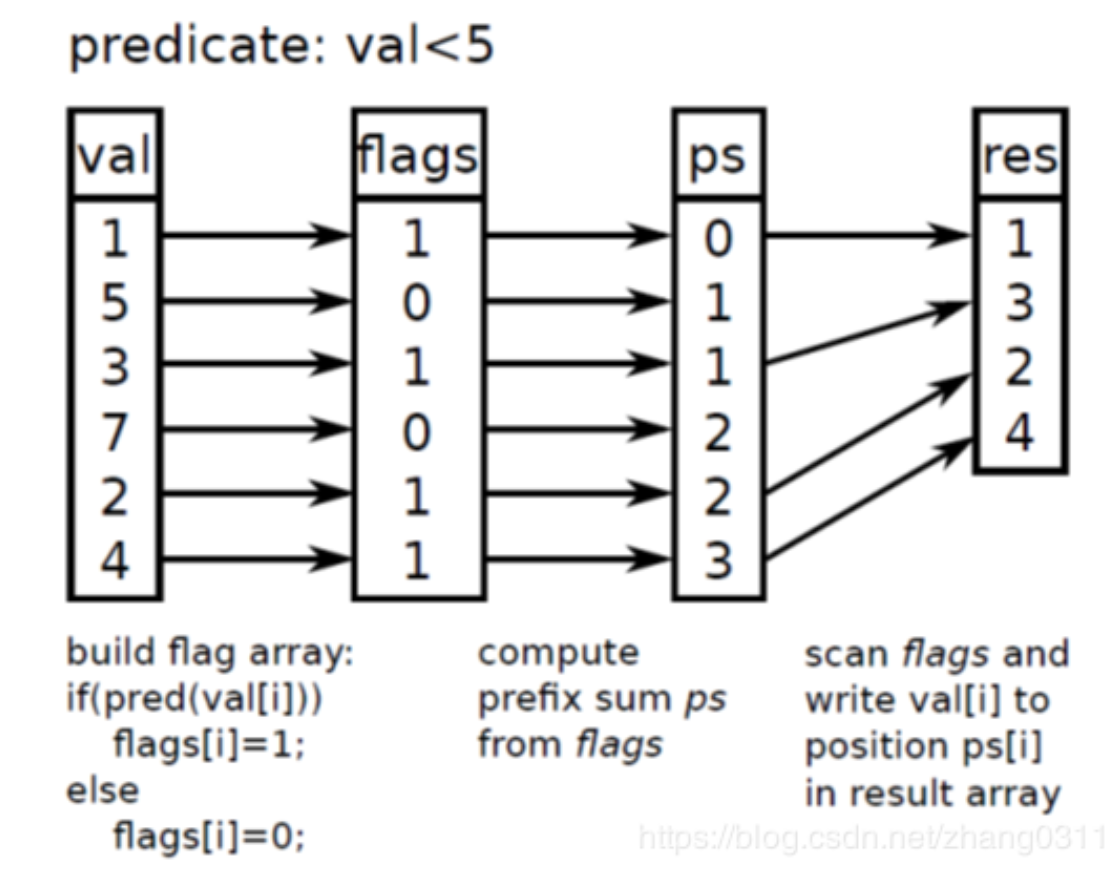
我特么需要先开辟一个一样长的区间啦!
- 注意,我希望最后的结果是[1,3,2,4]
- 首先flag这个数组很容易得到!(且容易并行!)
- 下面要计算flag数组的前缀和!(这个不成了串行了吗,成了瓶颈了吗???)
- ps最后的结果是3,说明结果有4个数字!
ps数组每当出现自增的地方,那对应的那个位置就是结果!吧!这个也很容易并行!
- 我觉得前缀和这样才对吧!
1 1
0 1
1 2
0 2
1 3
1 4
- 感觉直接产生flag
- 然后求和是4
- 就生成含有4个元素的res!
- 然后就能多线程执行产生res[0,1,2,3]可以吗?
- 当然不可以啦!
- 你知道多线程的每个数放在哪个res的槽呢!
- Sub aggregation
canci
新闻::基于GPU的OLAP数据库
- Zilliz获数千万元天使投资,
- 做基于GPU加速的新一代OLAP数据库系统,
- 随着AI浪潮下GPU硬件生态不断成熟,
- 基于GPU的OLAP数据库已具备商业化条件,
- 数据库承担的功能
- 存储和计算,
- 分交易型OLTP(on-line transaction processing)、
- 分析型OLAP(On-Line Analytical Processing)两类:
- OLTP是稳定的,
- 针对基本的、日常的事务处理,
- 银行交易就是一个典型应用,
- 不能出纰漏,大企业基本都用Oracle产品,该市场80%饱和,并且增长缓慢。
- 分析型OLAP是数据仓库系统,
- 支持复杂的分析操作,
- 侧重决策支持,
- 且提供直观易懂的查询结果,
- 智能交通中识别车牌就是典型,
- 需分析大量数据,以及现在火热的AI都需分析型数据库做底层支撑。
- 分析型数据库是创业公司机会
- 存量市场200亿
- 还在保持高速增长
- Oracle有OLTP,也OLAP。
- 第一代分析型数据库/OLAP,
- 代表Oracle的Exadata,
- 缺点是只能储存在EMC这样的高端专有硬件,每个节点花400多万,
- 多节点共享一个存储设备,可拓展性差,只能支持10几个节点。
- 接着第二代数据仓——MPP大规模并行处理。
- 这时数据不需储存在专有硬件上,普通的x86服务器即可,成本下降。
- 各个计算节点的数据独立存在本地的硬盘上,互相不共享,
- 计算时将任务并行的分散到多个服务器和节点上,
- 每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
- 代表产品
- HPVertica、
- EMC收购的Greenplum、
- IBM Netezza,
- 这种架构下节点可拓展至几十个,
- 但依旧不能满足大规模的扩展需求。
- 随着Hadoop发展,
- 第三代数据库崛起,
- 数据存在HDFS,
- HDFS是运行在通用硬件上的分布式文件系统。
- 此时,存储、计算分离,各节点之间能互相访问,
- 扩展性强,可延伸到上千节点。
- 不过新产品的性能还没能很好磨合,
- 有些情况下,第三代数据库不如第二代快速。
- Hadoop上长出很多开源技术,用来更进一步完善、优化性能,
- HAWQ、Hive、Impala、Spark SQL等。
- PC上,CPU负责“计算”,
- “核”就是代表计算能力,核数越大,算力越高。
- 高性能计算时,往往是通过堆CPU服务器来实现集群化计算,但现在CPU的算力已经到了物理极限,目前停留在16核
- GPU之前负责图像渲染,
- 通过模拟现实场景生成逼真的图片,多应用在游戏,
- 比如衣服对风抖动、布料上的纹理等,
- 这些都是经过实时渲染而来。
- 这背后每个离子需要经过大量的物理计算,才能给用户带来观影变化。
- GPU上可以承载数千个处理单元。
- GPU的这种“大规模并行计算”的能力开始被挖掘,从之前协处理器向主流处理器做推移
- 此前数据库是运行在CPU,
- 最新一代是基于Hadoop优化过的开源技术。
- Zilliz要做的是把数据库搬到GPU
- 为什么之前没有人做出来?
- “GPU跑数据库最追溯到15年前的学术。
- 上层软件受下层硬件的约束,导致这么多年没发展起来。
- 如今英伟达等芯片厂商已经把GPU的生态搭建起来,
- 帮开发者把门槛降低,
- 任何人都可以在上面开发应用,就像当初的安卓系统普及一样,
- 现在也有了实现GPU数据库的苗头。”
- 之前PC上的实时数据流是直接传给CPU处理,
- 数据仓库中的数据是从磁盘读取到主存(内存)然后调由CPU处理。
- 这个流程上,GPU数据库没本质变化,
- 只不过数据直接传到GPU
-
改变的是数据库的“存储调度引擎”、“优化器”和“执行器”:
-
“存储调度引擎”决定数据吞吐率,
- 即数据访问、存储的带宽。
- GPU是显存,所以带宽比CPU快1个数量级以上。
-
“优化器”和“执行器”是决定数据库性能关键。
- 优化器找出最佳步骤,执行器负责控制硬件。
- 给一堆数据做排序,“先排序还是先筛选”是由优化器决定,当优化器决定先排序时,接下来由执行器调配硬件。
- 当底层的物理媒介从CPU变为GPU时,执行的架构模型显然需要完全改变。
- GPU可以做大规模处理,CPU只是单线处理,处理数据的算法上会发生质改变,速度提高1个数量级。
- Zilliz可比CPU数据库的性能提高100
- 6月Zilliz已完成第一代产品研发,重点选择银行、政府、互联网行业,
- 目前在测试阶段,收费规则还在探索。
- Zilliz首先支持的是基于英伟达GPU的解决方案,预计今年年底产品正式上线,之后跟进ATI解决方案,以及FPGA也是尝试方向
- 不到20人。创始人谢超校友曾就职于甲骨文(Oracle)公司美国总部,负责数据库系统的核心研发工作。
- 作为奠基人之一研发的Oracle 12c多租户数据库(Oracle Multitenant)采用多租户管理的理念,通过可插拔式结构实现数据库集群的动态管理,成功实现在公有云或者私有云上提供数据库服务,迄今已经为公司创造了超数十亿美金营收
canci

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)