性能测试|告别卡顿!云端解锁ParaView并行渲染,千万级网格模型可视化
本文主要介绍 ParaView在SimForge™高性能仿真云平台上的使用,通过对算例热点函数的性能加速分析,发现增加GPU数量对数据I/O、数据生成和数据提取操作的并行加速效果非常可观 。

ParaView是一款开源的通用数据分析和可视化工具,用于处理各种类型的科学和工程数据集。它可读取多种数据格式,常见的如VTK、CSV、XDMF等。同时,ParaView也是一个跨平台的工具,不仅支持Windows、Linux和Mac OS等操作系统,还可以在多种计算机架构上运行,如x86、POWER、ARM等。支持这些并行架构意味着ParaView可以并行处理庞大的数据集,收集各进程上的结果,并将其可视化。在可视化方面,ParaView提供了许多通用的可视化技术用于显示和分析工程数据集,如切片、等值面、流线、轮廓、高级渲染等。
本文主要介绍 ParaView在SimForge™高性能仿真云平台上的使用,通过对算例热点函数的性能加速分析,发现增加GPU数量对数据I/O、数据生成和数据提取操作的并行加速效果非常可观 。
01 什么是可视化
可视化过程是指将原始数据转为一种可以直接显示并且易于理解的形式。这个过程可以帮助用户更好地理解数据,从而揭示数据背后的隐藏关系。在ParaView中,可视化过程通常包括三个步骤,分别是读取数据,过滤数据和渲染数据。
读取数据即是从数据源文件中获取数据,存储在ParaView支持的数据类型中。
过滤数据即是根据不同需求对数据进行预处理,常见有以下操作:
1、切片(Slice)
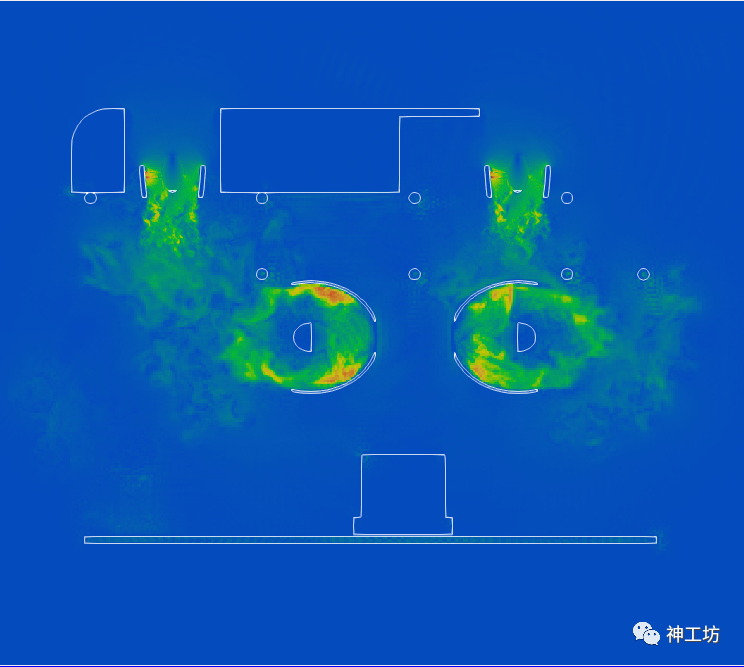
是通过在数据集上切割平面,选择切割平面的位置和方向,并调整可见的切片厚度来显示沿着该平面的数据分布。如下图所示,图中为某平面上速度的数据分布。
2、等值面(Isosurface)
是将数据集中特定数值的表面提取出来,以显示数据的连续性或离散性。根据需求,设置不同的等值面数值。如下图所示。

3、流线(Streamlines)
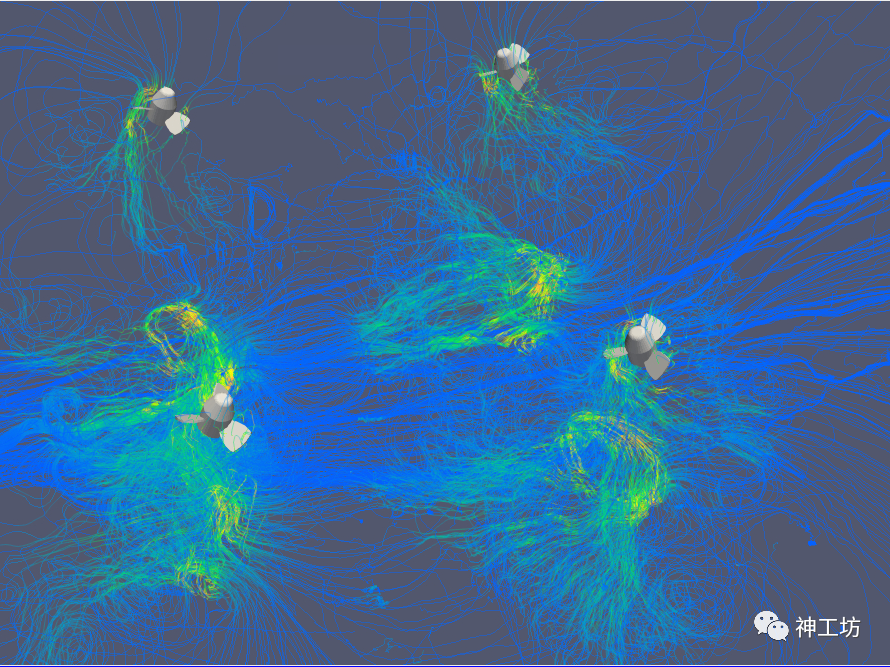
是根据数据集中的矢量场信息,绘制流线以显示流体或气体的流动路径和速度。可以根据需要调整流线的密度和长度。如下图所示。
4、高级渲染(Advanced Rendering)
即是提供各种高级的渲染技术,如体绘制、体积渲染、阴影、反射等,以增强可视化效果和表达能力。
02 如何在神工坊平台上使用ParaView进行并行渲染?
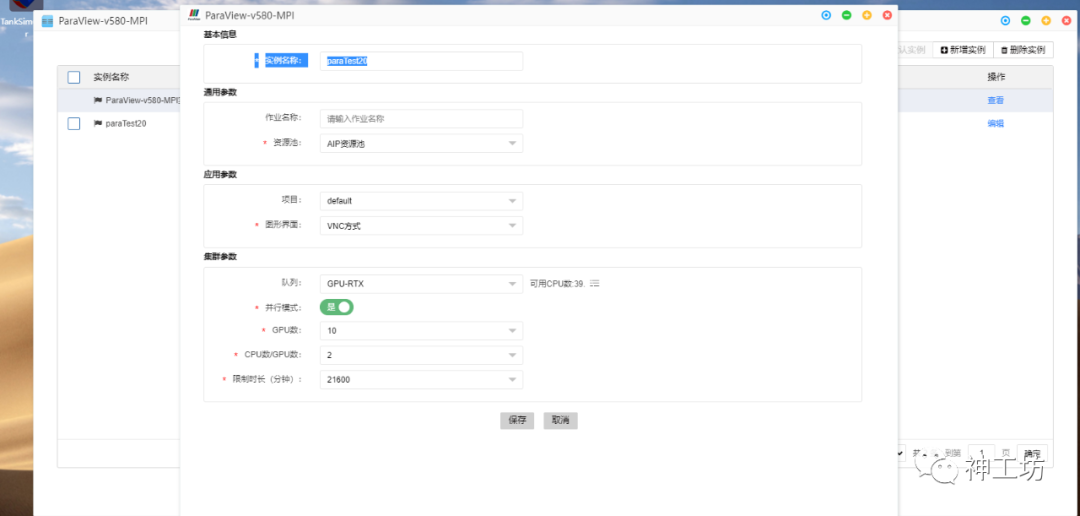
首先,用户需要在神工坊平台上运行ParaView实例,具体操作如下图(点击登录SimForge™高性能仿真云)。神工坊目前已经为用户完成并行运行模式的配置,用户只需要选择适合的CPU和GPU数量即可开始体验。
在渲染上,ParaView实际是 调用了IceT库实现其并行渲染算法。IceT是一个开源的并行图像合成库,主要用于 在大规模并行计算环境中可视化和渲染应用程序。IceT库提供了高效的并行渲染方法,适用于需要处理大规模数据集的可视化应用程序。ParaView通过库中sort-last算法进行并行渲染,算法将图像分割成多个小块,每个处理器都独立地渲染它所负责的块,并生成局部图像。然后,利用通信库(MPI)将这些局部图像组合起来,形成最终的合成图像。
03 GPU性能加速对比分析
本文通过展示水下机器人算例流场的可视化过程,对GPU性能加速效果进行对比。该算例描绘的是水下机器人在静水域中,上方四个螺旋桨旋转引起的流场演化过程。源数据为某时间步,整个流场的速度场。我们对速度场在某一平面进行切片并且叠加上四个螺旋桨的涡量等值面。可视化结果如下图所示。
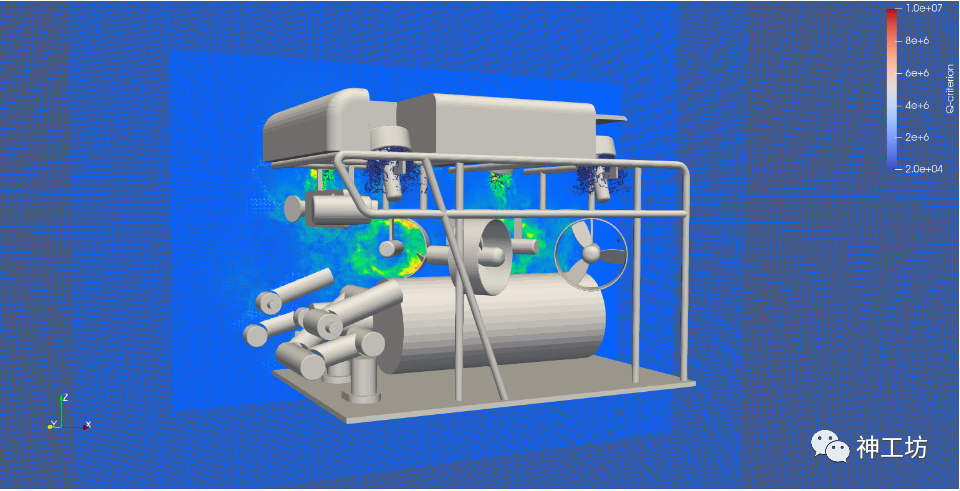
上述可视化过程可被抽象为四个部分: 数据I/O、数据生成、数据提取和数据渲染。
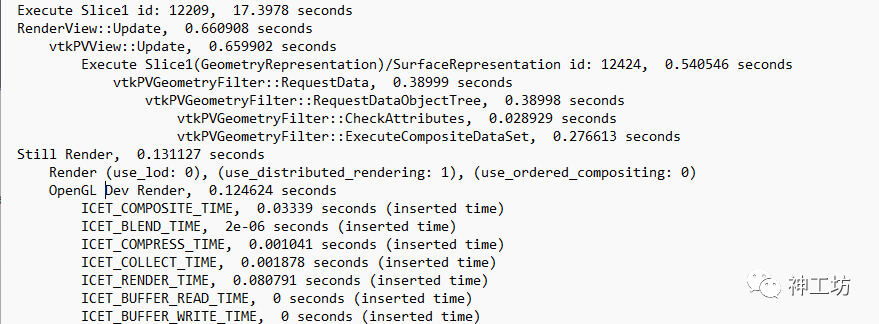
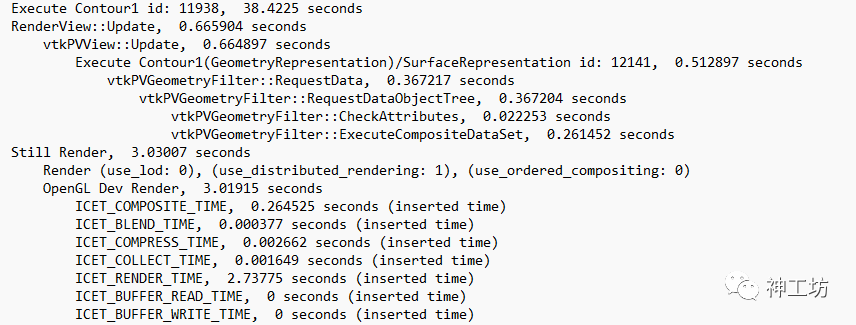
其中, Execute Slice为数据生成过程,用于计算并存储在某平面上的数据。 RenderView::Update为数据提取过程,负责提取在这个平面上的数据,提供用于渲染。 Still Render为全分辨率渲染过程。
下面将展示不同资源配置下,切片和等值面绘制在数据I/O、生成、提取、渲染上的耗时,从而说明增加GPU对上述四个部分的加速效果。
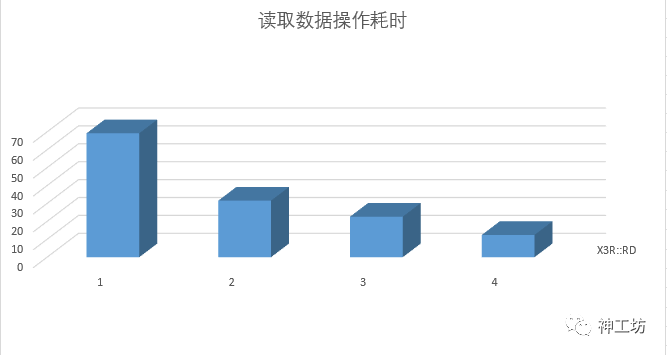
1、 数据I/O
源数据数据大致为 6000万网格,大小约2.75G。
下表记录了 ParaView读取数据操作耗时,括号内为增加GPU数量的加速比。
|
GPU数量操作 |
1 |
2 |
4 |
8 |
|
X3R::RD |
69.23s |
31.60s (119%) |
22.64s(205%) |
12.44s (456%) |
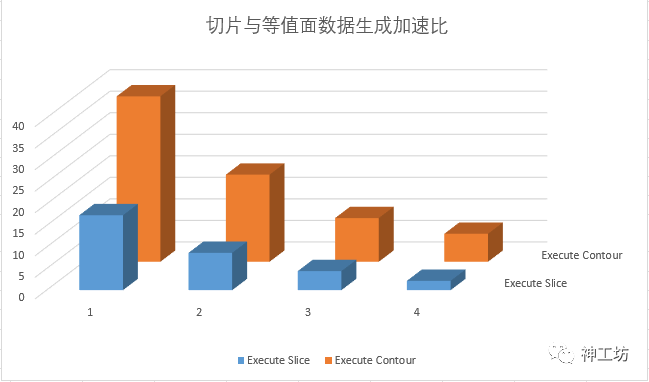
2、数据生成
下表记录了 切片和等值面绘制的数据生成操作耗时,括号内为随着GPU数量增多,效率的加速比。
|
GPU数量操作 |
1 |
2 |
4 |
8 |
|
Execute Slice |
17.39s |
8.66s(101%) |
4.42s(293%) |
2.17s(701%) |
|
Execute Contour |
38.42s |
20.23s(89.9%) |
10.15s(377%) |
6.5s(491%) |
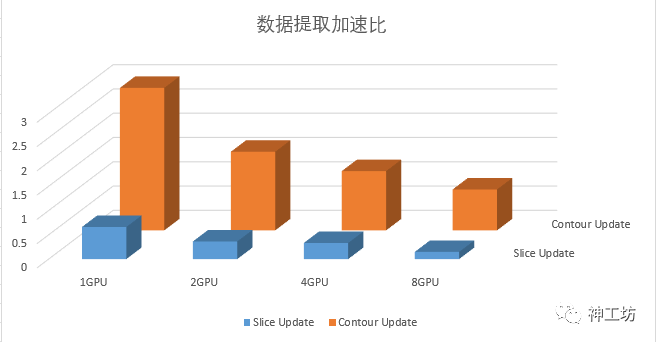
3、 数据提取
下表记录了 切片和等值面绘制的数据生成操作耗时,括号内为随着GPU数量增多,效率的加速比。
|
GPU数量操作 |
1 |
2 |
4 |
8 |
|
Slice Update |
0.661s |
0.363s(82%) |
0.332s(99%) |
0.147s(350%) |
|
Contour Update |
2.935s |
1.619s(81%) |
1.221s(140%) |
0.843s(248%) |
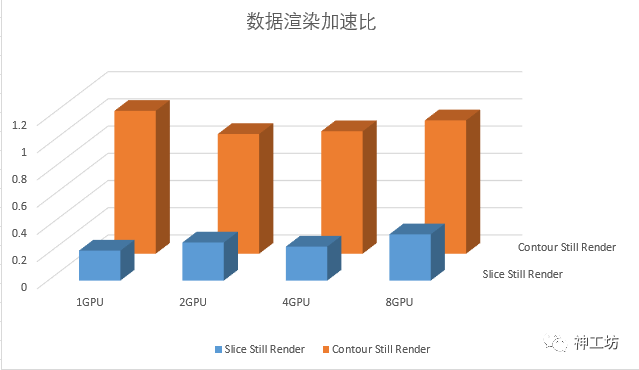
4、 数据渲染
下表记录了 数据提取完成后,切片和等值面绘制过程中数据渲染操作耗时。
|
GPU数量操作 |
1 |
2 |
4 |
8 |
|
Slice Still Render |
0.22s |
0.28s |
0.25s |
0.34s |
|
Contour Still Render |
1.05s |
0.88s |
0.9s |
0.98s |
04 结论
综上所述,通过对这些热点函数的性能分析,可以看到增加GPU数量对数据I/O、数据生成和数据提取操作的并行加速效果非常可观。考虑到本次展示的数据集较小,仅为6000万网格,可以推断,选用更为精细的数据集则加速效果更为明显。


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)