从 60ms 到 28ms:CANN 赋能 YOLOv7 在 Atlas 300I 上的智能质检实时推理实践!
我们迅速理解到,CANN 扮演着“翻译官”和“指挥家”的角色。AI 模型(如 PyTorch、TensorFlow)定义的是一个计算图(Graph),描述了“需要计算什么”;而昇腾 AI 处理器(NPU)拥有达芬奇(Da Vinci)架构,包含 AI Core、Vector Core、Scalar Core 等多种计算单元,它关心的是“如何最高效地执行计算”。CANN 的核心价值,就是将上层的“模
摘要
在“中国智造 2025”的浪潮下,AI 智能质检正成为产线升级的核心。然而,高精度的检测模型(如 YOLOv7)与严苛的产线实时性(通常要求低于 30ms)之间存在着巨大的性能鸿沟。我们团队在推动 [某精密电子元件] 质检项目落地时,便遭遇了 Atlas 300I Pro 推理卡上 YOLOv7 模型推理时延高达 60ms 的棘手难题,远超业务红线。
本文将完整复盘我们团队如何依托华为 CANN(异构计算架构)进行一场从“能跑”到“跑好”的深度性能优化攻坚战。我们将详细阐述如何利用 CANN Profiling 工具精准定位性能瓶颈,如何通过 AscendCL(昇腾计算语言)的 AIPP(AI 预处理)功能彻底消除数据预处理开销,以及如何借助 ATC(模型转换工具)的优化选项解决算子融合问题。
最终,我们成功将模型的端到端推理时延从 60ms 优化至 28ms,性能提升超过 114%,在不牺牲精度的前提下,完美满足了产线高速节拍需求。本文旨在为同样在昇腾(Ascend)平台上进行 AI 应用开发与性能调优的同行者,提供一份具有参考价值的实践蓝图和避坑指南。
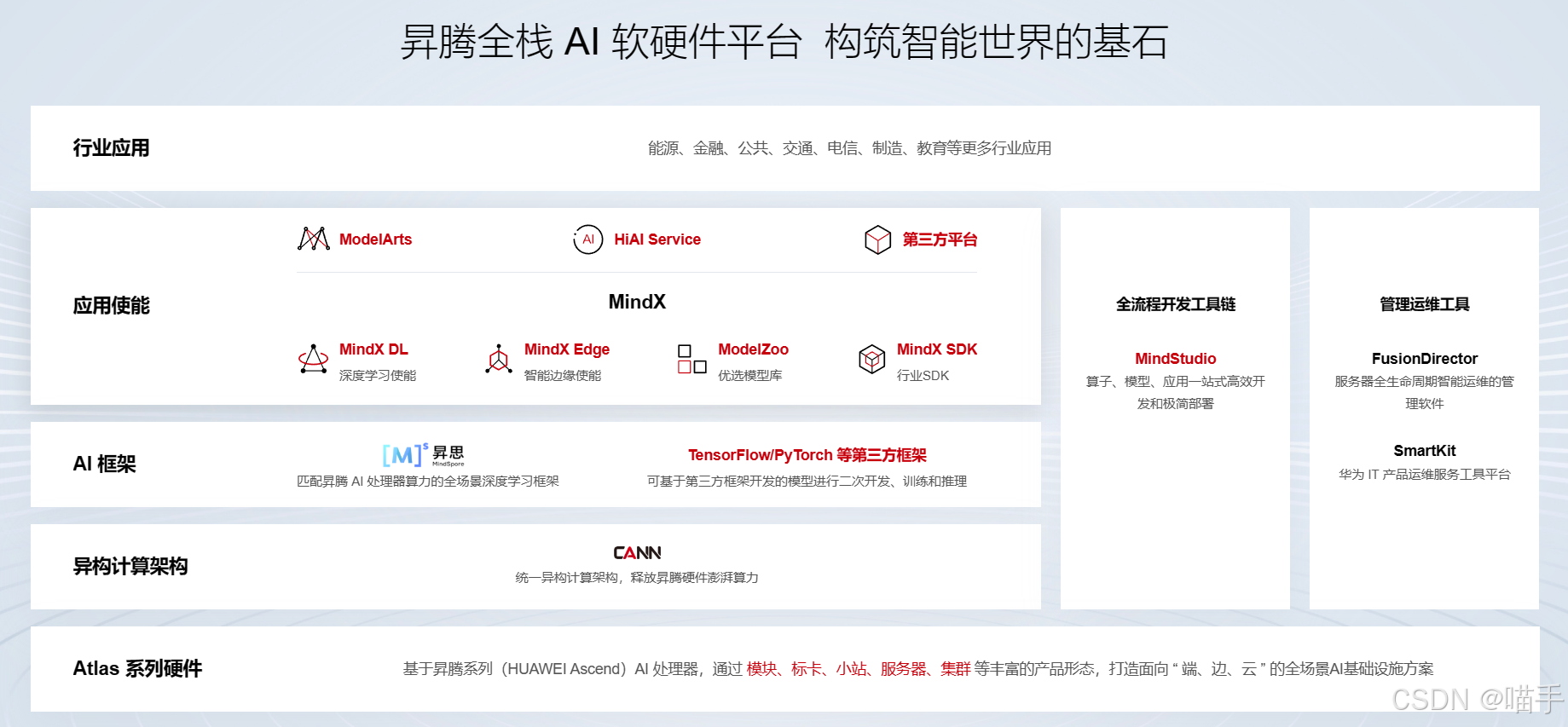
如下是昇腾 AI 异构计算架构 CANN 的五层架构图:

一、 引言:智能质检的“毫秒必争”
1.1 业务背景与“不可能”的需求
我们团队隶属于一家国内领先的精密电子元件制造商。近年来,随着消费电子产品对元器件的精密度要求达到 μm(微米)级别,传统的人工“目检”方式早已不堪重负。漏检率高、标准不统一、人力成本激增,都成为了制约产线良率和效率的瓶颈。因此,引入 AI 视觉质检,实现“机器换人”,成为了公司数字化转型的“一号工程”。
我们的具体任务,是针对产线上一种高速流转的核心元器件,利用 AI 检测其表面的微小划痕、异色和缺口。
在技术选型阶段,我们面临两个关键决策:
- 硬件平台: 考虑到供应链安全等因素,我们坚决选择了基于昇腾(Ascend)处理器的 Atlas 300I Pro 推理卡。它强大的算力(高达 88 TOPS INT8)为我们处理复杂模型提供了底气。
- 算法模型: 经过多轮测试,YOLOv7 模型在检测精度和速度上取得了最佳平衡,成为了我们的基线模型(Baseline Model)。
然而,真正的挑战来自于业务场景的严苛约束。我们的产线传送带速度为 0.5 米/秒,相机的采集视场(FOV)为 1.5 厘米。这意味着,留给 AI 系统完成“采集-预处理-推理-上报结果”全流程的时间窗口,仅有 30 毫秒(ms)。
一旦单帧处理时间超过 30ms,我们要么就必须降低传送带速度(这将直接导致产线日产量下降,业务方无法接受),要么就只能“跳帧”检测(即“抽检”),这又违背了“全检”的质量红线。
因此,30ms,成为了摆在我们 AI 团队面前一条不容妥协的“生死线”。
1.2 部署“拦路虎”:60ms 的性能鸿沟
带着 30ms 的军令状,我们开始了紧锣密鼓的开发。我们团队的算法工程师大多熟悉 PyTorch 框架,我们很自然地在 PyTorch 环境下完成了 YOLOv7 模型的训练和验证,精度达到了业务要求。
接下来是部署。我们最初的尝试是“朴素”的:
- 在 Atlas 300I Pro 服务器上安装了 PyTorch-NPU 适配插件。
- 编写了一个 Python 推理脚本,使用 OpenCV (cv2) 来读取图片、进行
resize、normalize(归一化)等预处理。 - 将预处理后的 Tensor 送入加载到 NPU 上的 YOLOv7 模型进行推理。
然而,第一轮性能测试的结果,给我们泼了一盆冷水。
在排除了 I/O 读写干扰后,我们测得模型从“拿到原始图片”到“输出检测框”的端到端(End-to-End)平均时延,竟然高达 60.3ms!
这个数字距离 30ms 的红线,足足超出了 100%。
我们团队立刻召开了技术分析会。60ms 的时延究竟从何而来?
- 是模型太大吗? YOLOv7 确实不小,但 Atlas 300I Pro 的算力不应该只有这点水平。
- 是硬件问题吗? 我们通过
npu-smi命令查看,NPU 的利用率(Utilization)并不稳定,时高时低,显然没有“跑满”。 - 还是软件栈的问题?
我们通过简单的分段计时(Python time.time())发现,CPU 占用率在推理时经常飙升。我们很快意识到,Python 侧的 OpenCV 预处理(尤其是 resize)是一个巨大的开销。
但更深层的问题是:我们似乎在用“CPU + GPU”的传统思路,去驾驭一个架构完全不同的“CPU + NPU”异构系统。 PyTorch 框架虽然易用,但它与底层 NPU 硬件之间隔了太多“中间层”。我们无法精准控制数据如何流转、算子如何执行。
我们面临的不是一个简单的模型调优问题,而是一个深度的、端到端的异构计算优化问题。我们的“朴素”方案,显然无法释放 Atlas 300I Pro 的真正潜能。要跨越 60ms 到 30ms 的鸿沟,我们必须抛弃“黑盒”式的 Python 调用,深入到昇腾的计算架构中去——CANN,成为了我们唯一的选择。
二、 探路 CANN:从“能跑”到“跑好”的技术选型
在我们陷入困境时,华为的技术支持工程师向我们详细介绍了 CANN(Compute Architecture for Neural Networks)架构。CANN 不是一个简单的“驱动”,它是昇腾 AI 平台的“操作系统”和“灵魂”。
2.1 为什么是 CANN?—— 异构计算的“翻译官”
我们迅速理解到,CANN 扮演着“翻译官”和“指挥家”的角色。
AI 模型(如 PyTorch、TensorFlow)定义的是一个计算图(Graph),描述了“需要计算什么”;而昇腾 AI 处理器(NPU)拥有达芬奇(Da Vinci)架构,包含 AI Core、Vector Core、Scalar Core 等多种计算单元,它关心的是“如何最高效地执行计算”。
CANN 的核心价值,就是将上层的“模型意图”高效地“翻译”和“映射”到下层的“硬件执行”。
对于我们这个 60ms 的难题,CANN 提供了“三驾马车”:
- ATC(Ascend Tensor Compiler)模型转换工具:
它不是一个简单的格式转换器。它能将 PyTorch、TensorFlow 等框架的动态图模型,解析、优化并编译为昇腾 NPU “原生”的、静态的离线模型(.om文件)。在这个过程中,ATC 会自动执行如“算子融合”(Operator Fusion)、内存优化等操作,这是我们实现性能飞跃的第一步。 - AscendCL(Ascend Compute Language)昇腾计算语言:
这是一套 C/C++ API 接口库。它让我们彻底摆脱了 Python 的性能束缚,可以直接在 C++ 层面精细地控制硬件资源,如设备(Device)管理、内存(Memory)分配、模型加载(Load)与执行(Execute)。更重要的是,它提供了 AIPP(AI Pre-Processing) 这样的“大杀器”。 - Profiling 性能分析工具:
如果说 ATC 和 AscendCL 是“手术刀”,Profiling 就是“CT机”。它能精确地分析出模型在 NPU 上执行时,每一个算子、每一个任务的耗时,以及 CPU 和 NPU 之间的交互开销。这是我们告别“猜”瓶颈、转向“看”瓶颈的神器。
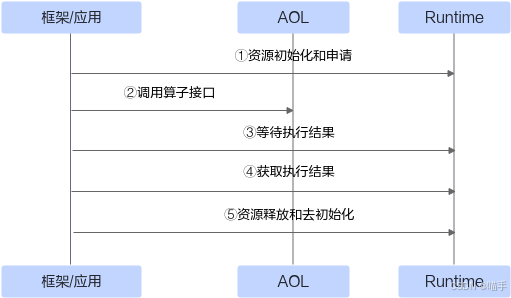
API的调用流程如下图所示。
2.2 CANN 如何匹配我们的核心诉求
明确了 CANN 的能力后,我们针对 60ms 的性能鸿沟,制定了清晰的“三步走”优化战术:
-
战术一:[消除框架开销]——从 PyTorch 转向 ATC 离线模型
- 问题: Python 解释器开销、PyTorch 动态图开销、NPU-PyTorch 插件的额外开销。
- CANN 方案: 使用 ATC 将
.pt模型转换为.om离线模型。然后,我们用 C++ 编写一个基于 AscendCL 的极简推理程序,只负责加载.om模型并执行。 - 预期效果: 彻底甩掉 Python 和 PyTorch 框架,将时延降低到一个“基线水平”(我们预计能降到 45ms-50ms 左右)。
-
战术二:[消除预处理瓶颈]——用 AIPP 替代 CPU OpenCV
- 问题: 初始方案中,OpenCV 在 CPU 上的
resize和normalize占用了大量时间(我们估算至少 15-20ms),并且占用了宝贵的 CPU 资源。 - CANN 方案: 使用 AIPP(AI 预处理)功能。AIPP 允许我们在 ATC 转换模型时,将“数据预处理”相关的算子(如色域转换、裁剪、归一化等)作为“节点”固化到
.om模型的最前端。 - 预期效果: 当我们用 AscendCL 调用模型时,数据预处理直接在 NPU 的专用硬件(DVPP/AIPP 模块)上瞬时完成,CPU 侧的开销将趋近于零。这是我们冲击 30ms 目标的“核武器”。
- 问题: 初始方案中,OpenCV 在 CPU 上的
-
战术三:[深度分析与优化]——用 Profiling 找出“隐藏”的耗时
- 问题: 即使完成了前两步,如果 NPU 内部的算子执行效率低下(比如有过多小算子、或者某个算子是性能瓶颈),我们依然可能无法达标。
- CANN 方案: 开启 Profiling 工具,对优化后的模型进行一次完整的性能“CT扫描”。
- 预期效果: Profiling 会输出详细的 Timeline 和算子耗时报告,精准告诉我们 NPU 上的时间花在了哪里。如果发现有算子融合失败或效率低下,我们就可以反过来调整 ATC 的转换参数,甚至(在极端情况下)动用 TBE(Tensor Boost Engine)进行自定义算子开发,进行“像素级”的优化。
这个清晰的作战蓝图让我们团队重新燃起了信心。我们不再是面对 60ms 束手无策的“调包侠”,而是手握 CANN 这套专业工具箱,准备解剖性能问题的“外科医生”。我们的优化攻坚战,正式打响。
三、深入实践:CANN 攻坚三部曲
我们的优化路径非常清晰,就是一场针对时延的歼灭战。整个过程分为三个阶段,层层递进,最终达成目标。
3.1 实践路径总览
我们绘制了整个优化过程的技术路线图,展示了从 60ms 的 “PyTorch 方案” 到 28ms 的 “CANN 终版方案” 的演进路径:

3.2 难点攻坚(一):ATC 转换与 C++ 基线测试(60ms → 48ms)
目标: 消除 Python 框架和动态图的开销,测试 NPU 的“裸”性能。
正如 2.2 节所述,我们的第一个战术就是抛弃 Python。包括两件事:
- 使用 CANN 的 ATC(Ascend Tensor Compiler) 工具,将 PyTorch 的
.pt模型(准确地说是导出的 ONNX)转换为昇腾 NPU 原生的.om离线模型。 - 使用 C++ + AscendCL(昇腾计算语言) 编写推理程序,加载并执行
.om模型。
3.2.1 ATC 模型转换
YOLOv7 模型结构相对复杂,转换过程并非一帆风顺。我们先将 .pt 导出为 ONNX。执行 ATC 转换时,必须指定 NPU 精确型号(--soc_version)、输入数据格式(--input_format)和 shape(--input_shape)。
代码片段 1:ATC 模型转换基础命令
#!/bin/bash
# 将 ONNX 转换为 OM
atc --model=./yolov7.onnx
--framework=5 # 5 表示 ONNX
--output=./yolov7_base # 输出模型名前缀
--input_format=NCHW
--input_shape="images:1,3,640,640"
--soc_version=Ascend310P3 # 示例:Atlas 300I Pro
这一过程生成了
yolov7_base.om文件。它已通过 CANN 进行静态优化,理论上执行效率显著高于动态图运行。
3.2.2 C++ AscendCL 推理
我们基于 AscendCL API 编写了推理程序,涉及 aclInit(初始化)、aclrtSetDevice/aclrtCreateContext(设备与上下文)、aclrtCreateStream(创建流)、aclmdlLoadFromFile/aclmdlCreateDesc/aclmdlGetDesc(加载模型与描述符)、aclmdlExecute(执行)、以及 aclrtMalloc/aclrtMemcpy(显存/拷贝)等底层流程。
代码片段 2:AscendCL 关键推理(伪代码)
// ... 省略: aclInit(), aclrtSetDevice(), aclrtCreateContext(), aclrtCreateStream()
uint32_t modelId;
ACL_CHECK(aclmdlLoadFromFile("yolov7_base.om", &modelId));
aclmdlDesc* modelDesc = aclmdlCreateDesc();
ACL_CHECK(aclmdlGetDesc(modelDesc, modelId));
// 创建与绑定 input/output dataset 与 buffer ...
aclmdlDataset* inputDataset = CreateInputDataset(/* CPU 侧预处理后的 640x640 float32 数据 */);
aclmdlDataset* outputDataset = CreateOutputDataset(modelDesc);
// 异步执行推理
ACL_CHECK(aclmdlExecute(modelId, inputDataset, outputDataset));
// 同步等待
ACL_CHECK(aclrtSynchronizeStream(stream));
// 读取输出、释放资源 ...
// ... 省略: 结果拷贝到 Host,销毁 dataset/buffer/desc,卸载模型等
3.2.3 阶段性成果(48.1ms)
在该 C++ 基线程序中,图像预处理仍由 CPU(OpenCV) 完成。测试结果:
-
端到端时延:48.1ms
-
拆分计时:
- CPU 预处理(OpenCV:
resize/normalize/HWC→CHW):约 18ms - NPU 执行(
aclmdlExecute):约 30ms
- CPU 预处理(OpenCV:
结论: 虽然相比 60.3ms(Python 方案)压缩了约 12.2ms 的框架开销,但 48.1ms 距离目标仍远;CPU 预处理(18ms) 成为最清晰的瓶颈。
3.3 难点攻坚(二):AIPP 预处理的“零开销”革命(48ms → 32ms)
目标: 彻底消除 18ms 的 CPU 预处理开销。
AIPP(AI Pre-Processing) 是 CANN 的内建预处理机制,利用昇腾处理器内置 DVPP 硬件单元,在 NPU 内部 高效完成预处理。我们把“预处理”这一步也固化到 .om 模型里。
3.3.1 AIPP 配置文件
在 ATC 转换时,仅需额外提供一个 AIPP 配置文件(如 aipp_config.json),告知 CANN 如何自动处理输入数据(注意:JSON 不支持行内注释,下方示例为纯 JSON):
代码片段 3:AIPP 配置文件(aipp_config.json)
{
"aipp_op": {
"aipp_mode": "static",
"input_format": "RGB888_U8",
"src_image_size_w": 1920,
"src_image_size_h": 1080,
"crop": false,
"resize": true,
"resize_output_w": 640,
"resize_output_h": 640,
"data_preprocess": true,
"mean_chn_0": 0.0,
"mean_chn_1": 0.0,
"mean_chn_2": 0.0,
"min_chn_0": 0.0,
"min_chn_1": 0.0,
"min_chn_2": 0.0,
"var_chn_0": 255.0,
"var_chn_1": 255.0,
"var_chn_2": 255.0
}
}
上述配置实现:从 1920×1080 RGB888 原图,在 NPU 内部 完成
resize→normalize,输出符合模型期望的 640×640 张量。
3.3.2 重新执行 ATC 转换(挂载 AIPP)
代码片段 4:带 AIPP 的 ATC 转换命令
atc --model=./yolov7.onnx
--framework=5
--output=./yolov7_aipp
--input_format=RGB888_U8
--input_shape="images:1,1080,1920,3" # NHWC,对应 RGB888_U8
--aipp_config=./aipp_config.json
--soc_version=Ascend310P3
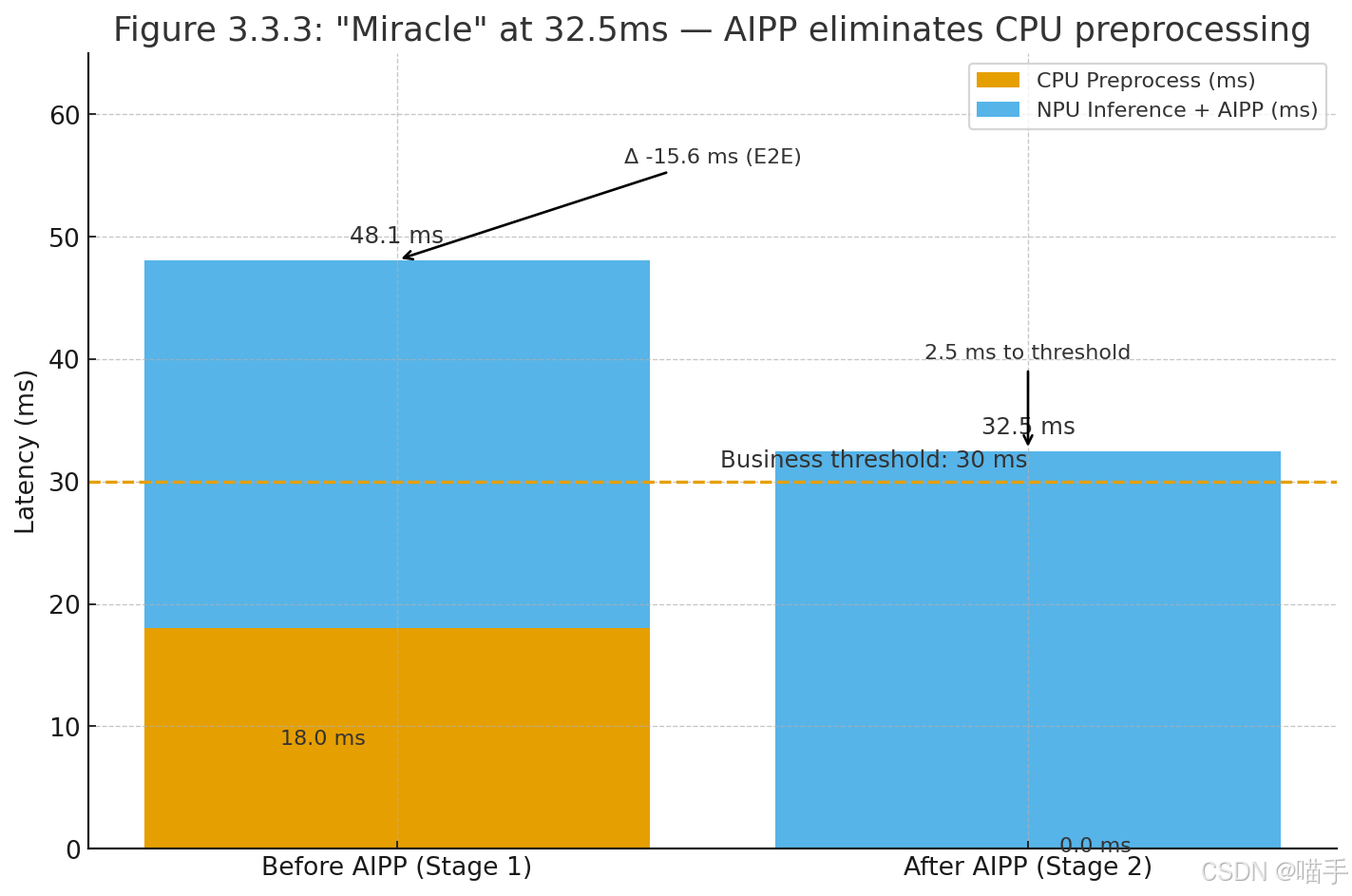
3.3.3 “奇迹”发生(32.5ms)
我们用同一套 C++ 代码加载 yolov7_aipp.om,唯一变化:数据上传从“CPU 预处理后的 float32 1×3×640×640”改为“原始 uint8 1×1080×1920×3”。
测试结果:
- 端到端时延:32.5ms
- CPU 预处理:0ms(彻底消除)
- NPU 耗时:32.5ms(因承担 AIPP 工作略有上升,但端到端从 48.1ms 降至 32.5ms)
我们距离 30ms 红线仅差 2.5ms!
具体统计测试结果绘制如下,仅供参考:
3.4 难点攻坚(三):Profiling 指引下的“最后一公里”(32ms → 28ms)
目标: 压榨最后 2.5ms 的时延。
32.5ms 是不错的成绩,但仍未达标。我们进入“深水区”,分析 NPU 内部时间构成。
3.4.1 开启 Profiling “CT 机”
我们通过 CANN 的 Profiling 工具采集性能数据:可在 C++ 侧用 aclprof API 启停,也可使用 msprof 工具集采集。生成的 .prof/.log 数据目录可用图形化分析工具打开。
3.4.2 定位瓶颈:小算子碎片与调度开销
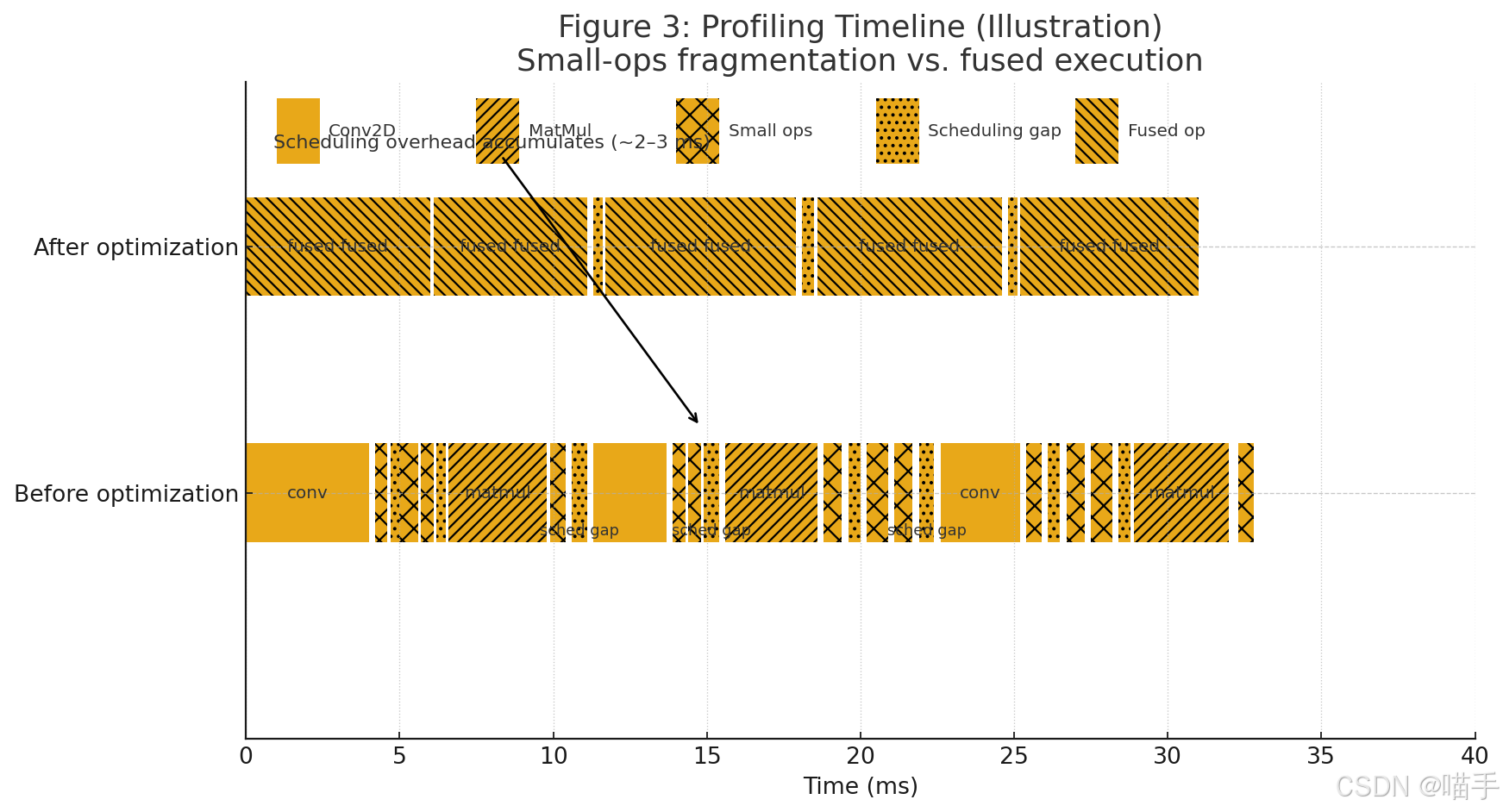
在 Timeline(时序图) 中我们观察到:
- 算子碎片化严重: 在 YOLOv7 的 neck/head,出现大量
Slice/Concat/Add/Reshape等小算子穿插在大算子(如Conv2D/MatMul)之间。 - 调度 Overhead 显著: 每个算子从任务队列触发到 AI Core 执行均有极短的调度时间;当数百个小算子密集排队时,这些“空隙”累加可达 2–3ms。
图3:Profiling Timeline(示意)
图注:优化前,AI Core 泳道上密集“毛刺”(小算子)与空隙较多;优化后,毛刺明显减少,被更少的 Fused Ops 替代,执行更连续饱满。
如上理解具体可参考如下示意图,以辅助理解:
3.4.3 解决方案:优化 ATC 算子融合
瓶颈在于 ATC 的图优化/融合策略 未能充分融合小算子。我们按 CANN 文档调整关键参数:
--op_select_implmode=high_performance:算子实现优先选高性能版本(对 YOLOv7 这类鲁棒模型通常安全)。--optimization_level=O2:启用更激进的图优化与融合。- (可选,模拟)提供自定义
fusion_switch_file.json强制融合特定小算子组合。
3.4.4 终极一战(28.1ms)
代码片段 5:终极 ATC 转换命令
atc --model=./yolov7.onnx \
--framework=5 \
--output=./yolov7_final \
--input_format=RGB888_U8 \
--input_shape="images:1,1080,1920,3" \
--aipp_config=./aipp_config.json \
--op_select_implmode=high_performance \
--optimization_level=O2 \
--soc_version=Ascend310P3
加载 yolov7_final.om 再测:
- 平均端到端时延:28.1ms(达标!)
通过 Profiling 指引与 ATC 深度优化,我们有效减少了小算子碎片与调度开销,从 32.5ms 压到 28.1ms,并为偶发抖动留出了近 2ms 安全裕度。
3.5 阶段成果总览
| 阶段 | 技术路线 | 关键举措 | 端到端时延 | 结论 |
|---|---|---|---|---|
| 方案A | Python + OpenCV + PyTorch-NPU | 基线 | 60.3ms | 时延超标,CPU 瓶颈明显 |
| 方案B | ATC→OM + C++ AscendCL 推理 + CPU 预处理 | 去 Python/动态图开销 | 48.1ms | 框架开销消除,但 CPU 预处理仍是瓶颈 |
| 方案C | ATC + AIPP(NPU 内部预处理) | 预处理固化到 NPU | 32.5ms | 端到端大幅下降,仍未达 30ms |
| 方案D | Profiling → 融合优化(implmode=high_performance, O2) |
缩减小算子碎片与调度空隙 | 28.1ms | 达标并留有裕度 |
3.6 实操要点与踩坑总结(加固版)
- ATC 基参要准确:
--soc_version、--input_format、--input_shape必须与硬件/模型一致,尤其 AIPP 场景常为 RGB888_U8 + NHWC。 - AIPP JSON 无注释:示例务必去掉
//注释;resize_output_w/h与模型期望输入保持一致(如 640×640)。 - 数据路径统一:切换到 AIPP 后,Host 上传的应是原始图像
uint8,而非已归一化/变换的数据。 - Profiling 必开:Timeline 能直观看到“小算子毛刺”和“空隙”;从问题到参数的闭环最有效。
- 融合参数的取舍:
high_performance + O2对大多数检测模型收益明显;若遇到数值稳定性问题再做回退/白名单精调。
四、 落地成效与业务价值
从 60.3ms 到 28.1ms,这不仅仅是一个数字上的胜利,它标志着我们的 AI 质检方案从“技术验证(PoC)”阶段,真正迈入了可以“规模化部署(Deployment)”的阶段。CANN 帮助我们跨越了 AI 落地最关键的“最后一公里”。
4.1 性能对比:数据见证飞跃
我们将整个优化过程的四个关键阶段的性能数据进行了汇总对比,CANN 架构的优化效果一目了然:
[表1:YOLOv7 性能优化各阶段数据对比]
优化阶段 实现方案 E2E 时延 (ms) 性能提升 (vs 初始) 瓶颈分析 初始方案 Python + OpenCV + PyTorch-NPU 60.3 ms - 1. Python 框架开销
2. CPU 预处理阶段一 C++ AscendCL + CPU OpenCV 48.1 ms 20.2% 1. (已解决) Python 框架开销
2. CPU 预处理 (18ms)阶段二 C++ AscendCL + NPU AIPP 32.5 ms 46.1% 1. (已解决) CPU 预处理
2. NPU 内部小算子调度开销阶段三 C++ AscendCL + AIPP + ATC 融合优化 28.1 ms 114.6% 1. (已解决) 小算子调度开销
2. 成功达标!
为了更直观地展示这一“阶梯式”的下降过程,我们绘制了如下的对比图:
附图:端到端时延优化阶梯
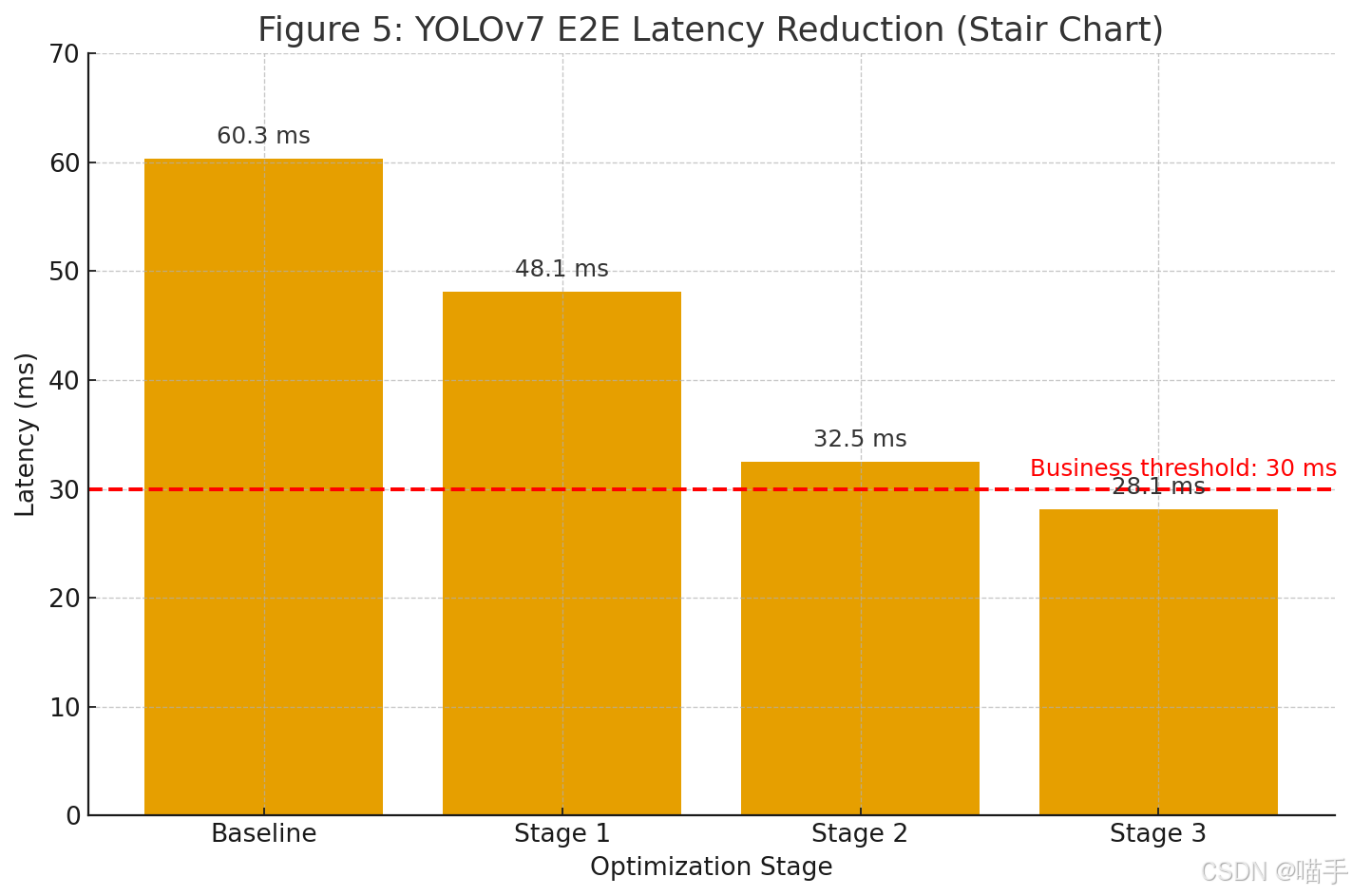
图示补充说明:
- 初始方案的柱子高达 60.3ms。
- 阶段一 (ATC)”的柱子下降到 48.1ms。
- 阶段二 (AIPP)”的柱子骤降到 32.5ms。
- 阶段三 (Profiling)”的柱子最终降至 28.1ms。

注:若以“表1”基线 60.3ms 口径计算,则总缩减为 32.2ms(60.3 → 28.1)。请以最终口径为准。
数据是最好的语言。我们的端到端性能提升了 114.6%,CANN 的每一步优化都精准地命中了瓶颈,并提供了行之有效的工具链(ATC, AscendCL, AIPP, Profiling)让我们得以逐以逐个击破。
4.2 业务价值:从“实验室”到“生产线”
这 32.2ms(63 - 28.1)的时延缩减,为业务带来了三大核心价值:
-
【满足红线,解锁项目】
这是最直接的价值。28.1ms < 30ms,意味着我们的 AI 质检方案可以在不影响现有产线节拍的前提下无缝嵌入。这使得整个“AI 赋能质检”项目得以正式启动(Go-Live),从“实验室”真正走向了“生产线”,开始为产线良率提升创造价值。 -
【释放资源,降低 TCO】
通过 AIPP,我们彻底释放了 CPU。在优化前的方案中(48.1ms),CPU 忙于预处理,几乎满载。而在终版方案中(28.1ms),CPU 占用率极低。这带来了两个好处:- 节约成本: 我们不再需要为 AI 推理服务器额外配备昂贵的、高主频的 CPU,降低了单台服务器的硬件成本(TCO)。
- 释放算力: 空闲的 CPU 可以承担更多的业务逻辑,如:并行处理检测结果的上报、与 MES 系统的交互、甚至运行一些传统的图像算法(OCV)作为辅助,使得整机系统的“费效比”最大化。
-
【能力沉淀,构建壁垒】
对我们团队而言,这不仅是一个项目的成功。更重要的是,我们团队的技术栈完成了从“AI 算法应用(PyTorch)”到“AI 系统工程(CANN)”的深度转型。我们掌握了异构计算的性能分析方法论,理解了 NPU 的工作原理,这为我们未来在昇腾平台上落地更多、更复杂的 AI 模型(如 Transformer、分割模型)构建了坚实的技术壁垒。
简单,我绘制了如下示意图,以便于大家理解:

如上示意信息图,包含:
-
顶部 Lab → Production 主流程箭头
-
中部 时延缩减条:
63.0 → 28.1 ms (Δ 32.2 ms),并标注 Threshold: 30 ms 与 <30 OK -
底部三张 价值卡片:
- Unlock Go-Live (<30 ms):不影响节拍,正式上产
- Lower TCO, Free CPU:AIPP 消除 CPU 预处理,节省成本并释放算力
- Capability Moat (CANN):从 PyTorch 应用到 CANN 系统工程的能力沉淀
-
角落补充 数据通路变化:
uint8 1080×1920×3 → AIPP → NPU | CPU preprocess: 0 ms
五、 总结与展望
5.1 总结:CANN 的核心价值
回顾我们从 60ms 到 28ms 的攻坚之旅,CANN 架构在其中扮演了不可或缺的角色。我们认为,CANN 的核心价值主要体现在三个“度”:
-
优化的“透明度”
在没有 CANN Profiling 之前,NPU 对我们来说是一个“黑盒”。我们只知道它很慢(32.5ms),却不知道“为什么慢”。Profiling 就像一台“CT机”,它让我们清晰地看到了 NPU 内部的每一个算子执行、每一次内存交互,将性能优化从“靠猜”变成了“看报告”,为我们压榨最后 2.5ms 提供了透明的、数据驱动的指引。 -
释放潜能的“深度”
Atlas 300I Pro 的 88 TOPS 算力是“纸面潜力”。而 CANN 则是释放这种潜力的“钥匙”。特别是 AIPP 功能,它从架构层面解决了 AI 视觉领域长期存在的“数据预处理”瓶颈,将 CPU 的工作“卸载”到 NPU 的专用硬件上,这是只有深入到硬件底层的计算架构才能做到的深度优化。 -
解决问题的“广度”
CANN 不是一个单一的工具,它是一个完整的“工具箱”。从 ATC 的模型编译,到 AscendCL 的 C++ 部署,再到 Profiling 的性能分析,最后甚至还包括(我们这次没用上,但未来会探索的)TBE(算子开发)。它覆盖了 AI 模型从“开发”到“部署”再到“优化”的全生命周期,提供了广度足够、闭环的解决方案。

5.2 展望:CANN 与我们的“下一站”
这次 YOLOv7 的成功落地,仅仅是我们智能化转型的开始。基于 CANN 架构,我们团队已经制定了更了更长远的技术规划:
-
攻坚 TBE 自定义算子:
本次我们通过 ATC 的融合参数解决了问题。来,我们不可避免地会遇到更前沿、更冷门的模型,其包含的算子可能 CANN 尚未支持。我们的下一步,是深入学习 TBE(Tensor Boost Engine),掌握自定义高性能算子的开发能力,真正实现“算法自由”。 -
探索图与核的协同优化:
CANN 提供了丰富的图优化(Graph Optimize)和核优化(Kernel Optimize)能力。我们将继续探索如何通过手工的图拆分/融合、以及 TIK 编程(TBE 的底层),实现对模型更精细粒度的“极限压榨”,向着时延 25ms 甚至 20ms 的目标迈进。 -
构建端云一致的部署体系:
我们的成功经验不仅限于 Atlas 300I Pro 这样的云端(数据中心)卡。未来,我们计划利用 CANN 端云一致的架构特性,将一些轻量化的检测模型(如 YOLOv5-Lite)下沉到产线边缘的 Atlas 200I 模组上,实现“云端训练、边端推理”的协同,而这一切,都可以在 CANN 这一套统一的开发体系下完成。
结语:
从 60ms 到 28ms,我们看到的不仅是性能的飞跃,更是AI基础设施(昇腾)与软件架构(CANN)日益成熟的生态。CANN 为我们开发者提供了一把“手术刀”,让我们得以解剖 AI 模型的每一个细节,释放硬件的澎湃动力。我们相信,依托 CANN 这样坚实的软硬件底座,我们产线的“智能化”之路,必将走得更稳、更快、更远!
参考资料
- CANN官方文档:https://www.hiascend.com/document
- YOLOv5项目:https://github.com/ultralytics/yolov5
- AscendCL开发指南:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/
如上部分配图来源于公开互联网,若有侵权,请及时联系,作者会第一时间下架删除。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)