华为盘古 Ultra-MoE-718B-V1.1 开源:千亿级模型终于“用得起“了
华为盘古 Ultra-MoE-718B-V1.1 开源:千亿级模型终于"用得起"了
华为盘古 Ultra-MoE-718B-V1.1 开源:千亿级模型终于"用得起"了
前言
一直觉得千亿级模型离普通开发者太远,想用用不起、想跑跑不动,真正能落在项目里的更是寥寥无几。但这次华为把盘古 Ultra-MoE-718B-V1.1 直接开源出来,体验下来最大的感受是:千亿级模型终于不再是 “望而却步” 的存在了。V1.1 在通用、数学、代码、Agent 调用等关键能力上都肉眼可见地升级,快思考变得更聪明,慢思考更稳更准,幻觉率也压得很低。用一句话总结:它不再只是能跑起来,而是能真正跑进实际场景。对我来说,这更像是国产大模型第一次把可用和可落地做到同等重要的一次升级。
开源信息:现在就能动手体验
核心信息:
- 模型名称:openPangu-Ultra-MoE-718B-V1.1
- 训练平台:基于昇腾NPU
- 关键特性:快慢思考双模式,工具调用能力提升
- 量化版本:V1.1-Int8,显存占用减半,吞吐提升20%,精度损失<1%
- 推理支持:开源Omni-Infer引擎,支持Function Call
感觉最大的变化不是体量更大,而是变得好用。模型基于昇腾 NPU 训练,推理时可以在快思考和慢思考之间自由切换,简单任务跑得更快,复杂任务也能沉住气推理清楚。Int8 量化版本也给力,显存直接减半、吞吐还能往上提,精度几乎没掉多少,真正适合开发者拿来本地折腾。再加上支持 Function Call 的 Omni-Infer 推理引擎,把部署成本和使用门槛都压得更低,千亿模型第一次有了随便跑跑看的感觉。
性能实测:数据说话,不做虚的
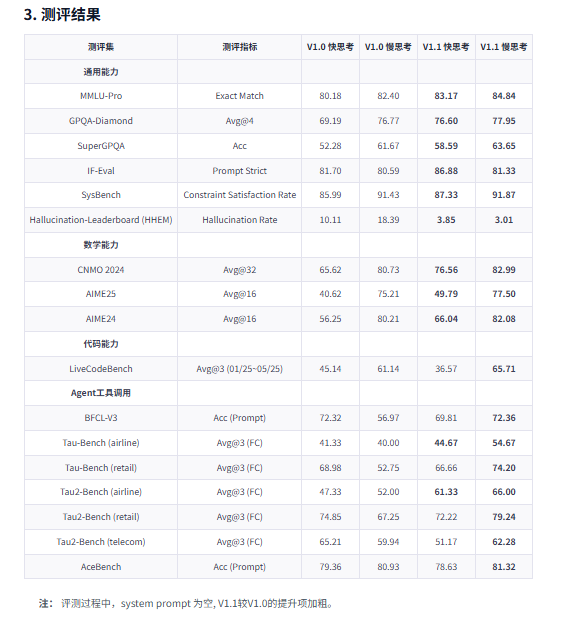
抗幻觉能力 – 革命性提升
- 快思考模式:幻觉率从 10.11% 降至 3.85%(降幅达 61%)
- 慢思考模式:幻觉率从 18.39% 降至 3.01%(行业顶尖水平)
- 实际价值:输出可靠性大幅提升,显著降低人工校验与纠错成本
数学能力 – 全面加强
快思考提升显著
- CNMO 2024:65.62 → 76.56(提升 16.7%)
- AIME25:40.62 → 49.79(提升 22.6%)
- AIME24:56.25 → 66.04(提升 17.4%)
慢思考持续领先
- AIME24 已达 82.08 分,接近顶尖水平
实际价值:日常计算与专业数学任务能力双双增强
工具调用 – 精度大幅优化
慢思考关键任务大幅提升
- BFCL-V3:56.97 → 72.36(提升 27%)
- Tau-Bench(航空):40.00 → 54.67(提升 36.7%)
- Tau-Bench(零售):52.75 → 74.20(提升 40.7%)
- 实际价值:复杂业务场景下的工具选择与调用准确率显著提高
通用能力 – 稳步优化
- MMLU-Pro(快思考):80.18 → 83.17
- IF-Eval(快思考):81.70 → 86.88(指令遵循能力更强)
- 系统约束满足率持续保持 **91%**以上高水平
版本升级:V1.1到底强在哪里?

V1.1版本的核心策略是:慢思考全面升级,快思考重点优化。
具体提升:
- 通用能力:快思考81.0→慢思考82.5(V1.0:77.5→80.4)
- 数学能力:快思考从54.1跃升至64.1,解决了简单数学问题
- 代码能力:慢思考从61.1提升到65.7,复杂代码任务更靠谱
- 工具调用:慢思考从55.8大幅升至68.0,复杂场景调用精准度显著提升
开发者视角:V1.0时还得在效率和精度间纠结,V1.1直接把快思考能力拉到了接近旧版慢思考的水平。
场景化能力:不同任务,不同模式
版本跃迁:V1.1 如何实现能力全面突破

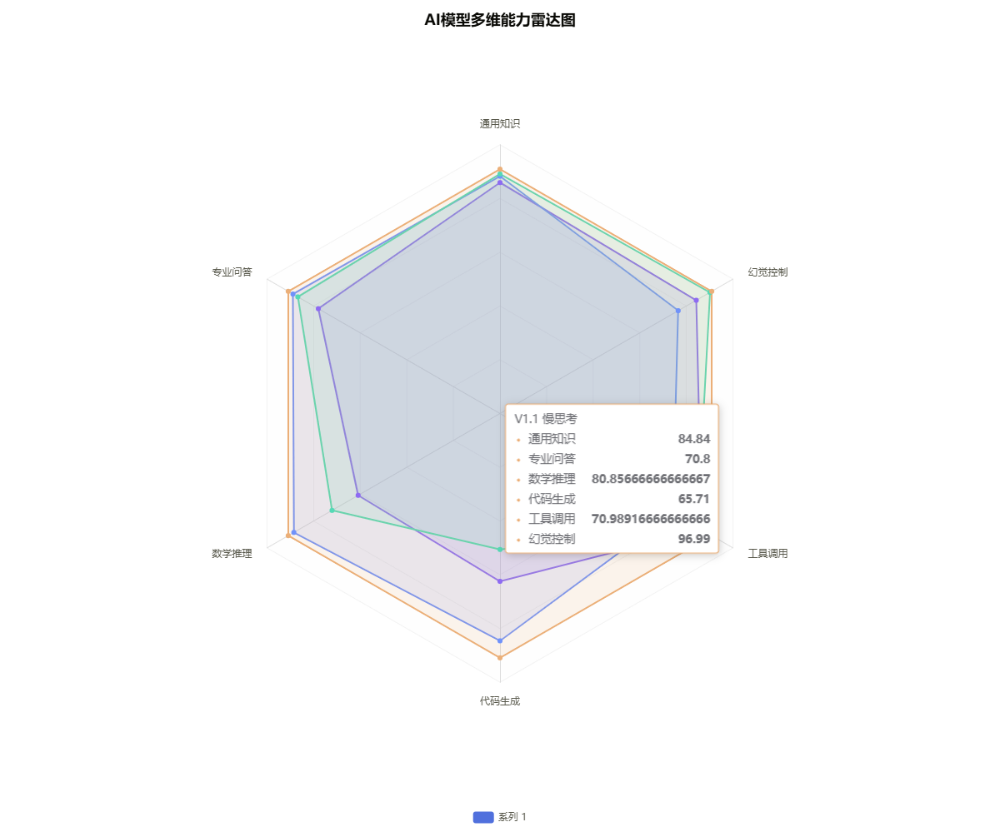
盘古 Ultra-MoE 模型 V1.0 到 V1.1 的能力迭代:V1.1 整体呈现 “慢思考全面升级、快思考重点优化” 的特点 ,通用、数学能力的快慢模式均有提升,尤其是数学快思考从 54.1 跃至 64.1;Agent 工具调用的慢思考更是从 55.8 大幅涨到 68.0,补上了 V1.0 的短板;仅代码快思考略有下降,但慢思考代码能力从 61.1 升至 65.7,能看出版本迭代更侧重强化慢模式的深度任务能力,同时巩固快模式的核心基础表现,让不同场景的开发需求都能得到更好适配
- 通用能力:V1.1 双模式得分都比 V1.0 高,快思考从 77.5 提升到 81.0,慢思考从 80.4 提升到 82.5,整体能力越来越扎实
- 数学能力:V1.1 的数学能力进步超亮眼,快思考从 54.1 升到 64.1,提升幅度特别大,再也不用为简单数学问题纠结;慢思考从 78.7 升到 80.8,稳步优化,复杂计算也更靠谱
- 代码能力:V1.1 的代码能力有点两极分化,快思考从 45.1 降到 36.6,确实有点小遗憾;但慢思考从 61.1 升到 65.7,慢模式下写代码、查 bug 的能力明显变强,复杂代码需求完全能 hold 住
- Agent 工具调用:V1.1 的工具调用能力进步超惊喜,快思考从 61.7 小幅提升到 62.6,日常简单工具使用更流畅;慢思考从 55.8 大幅升到 68.0,显著增强,复杂场景下选工具、用工具的精准度高了很多,省了不少手动操作的麻烦
通用能力:从基础理解到精准执行
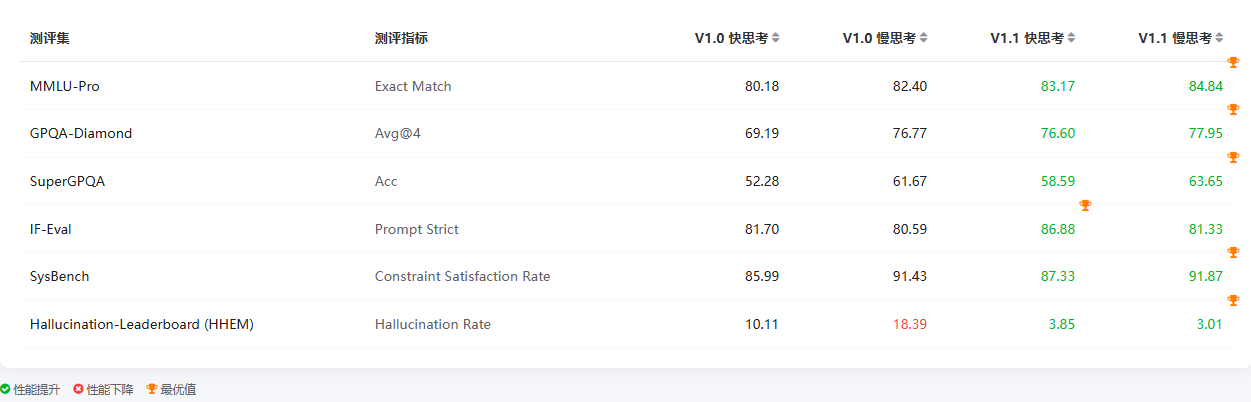
从开发者视角看盘古 Ultra-MoE-718B V1.1 的通用能力升级,非常省心高效,V1.0 快思考虽快但能力差点意思,慢思考能力够却幻觉让人头大,调参数平衡效率和可靠性得花费不少时间,现在 V1.1 直接把快思考的实力拉到接近旧版慢思考,幻觉还砍到 3% 级,指令遵循也更加稳,精准踩中了实际落地时 既要快又要准的痛点,省了适配成本,也能够减小线上部署后的纠错运维压力,属于是把开发者的刚需给直接焊死在新版本里了
数学推理能力:快慢思考双模式
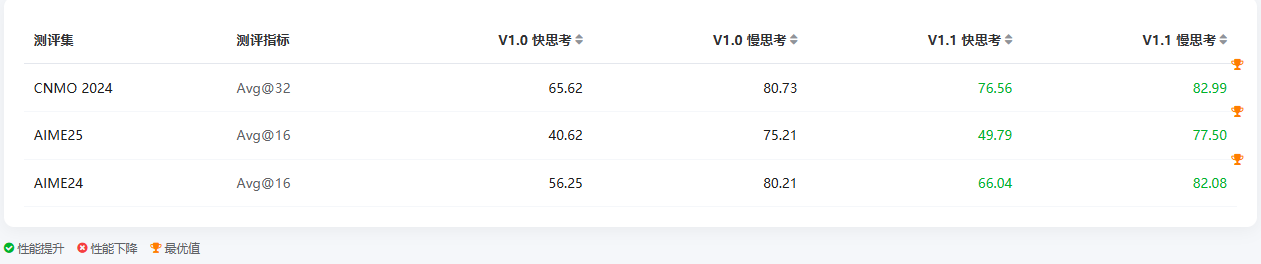
盘古 Ultra-MoE V1.1 在数学任务上实现了显著升级:快慢思考模式以及在 CNMO 2024、AIME25、AIME24 三大测评集中的得分均高于 V1.0 版本,快思考模式的提升尤为突出,比如 AIME25 从 40.62 涨到 49.79、AIME24 从 56.25 升至 66.04,基本补上了 V1.0 快思考在数学能力上的短板,慢思考模式则在高基础上持续优化,AIME25、AIME24 等任务的得分都进一步逼近顶尖水平,其中 AIME24 更是拿下了 82.08 的最优值。
整体来看,V1.1 既强化了慢思考的深度数学推理能力,也让快思考的数学表现更实用,覆盖了不同场景下的数学需求。
代码生成能力:深度开发与轻量交互

代码能力测评显示,盘古 Ultra-MoE V1.1 在代码任务上呈现 “慢思考强化、快思考取舍” 的特点:V1.1 慢思考在 LiveCodeBench 的得分从 V1.0 的 61.14 提升至 65.71,实现了代码能力的优化并拿下最优值;但快思考得分从 45.14 降至 36.57,出现明显下滑。
说明 V1.1 版本更侧重强化慢思考模式的深度代码能力,而对快思考模式的代码表现做了策略性调整,适配了不同场景下 “深度代码开发” 与 “轻量代码交互” 的不同需求。
Agent 调用能力:复杂任务调用精度
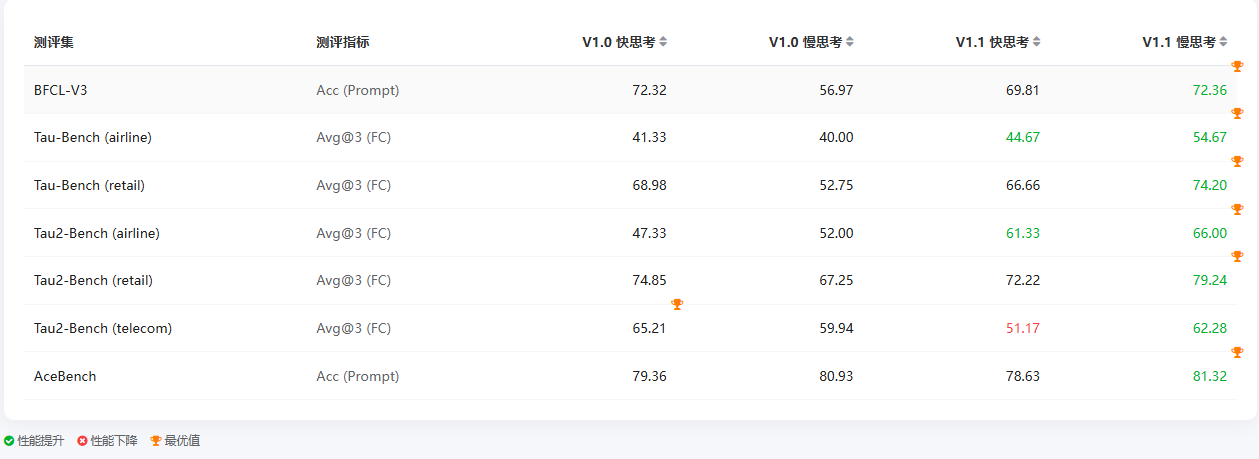
Agent 调用能力测评可以看出,盘古 Ultra-MoE V1.1 的核心升级聚焦于慢思考模式:在 BFCL-V3、Tau 系列(航空、零售、电信)、AceBench 等任务中,V1.1 慢思考的得分全面超越 V1.0(如 Tau-Bench 零售从 52.75 升至 74.20、Tau2-Bench 航空从 52.00 升至 66.00),多数任务还拿下了最优值,Agent 工具调用的适配性与精度显著提升。
快思考模式则呈现 “部分优化、个别微调” 的特点,Tau-Bench 航空等任务得分上升,但 BFCL-V3、Tau-Bench 电信等略有下降,整体仍保持稳定。说明 V1.1 版本重点强化了慢思考在复杂 Agent 场景下的调用能力,更适配需要精准工具协作的深度任务,同时维持了快思考的基础交互效率。
技术深度:为什么它这么高效?
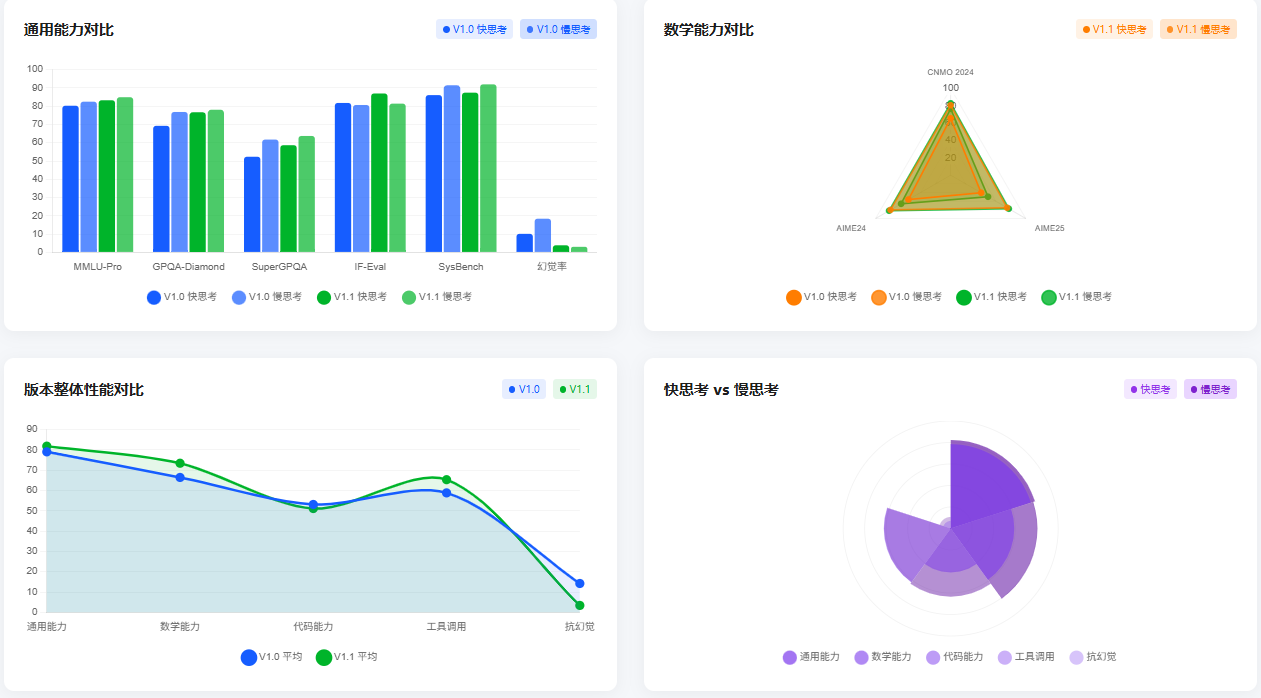
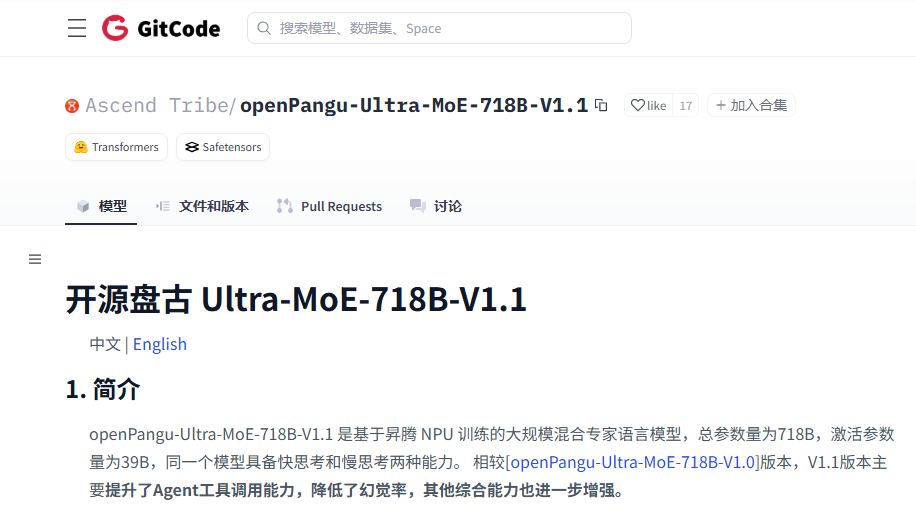
通用能力全面迭代:柱状图可以看出 V1.1 快慢思考在 MMLU-Pro、GPQA-Diamond 等任务中得分均高于 V1.0,尤其幻觉率大幅下降,通用能力的均衡性与可靠性显著提升
数学能力更趋全面:雷达图中的 V1.1 的快慢思考覆盖范围(CNMO 2024、AIME24/25)均超过 V1.0,慢思考的数学综合表现更接近满分,快思考也补上了之前的短板
版本整体性能跃升:折线图 V1.1 在通用能力、数学能力、工具调用等维度的平均分全面超越 V1.0,只有代码能力略有波动,且抗幻觉能力提升最为突出
模式分工更清晰:饼图体现出快慢思考能力侧重差异,V1.1 强化了慢思考在深度任务(数学、工具调用)的表现,同时优化快思考的基础能力,适配不同场景需求
整体来看作为一线开发者,最直观的感受是 V1.1 不光实现了能力均衡性加场景适配性的双重升级,更像是把我们实际开发里既要又要的矛盾给理顺了:
V1.0 要么为了效率选快思考但核心任务性能不够用,要么为了精度选慢思考却得承担高资源成本,调参适配不同场景得反复试错
V1.1 既把核心任务的绝对性能提上去了,比如数学、Agent 调用的慢思考得分肉眼可见地涨,又把快、慢思考的分工磨得更贴合实际需求,快思考能顶起日常交互的效率,慢思考能扛住复杂推理的精度,甚至幻觉率这种线上运维的老大难都压到了 3% 级
最后:这波开源意味着什么?
盘古 Ultra-MoE-718B-V1.1 的开源,像是把千亿级模型真正推到了普通开发者能触碰的范围内:模型能力够强,资源门槛又被量化版大幅压低,再加上 Omni-Infer 这种能直接拿来跑的推理引擎,让大模型第一次从"只能看看论文"变成"随时能跑两下试试"。对国内开发者来说,它不仅是一个强力模型,更是一整套能落到业务、能跑在本地、能被工具化、插件化的 AI 基建。这波开源的意义就在于,大模型不再只属于大厂,而是开始真正进入每一个开发者的工作流里。
立即体验:

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 185
185 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)