Ascend C编程基础与核函数开发核心知识点梳理
简单说,它就是被__global__修饰的函数,是CPU调用NPU计算的入口。// 这里的代码在AI Core上跑如果你问我,参加第二季CANN训练营最大的收获是什么?我觉得不是具体的某个API用法(那个查文档就有),而是建立了一套完整的异构计算编程思维。当你能脑补出数据在Global Memory和Unified Buffer之间流动的轨迹时,你就真正入门了。现在的课程刚刚讲到Vector算子和
前言:从“调包侠”到“造轮子”的跨越
说实话,报名CANN训练营第二季之前,我犹豫了一下。作为平时习惯了PyTorch/TensorFlow一把梭的“调包侠”,去啃底层的C++算子开发,是不是有点自讨苦吃?
但这一周的课程刷下来,尤其是啃完**“Ascend C编程基础”和“核函数开发”**这两块硬骨头后,我真香了。这种感觉就像是你开惯了自动挡的车,突然学会了手动挡弹射起步——你对硬件的掌控感变强了。
今天不聊虚的,就结合我这两天熬夜肝出来的笔记,把Ascend C最核心的编程范式和核函数开发逻辑给盘清楚。如果你也想入坑,这篇笔记或许能帮你省下翻官方文档的半天时间。
一、 初入营体验:这不是“念PPT”的培训
先说体验。本来以为是那种枯燥的文档朗读课,结果发现这次训练营非常侧重工程思维。
最大的冲击点在于思维转换:
以前写CPU代码,想怎么访问内存就怎么访问。
但在昇腾NPU上,你必须时刻以此为准则:“数据搬运是昂贵的,计算是廉价的”。所有的代码逻辑,其实都是在为“掩盖数据搬运时间”而服务。
二、 Ascend C的核心架构:Host与Device的分离
在写第一行代码前,必须搞懂Host和Device。
- Host侧(CPU): 像是“指挥部”。负责复杂的逻辑判断、预处理,以及最重要的——Tiling(切分策略)计算。
- Device侧(NPU): 像是“前线火力”。负责执行具体的核函数(Kernel Function),进行高强度的矩阵或向量运算。
我在做作业时踩的第一个坑,就是混淆了这两者的代码。记住:核函数是运行在Device上的,你不能在核函数里调用 std::cout 或者 printf(虽然有调试用的打印接口,但逻辑上是不通的)。
三、 核函数(Kernel Function)开发:代码的灵魂
对应课程表里**“核函数开发方式介绍”**这一节。这是Ascend C最性感的地方。
3.1 什么是核函数?
简单说,它就是被__global__修饰的函数,是CPU调用NPU计算的入口。
extern "C" __global__ __aicore__ void add_custom(...) {
// 这里的代码在AI Core上跑
}
3.2 SPMD模型(单程序多数据)
这是理解Ascend C并行计算的钥匙。
我的理解是: 你只需要写一份代码(比如“把数组A和数组B相加”),然后NPU上有多少个核(AI Core),系统就会启动多少个实例去运行这份代码。
关键点: 每个核怎么知道自己该算哪部分数据?
靠 GetBlockIdx()。
比如我有8个核,数据有800个。
- 0号核:
GetBlockIdx()返回0,处理 0-99。 - 1号核:
GetBlockIdx()返回1,处理 100-199。
…以此类推。

四、 编程范式:流水线设计的艺术
这是我在课程里学到的最硬核的“招式”。对应图4中**“从0到1掌握Ascend C算子工程开发”**。
Ascend C推荐的标准编程范式是类的封装:
- Init(初始化):分配内存,获取Tiling参数。
- Process(执行主逻辑):核心流水线。
4.1 为什么要有CopyIn -> Compute -> CopyOut?
初学者最容易问:为什么不能直接算?非要搬来搬去?
因为AI Core只认Unified Buffer (UB)!
- GM (Global Memory): 显存,大但慢。
- UB (Unified Buffer): 片上高速缓存,快但小。
标准动作:
- CopyIn: 把数据从GM搬到UB。(搬运工)
- Compute: 在UB里进行加减乘除。(计算工)
- CopyOut: 把结果从UB搬回GM。(搬运工)
4.2 进阶技巧:双缓冲(Double Buffer)
这节课听得我大呼过瘾。
如果是单缓冲,搬运的时候计算单元在发呆,计算的时候搬运单元在发呆。
双缓冲机制就是:在UB里开辟两块空间(Ping-Pong)。
- 当计算单元在算第1块数据时;
- 搬运单元已经在偷偷搬第2块数据进来了。
结果: 算力被榨干,性能拉满。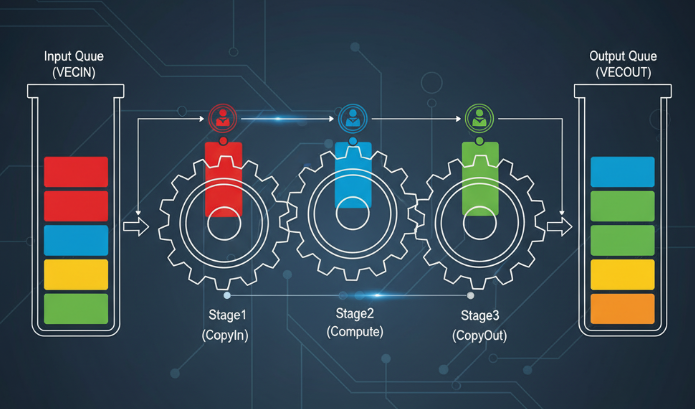
五、 避坑指南:那些年我报过的错
作为UGC分享,必须得说说我在实操中遇到的“红字”。
-
32字节对齐的痛
Ascend C对内存地址要求极高。我在定义Tensor时,如果Shape不是32字节的倍数,DataCopy指令经常会报错。
解决方式: 必须学会使用AlignUp等辅助函数,或者在Tiling阶段就处理好尾块(Tail Block)。 -
PipeBarrier(同步屏障)漏加
有一次我的结果全是0。排查了半天,发现是因为没加同步指令。数据还没CopyIn完成,Compute指令就执行了。
心得: 在每一个阶段切换时,一定要确认数据已经就位。 -
Host侧Tiling参数传错
Host侧算好的参数,传到Device侧如果是乱码,多半是结构体字节对齐的问题,或者是数据类型不匹配(int32 vs int64)。
六、 总结与安利
如果你问我,参加第二季CANN训练营最大的收获是什么?
我觉得不是具体的某个API用法(那个查文档就有),而是建立了一套完整的异构计算编程思维。
当你能脑补出数据在Global Memory和Unified Buffer之间流动的轨迹时,你就真正入门了。
现在的课程刚刚讲到Vector算子和基础架构,后面还有Matmul、算子融合等高阶内容(如图3、图1所示)。这趟车,现在的速度刚刚好。
如果你也想从源码级别理解AI模型,别犹豫,赶紧上车。咱们群里见!
🔥 2025昇腾CANN训练营·第二季 报名开启!
别让你的AI模型只跑在黑盒子里,来这里,亲手拆解它!
👇 扫码/点击链接,硬核玩家速来集合:
https://www.hiascend.com/developer/activities/cann20252

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 17
17 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)