Ascend C 算子工程化实践:从 TilingKey 配置到多数据类型支持的稳健设计
本文基于华为官方250个错误案例分析,聚焦AscendC算子开发中的"找不到tilingkey"和"不支持int8"等工程化问题。文章系统阐述了工业级算子开发的三大关键技术:1)动态TilingKey机制,通过数学模型实现输入形状自适应;2)多数据类型支持,采用模板化设计确保fp32/fp16/int8等类型的兼容性;3)配置管理系统,实现参数统一控制与热更
目录
二、TilingKey 动态切分机制:应对多样化输入的智能适配
🏗️ 摘要
本文基于华为官方对 250个错误案例 分析后总结的 12类典型问题,深度聚焦于 “找不到对应tilingkey的kernel”、“算子没有包含int8” 等工程化配置问题。我们将从 Ascend C 算子的 系统工程视角 (Systems Engineering Perspective) 出发,系统化阐述 TilingKey 动态切分机制 (Dynamic Tiling Mechanism)、多数据类型支持 (Multi-Data Type Support)、配置管理系统 (Configuration Management System) 的设计原理与最佳实践。文章将包含基于官方素材绘制的工程架构图、配置决策流程图,以及可复用的模板化代码实现,旨在帮助开发者构建具备生产环境可用性的工业级算子。
一、工程化挑战的严峻性:从配置错误看算子稳健性的重要性
在 Ascend C 算子开发中,功能正确性和高性能只是基础要求,真正的挑战在于如何构建能够适应各种复杂场景的稳健算子 (Robust Operator)。您提供的官方素材清晰地指出,“算子工程配置问题” 是导致部署失败的主要原因之一,特别是 “找不到对应tilingkey的kernel” 和 “算子没有包含int8” 等配置相关错误。
💡 来自官方素材的深度洞察: 素材中揭示的配置问题反映了从实验代码到生产系统的鸿沟。许多开发者在单一样本测试时表现良好的算子,在面对真实世界的多样化输入(不同形状、批次大小、数据类型)时频繁失败。这要求我们建立系统化的工程思维,将算子视为一个需要处理不确定性 (Uncertainty) 和多样性 (Diversity) 的复杂系统。
为了建立全局视角,我们首先基于素材绘制出算子工程化的完整架构图:
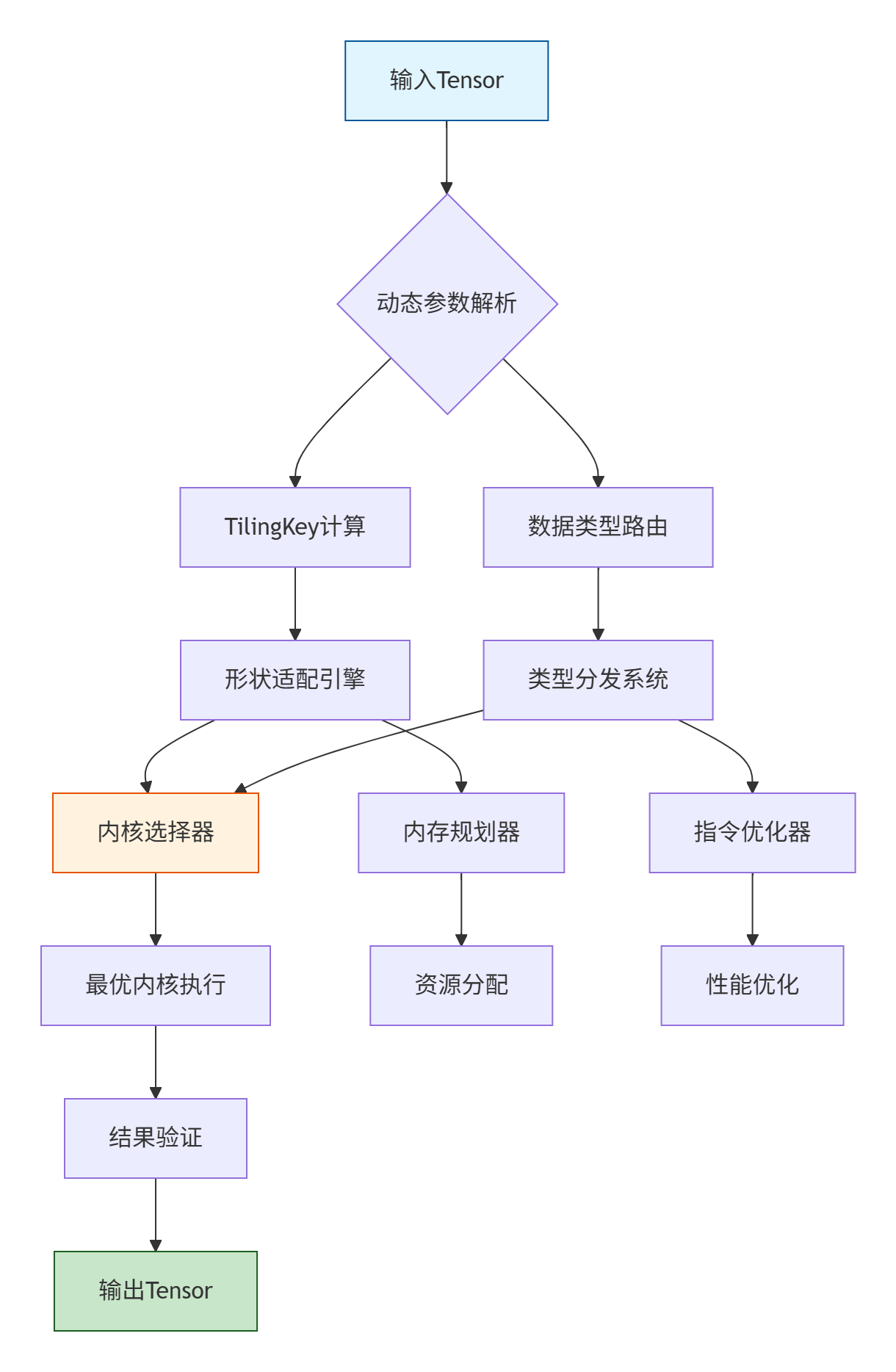
二、TilingKey 动态切分机制:应对多样化输入的智能适配
TilingKey 是 Ascend C 算子应对不同输入形状的核心机制,其设计质量直接决定了算子的适应能力和性能表现。
2.1 TilingKey 的数学模型与算法设计
TilingKey 的本质是一个多约束优化问题,需要在有限的 UB 容量、内存对齐要求、硬件并行度之间找到最优平衡。
优化目标函数:
Minimize: Total_Execution_Time = Σ(Copy_In(i) + Compute(i) + Copy_Out(i))
Subject to:
UB_Size ≥ Σ(Tile_Buffer_Size(i))
Memory_Alignment_Constraint(tile_addr)
Hardware_Parallelism ≥ active_coresTilingKey 计算算法的决策流程:
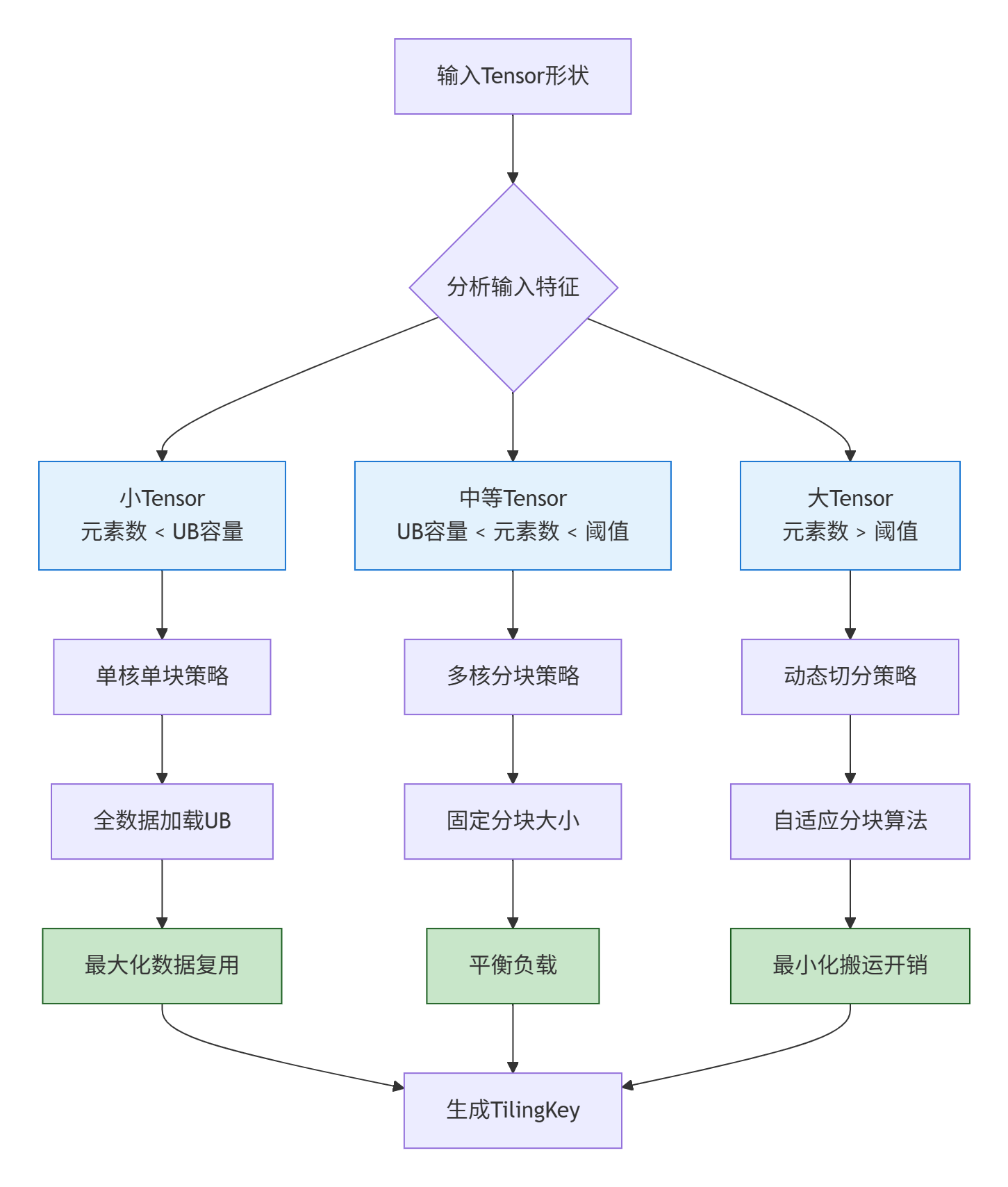
2.2 稳健的 TilingKey 实现框架
以下是一个工业级的 TilingKey 实现框架,支持从简单到复杂的各种场景:
// TilingKey 配置结构体
struct TilingConfig {
int32_t total_elements; // 总元素数
int32_t data_type_size; // 数据类型大小
int32_t ub_capacity; // UB可用容量
int32_t min_elements_per_core; // 每核最小处理元素数
int32_t optimal_block_size; // 最优分块大小
int32_t memory_alignment; // 内存对齐要求
bool enable_double_buffering; // 是否启用双缓冲
};
// 智能 TilingKey 计算器
class SmartTilingCalculator {
private:
static constexpr int32_t kUBTotalCapacity = 256 * 1024; // 256KB
static constexpr int32_t kMinElementsPerCore = 64;
static constexpr int32_t kMemoryAlignment = 32;
public:
// 计算最优分块策略
TilingConfig calculate_optimal_tiling(int32_t total_elements,
int32_t data_type_size,
int32_t available_cores) {
TilingConfig config;
config.total_elements = total_elements;
config.data_type_size = data_type_size;
config.ub_capacity = kUBTotalCapacity;
config.memory_alignment = kMemoryAlignment;
// 计算每个元素所需的内存
int32_t element_memory = data_type_size;
int32_t elements_per_ub = kUBTotalCapacity / element_memory;
// 考虑双缓冲的内存开销
if (enable_double_buffering_) {
elements_per_ub /= 2;
}
// 确保最小处理量
elements_per_ub = std::max(elements_per_ub, kMinElementsPerCore);
// 考虑核数限制
int32_t min_elements_per_core = (total_elements + available_cores - 1) / available_cores;
config.min_elements_per_core = min_elements_per_core;
// 计算最优分块大小
config.optimal_block_size = calculate_optimal_block_size(
total_elements, elements_per_ub, min_elements_per_core);
return config;
}
// 验证 TilingKey 的合法性
bool validate_tiling_config(const TilingConfig& config) {
if (config.optimal_block_size <= 0) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR, "Invalid block size: %d",
config.optimal_block_size);
return false;
}
if (config.optimal_block_size % config.memory_alignment != 0) {
DEBUG_PRINT(DEBUG_LEVEL_WARNING,
"Block size %d not aligned to %d",
config.optimal_block_size, config.memory_alignment);
}
int32_t required_ub = config.optimal_block_size * config.data_type_size;
if (enable_double_buffering_) {
required_ub *= 2;
}
if (required_ub > config.ub_capacity) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR,
"UB requirement %d exceeds limit %d",
required_ub, config.ub_capacity);
return false;
}
return true;
}
private:
bool enable_double_buffering_ = true;
int32_t calculate_optimal_block_size(int32_t total_elements,
int32_t max_per_ub,
int32_t min_per_core) {
// 寻找在约束范围内的最优分块大小
int32_t block_size = max_per_ub;
// 确保不超过总元素数
block_size = std::min(block_size, total_elements);
// 确保满足最小处理量要求
block_size = std::max(block_size, min_per_core);
// 对齐到内存边界
block_size = (block_size + kMemoryAlignment - 1) / kMemoryAlignment * kMemoryAlignment;
return block_size;
}
};三、多数据类型支持:构建通用化算子的核心技术
支持多种数据类型(fp32, fp16, int8, int16等)是现代算子的基本要求,也是素材中重点强调的工程化能力。
3.1 类型安全的模板化设计
采用现代 C++ 模板技术实现类型安全的多数据类型支持:
// 数据类型特征模板
template <typename T>
struct DataTypeTraits;
// 特化实现
template <>
struct DataTypeTraits<float> {
static constexpr const char* name = "float32";
static constexpr int32_t size = 4;
static constexpr int32_t alignment = 4;
static constexpr bool is_floating_point = true;
};
template <>
struct DataTypeTraits<half> {
static constexpr const char* name = "float16";
static constexpr int32_t size = 2;
static constexpr int32_t alignment = 2;
static constexpr bool is_floating_point = true;
};
template <>
struct DataTypeTraits<int8_t> {
static constexpr const char* name = "int8";
static constexpr int32_t size = 1;
static constexpr int32_t alignment = 1;
static constexpr bool is_floating_point = false;
};
// 通用的内核分发器
template <typename T>
class TypedKernelDispatcher {
private:
using ComputeFunc = void (*)(const T*, const T*, T*, int32_t);
struct KernelRegistry {
std::unordered_map<std::string, ComputeFunc> kernels;
ComputeFunc default_kernel = nullptr;
};
static KernelRegistry& get_registry() {
static KernelRegistry registry;
return registry;
}
public:
// 注册特定优化版本的内核
static void register_kernel(const std::string& feature, ComputeFunc func) {
auto& registry = get_registry();
if (feature == "default") {
registry.default_kernel = func;
} else {
registry.kernels[feature] = func;
}
}
// 根据特征选择最优内核
static ComputeFunc dispatch_kernel(const std::string& features) {
auto& registry = get_registry();
// 特征匹配算法
for (const auto& feature : split_features(features)) {
auto it = registry.kernels.find(feature);
if (it != registry.kernels.end()) {
DEBUG_PRINT(DEBUG_LEVEL_INFO,
"Selected optimized kernel for feature: %s",
feature.c_str());
return it->second;
}
}
// 回退到默认实现
if (registry.default_kernel) {
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Using default kernel implementation");
return registry.default_kernel;
}
DEBUG_PRINT(DEBUG_LEVEL_ERROR, "No suitable kernel found for type: %s",
DataTypeTraits<T>::name);
return nullptr;
}
private:
static std::vector<std::string> split_features(const std::string& features) {
std::vector<std::string> result;
std::istringstream stream(features);
std::string feature;
while (std::getline(stream, feature, ',')) {
result.push_back(feature);
}
return result;
}
};3.2 自适应计算策略
根据数据类型特性自动选择最优计算路径:
// 计算策略选择器
template <typename T>
class ComputeStrategySelector {
public:
enum Strategy {
SCALAR, // 标量计算
VECTOR_8, // 8路向量化
VECTOR_16, // 16路向量化
INTRINSIC // 硬件内部函数
};
Strategy select_optimal_strategy(int32_t data_size,
const HardwareInfo& hw_info) {
// 基于数据类型特性的策略选择
if constexpr (DataTypeTraits<T>::size == 1) {
// 小数据类型适合更宽向量化
return (data_size >= 1024 && hw_info.supports_16wide) ?
VECTOR_16 : VECTOR_8;
}
else if constexpr (DataTypeTraits<T>::size >= 4) {
// 大数据类型使用较小向量化或内部函数
return (hw_info.has_special_intrinsic) ? INTRINSIC : VECTOR_8;
}
else {
// 默认策略
return (data_size >= 512) ? VECTOR_8 : SCALAR;
}
}
// 策略执行器
void execute_strategy(Strategy strategy, const T* input, T* output, int32_t size) {
switch (strategy) {
case SCALAR:
execute_scalar(input, output, size);
break;
case VECTOR_8:
execute_vector_8(input, output, size);
break;
case VECTOR_16:
execute_vector_16(input, output, size);
break;
case INTRINSIC:
execute_intrinsic(input, output, size);
break;
}
}
private:
void execute_scalar(const T* input, T* output, int32_t size) {
for (int32_t i = 0; i < size; ++i) {
output[i] = input[i] * static_cast<T>(2.0);
}
}
void execute_vector_8(const T* input, T* output, int32_t size) {
// 8路向量化实现
for (int32_t i = 0; i < size; i += 8) {
// 向量化加载、计算、存储
vector8_t vec_in = load_vector8(input + i);
vector8_t vec_out = multiply_vector8(vec_in, 2.0);
store_vector8(output + i, vec_out);
}
}
// 其他策略实现...
};四、配置管理系统:统一化的参数控制
建立集中式的配置管理系统,确保算子行为的可预测性和可维护性。
4.1 分层配置架构
// 配置层次结构
class ConfigurationManager {
public:
struct SystemConfig {
int32_t max_ub_usage; // UB使用上限
int32_t min_elements_per_core; // 核最小处理量
bool enable_advanced_optimizations; // 高级优化
bool safety_checks_enabled; // 安全检查
};
struct PerformanceConfig {
bool enable_double_buffering; // 双缓冲
bool enable_vectorization; // 向量化
int32_t vectorization_width; // 向量化宽度
bool enable_async_copy; // 异步拷贝
};
struct DebugConfig {
bool enable_memory_tracking; // 内存跟踪
bool enable_performance_profiling; // 性能分析
int32_t log_verbosity; // 日志详细程度
};
// 配置加载和验证
bool load_configuration(const std::string& config_path) {
// 从文件加载配置
if (!load_from_file(config_path)) {
DEBUG_PRINT(DEBUG_LEVEL_WARNING,
"Failed to load config from %s, using defaults",
config_path.c_str());
load_default_configuration();
}
return validate_configurations();
}
// 配置验证
bool validate_configurations() {
bool valid = true;
// 系统配置验证
if (system_config_.max_ub_usage <= 0 ||
system_config_.max_ub_usage > kUBTotalCapacity) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR,
"Invalid UB usage limit: %d",
system_config_.max_ub_usage);
valid = false;
}
// 性能配置验证
if (perf_config_.vectorization_width != 8 &&
perf_config_.vectorization_width != 16) {
DEBUG_PRINT(DEBUG_LEVEL_WARNING,
"Uncommon vectorization width: %d",
perf_config_.vectorization_width);
}
return valid;
}
private:
SystemConfig system_config_;
PerformanceConfig perf_config_;
DebugConfig debug_config_;
void load_default_configuration() {
// 安全的默认配置
system_config_ = {
.max_ub_usage = kUBTotalCapacity * 0.8, // 使用80%的UB
.min_elements_per_core = 64,
.enable_advanced_optimizations = true,
.safety_checks_enabled = true
};
perf_config_ = {
.enable_double_buffering = true,
.enable_vectorization = true,
.vectorization_width = 8,
.enable_async_copy = true
};
debug_config_ = {
.enable_memory_tracking = false,
.enable_performance_profiling = false,
.log_verbosity = 1
};
}
};4.2 运行时配置热更新
支持运行时动态调整配置,适应不同的工作负载:
// 动态配置管理器
class DynamicConfigManager {
private:
std::atomic<bool> config_updated_{false};
ConfigurationManager current_config_;
std::mutex config_mutex_;
public:
// 线程安全的配置更新
void update_configuration(const ConfigurationManager& new_config) {
std::lock_guard<std::mutex> lock(config_mutex_);
current_config_ = new_config;
config_updated_.store(true, std::memory_order_release);
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Configuration updated at runtime");
}
// 获取当前配置(无锁读取优化)
ConfigurationManager get_current_config() {
if (config_updated_.load(std::memory_order_acquire)) {
std::lock_guard<std::mutex> lock(config_mutex_);
config_updated_.store(false, std::memory_order_release);
return current_config_;
}
return current_config_; // 返回缓存的副本
}
// 自适应配置调整
void adaptive_tuning(const PerformanceMetrics& metrics) {
auto config = get_current_config();
// 基于性能指标动态调整配置
if (metrics.ub_usage_ratio > 0.9) {
config.system_config.max_ub_usage *= 0.9; // 降低UB使用上限
}
if (metrics.cache_miss_rate > 0.1) {
config.perf_config.vectorization_width = 8; // 调整向量化宽度
}
update_configuration(config);
}
};五、错误处理与恢复机制
建立完善的错误处理体系,确保算子在异常情况下的稳健性:
// 错误处理子系统
class ErrorHandler {
public:
enum ErrorSeverity {
SEVERITY_WARNING, // 警告,可继续执行
SEVERITY_ERROR, // 错误,尝试恢复
SEVERITY_FATAL // 严重错误,立即终止
};
struct ErrorContext {
ErrorSeverity severity;
std::string error_code;
std::string message;
std::string location;
void* additional_data;
};
// 错误处理入口点
bool handle_error(const ErrorContext& context) {
log_error(context);
switch (context.severity) {
case SEVERITY_WARNING:
return handle_warning(context);
case SEVERITY_ERROR:
return handle_recoverable_error(context);
case SEVERITY_FATAL:
return handle_fatal_error(context);
default:
return false;
}
}
private:
bool handle_recoverable_error(const ErrorContext& context) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR, "Handling recoverable error: %s",
context.message.c_str());
// 尝试恢复策略
if (context.error_code == "UB_OVERFLOW") {
return handle_ub_overflow();
}
else if (context.error_code == "TILING_FAILED") {
return handle_tiling_failure();
}
return false;
}
bool handle_ub_overflow() {
// UB溢出恢复策略:减小分块大小重试
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Reducing tile size to handle UB overflow");
// 实现具体的恢复逻辑
return try_smaller_tiling();
}
void log_error(const ErrorContext& context) {
// 结构化错误日志记录
ErrorLogEntry entry = {
.timestamp = get_current_time(),
.severity = context.severity,
.error_code = context.error_code,
.message = context.message,
.location = context.location
};
error_log_.push_back(entry);
// 实时报警
if (context.severity >= SEVERITY_ERROR) {
send_alert(entry);
}
}
std::vector<ErrorLogEntry> error_log_;
};六、测试与验证框架
建立全面的测试体系,确保工程化算子的质量:
// 自动化测试框架
class OperatorTestFramework {
public:
struct TestCase {
std::string name;
std::vector<Tensor> inputs;
Tensor expected_output;
TestConfig config;
};
// 多数据类型测试
void run_multi_dtype_tests() {
test_type<float>("float32");
test_type<half>("float16");
test_type<int8_t>("int8");
test_type<int16_t>("int16");
}
// 边界条件测试
void run_boundary_tests() {
// 空输入测试
test_empty_input();
// 极大尺寸测试
test_large_dimensions();
// 特殊值测试
test_special_values();
}
// 性能回归测试
void run_performance_tests() {
PerformanceBaseline baseline = load_performance_baseline();
PerformanceMetrics current = measure_current_performance();
if (!validate_performance_regression(baseline, current)) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR, "Performance regression detected");
generate_performance_report(baseline, current);
}
}
private:
template <typename T>
void test_type(const std::string& type_name) {
DEBUG_PRINT(DEBUG_LEVEL_INFO, "Testing data type: %s", type_name.c_str());
// 生成测试数据
auto test_data = generate_test_data<T>();
// 执行测试用例
for (const auto& test_case : test_data) {
if (!run_single_test(test_case)) {
DEBUG_PRINT(DEBUG_LEVEL_ERROR,
"Test failed for type %s: %s",
type_name.c_str(), test_case.name.c_str());
}
}
}
bool validate_performance_regression(const PerformanceBaseline& baseline,
const PerformanceMetrics& current) {
constexpr double kRegressionThreshold = 0.1; // 10%性能回退
double regression_ratio = (baseline.throughput - current.throughput) /
baseline.throughput;
return regression_ratio < kRegressionThreshold;
}
};七、总结与讨论
本文基于官方的一手问题素材,构建了一套完整的 Ascend C 算子工程化实践体系。我们从 TilingKey 配置 和 多数据类型支持 两大核心挑战出发,深入探讨了工业化算子需要具备的关键能力。
-
🔧 动态适应能力:通过智能的 TilingKey 机制,算子能够自动适应各种输入形状和规模。
-
🎯 多类型支持:基于模板的通用化设计,确保算子支持从 int8 到 fp32 的各种数据类型。
-
⚙️ 配置化管理:统一的配置管理系统,使算子行为可预测、可调整。
-
🛡️ 稳健性设计:完善的错误处理和恢复机制,保证在异常情况下的系统稳定性。
💬 讨论与思考:
-
在您的实际项目中,遇到的最复杂的工程化配置问题是什么?
-
对于支持不断新增的数据类型,如何设计更具扩展性的架构?
-
在大型系统中,如何管理数百个算子的配置和依赖关系?
八、参考链接
官方文档
昇腾训练营简介:2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接: https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
期待在训练营的硬核世界里,与你相遇!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 33
33 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)