nano-vllm 项目分析报告
nano-vllm 是一个教学级轻量 vLLM 实现,仅用约 1200 行 Python 代码复现了工业级推理引擎的核心能力。项目在 RTX4070 上实现 1434 tok/s 的吞吐量,显存占用仅 3.8GB,启动时间缩短至 3 秒。核心架构包含 API 层、引擎层、内存层和模型层,实现了 PagedAttention、动态批处理和 FlashAttention 等关键技术。通过固定大小的 B
简述
项目地址
https://github.com/GeeeekExplorer/nano-vllm![]() https://github.com/GeeeekExplorer/nano-vllm核心定位: 教学级轻量 vLLM 实现,约 1,200 行 Python 代码复现工业级推理引擎核心能力
https://github.com/GeeeekExplorer/nano-vllm核心定位: 教学级轻量 vLLM 实现,约 1,200 行 Python 代码复现工业级推理引擎核心能力
|
维度 |
信息 |
|---|---|
|
⭐ Star |
12k+ |
|
🔧 Fork |
1.7k+ |
|
📦 代码量 |
~1,200 行 Python |
|
🚀 性能 |
与 vLLM 相当(RTX 4070 上吞吐量 1434 tok/s vs 1361 tok/s) |
|
🎯 适用场景 |
学习研究、小模型部署、边缘计算、快速原型验证 |
官方给出的测试结果 RTX 4070 Laptop, Qwen3-0.6B
|
指标 |
vLLM |
nano-vllm |
说明 |
|---|---|---|---|
|
🔹 吞吐量 |
1361.84 tok/s |
1434.13 tok/s |
nano 略优,精简流水线减少 overhead |
|
🔹 显存占用 |
~4.2 GB |
~3.8 GB |
无冗余依赖,内存管理更紧凑 |
|
🔹 启动时间 |
~15s |
~3s |
无复杂初始化,适合快速迭代 |
核心架构分层
┌─────────────────────────────────┐
│ API Layer (用户接口层) │
│ • LLM (入口类) │
│ • SamplingParams (采样配置) │
└─────────┬───────────────────────┘
│
┌─────────▼───────────────────────┐
│ Core Engine Layer (核心引擎) │
│ • LLMEngine: 请求生命周期管理 │
│ • ModelRunner: 分布式模型执行 │
│ • Scheduler: 动态批处理调度 │
└─────────┬───────────────────────┘
│
┌─────────▼───────────────────────┐
│ Memory Layer (内存管理) │
│ • BlockManager: PagedAttention │
│ • Block: KV 缓存分块单元 │
│ • Sequence: 序列状态封装 │
└─────────┬───────────────────────┘
│
┌─────────▼───────────────────────┐
│ Model Layer (模型层) │
│ • models/: Qwen3 等架构实现 │
│ • layers/: Attention/MLP 等算子 │
└─────────┬───────────────────────┘
│
┌─────────▼───────────────────────┐
│ Infrastructure (基础设施) │
│ • Config: 系统参数配置 │
│ • Context: 执行上下文传递 │
└─────────────────────────────────┘代码结构梳理
nano-vllm/
├── nanovllm/
│ ├── __init__.py # 暴露 LLM, SamplingParams
│ ├── config.py # Config 数据类,参数校验
│ ├── llm.py # LLM 入口,继承 LLMEngine
│ ├── sampling_params.py # 采样参数定义
│ ├── engine/
│ │ ├── llm_engine.py # LLMEngine: 核心编排器
│ │ ├── model_runner.py # ModelRunner: 分布式执行
│ │ ├── scheduler.py # Scheduler: 动态批处理
│ │ └── sequence.py # Sequence: 序列状态管理
│ ├── memory/
│ │ └── block_manager.py # BlockManager + Block 实现
│ ├── models/
│ │ └── qwen3.py # Qwen3ForCausalLM 架构
│ ├── layers/
│ │ ├── attention.py # FlashAttention 封装
│ │ ├── mlp.py # MLP 层实现
│ │ └── rms_norm.py # 归一化算子
│ └── utils/
│ ├── context.py # 全局上下文传递
│ └── loader.py # 模型权重加载
├── example.py # 快速使用示例
├── bench.py # 性能基准测试
└── pyproject.toml # 依赖与构建配置PagedAttention:KV Cache
传统 LLM 推理中,KV Cache 采用连续内存分配:
文档1: [████████████████████] 20 tokens
文档2: [██████] 6 tokens
文档3: [████████████] 12 tokens
问题:
• 内存碎片:短文档浪费空间(6 token 占 20 token 槽位)
• 无法复用:相同 prompt 重复计算
• 动态扩缩困难:预分配过大浪费,过小 OOMPagedAttention 核心设计,将 KV Cache 拆分为固定大小的 Block(页),类似操作系统虚拟内存:
Block 大小 = 256 tokens(可配置)
文档1: [B0][B1][B2] (3 blocks, 实际用 20 slots)
文档2: [B3] (1 block, 实际用 6 slots)
文档3: [B4][B5] (2 blocks, 实际用 12 slots)
空闲块池: [B6][B7][B8]...参考Block的实现
# nanovllm/memory/block_manager.py
class Block:
"""KV Cache 的最小分配单元"""
def __init__(self, block_id: int, block_size: int, num_layers: int,
num_heads: int, head_dim: int, dtype: torch.dtype):
self.block_id = block_id
self.block_size = block_size # 每块容纳的 token 数
# 预分配 KV 缓存张量: [num_layers, 2, block_size, num_heads, head_dim]
# 2 表示 key 和 value
self.kv_cache = torch.empty(
num_layers, 2, block_size, num_heads, head_dim,
dtype=dtype, device="cuda"
)
self.ref_count = 0 # 引用计数,支持多序列共享
def write(self, layer_idx: int, key: torch.Tensor, value: torch.Tensor,
slot_offset: int, num_tokens: int):
"""写入 KV: 支持部分写入(最后一个 block 可能未满)"""
self.kv_cache[layer_idx, 0, slot_offset:slot_offset+num_tokens] = key
self.kv_cache[layer_idx, 1, slot_offset:slot_offset+num_tokens] = value
def read(self, layer_idx: int, slot_offset: int, num_tokens: int):
"""读取 KV"""
return (
self.kv_cache[layer_idx, 0, slot_offset:slot_offset+num_tokens],
self.kv_cache[layer_idx, 1, slot_offset:slot_offset+num_tokens]
)
class BlockManager:
"""KV Cache 的分配器 + 缓存管理器"""
def __init__(self, config: Config):
self.block_size = config.block_size # 默认 256
self.num_blocks = config.num_gpu_blocks # 根据显存计算
# 1. 初始化所有 Block(预分配显存,避免运行时分配开销)
self.blocks = [
Block(i, self.block_size, ...) for i in range(self.num_blocks)
]
self.free_block_ids = deque(range(self.num_blocks)) # 空闲块池
# 2. Prefix Caching: 哈希映射 token 序列 → block_id
self.hash_to_block_id: Dict[int, int] = {}
def compute_hash(self, token_ids: List[int], prefix_hash: Optional[int]) -> int:
"""计算 token 序列的哈希,用于前缀缓存匹配"""
# 使用滚动哈希(Rabin-Karp),支持 O(1) 增量计算
h = prefix_hash if prefix_hash else HASH_BASE
for token in token_ids:
h = (h * HASH_PRIME + token) % HASH_MOD
return h
def allocate(self, seq: Sequence) -> bool:
"""为序列分配 KV Cache blocks"""
num_tokens = len(seq.token_ids)
num_blocks_needed = (num_tokens + self.block_size - 1) // self.block_size
# 1. 检查是否有足够空闲块
if len(self.free_block_ids) < num_blocks_needed:
return False # 显存不足,触发 eviction 或拒绝请求
# 2. 尝试 Prefix Caching:查找已计算的相同前缀
prefix_hash = self.compute_hash(seq.token_ids, seq.prefix_hash)
if prefix_hash in self.hash_to_block_id:
# 缓存命中!复用已有 block,避免重复计算
cached_block_id = self.hash_to_block_id[prefix_hash]
self.blocks[cached_block_id].ref_count += 1
seq.block_table.append(cached_block_id)
return True
# 3. 分配新 blocks
for _ in range(num_blocks_needed):
block_id = self.free_block_ids.popleft()
block = self.blocks[block_id]
block.ref_count += 1
seq.block_table.append(block_id)
# 4. 注册前缀哈希(用于后续请求复用)
self.hash_to_block_id[prefix_hash] = seq.block_table[0]
seq.prefix_hash = prefix_hash
return True
def append_token(self, seq: Sequence, new_token: int) -> bool:
"""Decode 阶段:为序列追加一个新 token"""
# 1. 定位当前写入位置
current_len = len(seq.token_ids) # 追加前的长度
block_idx = current_len // self.block_size
slot_offset = current_len % self.block_size
# 2. 如果当前 block 已满,分配新 block
if slot_offset == 0 and block_idx > 0: # 新 block 起始
if not self.free_block_ids:
return False # 需要触发 eviction
new_block_id = self.free_block_ids.popleft()
seq.block_table.append(new_block_id)
self.blocks[new_block_id].ref_count = 1
return True
def free(self, seq: Sequence):
"""释放序列占用的 blocks(引用计数归零时回收)"""
for block_id in seq.block_table:
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0:
# 1. 从哈希表中移除(如果该 block 是前缀缓存)
for h, bid in list(self.hash_to_block_id.items()):
if bid == block_id:
del self.hash_to_block_id[h]
# 2. 回收到空闲池
self.free_block_ids.append(block_id)
seq.block_table.clear()内存布局可视化
GPU 显存布局(简化):
┌─────────────────────────────┐
│ 模型权重 (只读) │
│ [Layer0] [Layer1] ... │
├─────────────────────────────┤
│ KV Cache Pool (可写) │
│ ┌─────┬─────┬─────┬─────┐ │
│ │ B0 │ B1 │ B2 │ B3 │ │ ← 每个 Block 固定大小
│ │[K/V]│[K/V]│[K/V]│[K/V]│ │ 256 tokens × heads × dims
│ └─────┴─────┴─────┴─────┘ │
│ ... │
├─────────────────────────────┤
│ 中间激活值 (临时) │
│ FlashAttention workspace │
└─────────────────────────────┘
逻辑映射:
Sequence A: token[0:256] → Block0, token[256:512] → Block1
Sequence B: token[0:100] → Block2 (部分使用)
Shared Prefix: token[0:50] → Block0 (ref_count=2)|
设计选择 |
优势 |
代价 |
|---|---|---|
|
固定 Block 大小 |
内存分配 O(1),无碎片 |
最后一个 block 可能有内部碎片(平均浪费 < 50%) |
|
引用计数 + 哈希缓存 |
支持 Prefix Caching,相同 prompt 零重复计算 |
哈希计算 + 查表开销(约 1-2% 延迟) |
|
预分配所有 Blocks |
避免运行时 CUDA malloc 开销 |
启动时显存占用略高,但可预测 |
PagedAttention 的本质是用少量计算开销(哈希+查表)换取显存利用率和缓存命中率的大幅提升,在 batch size 大、prompt 重复率高的场景收益显著
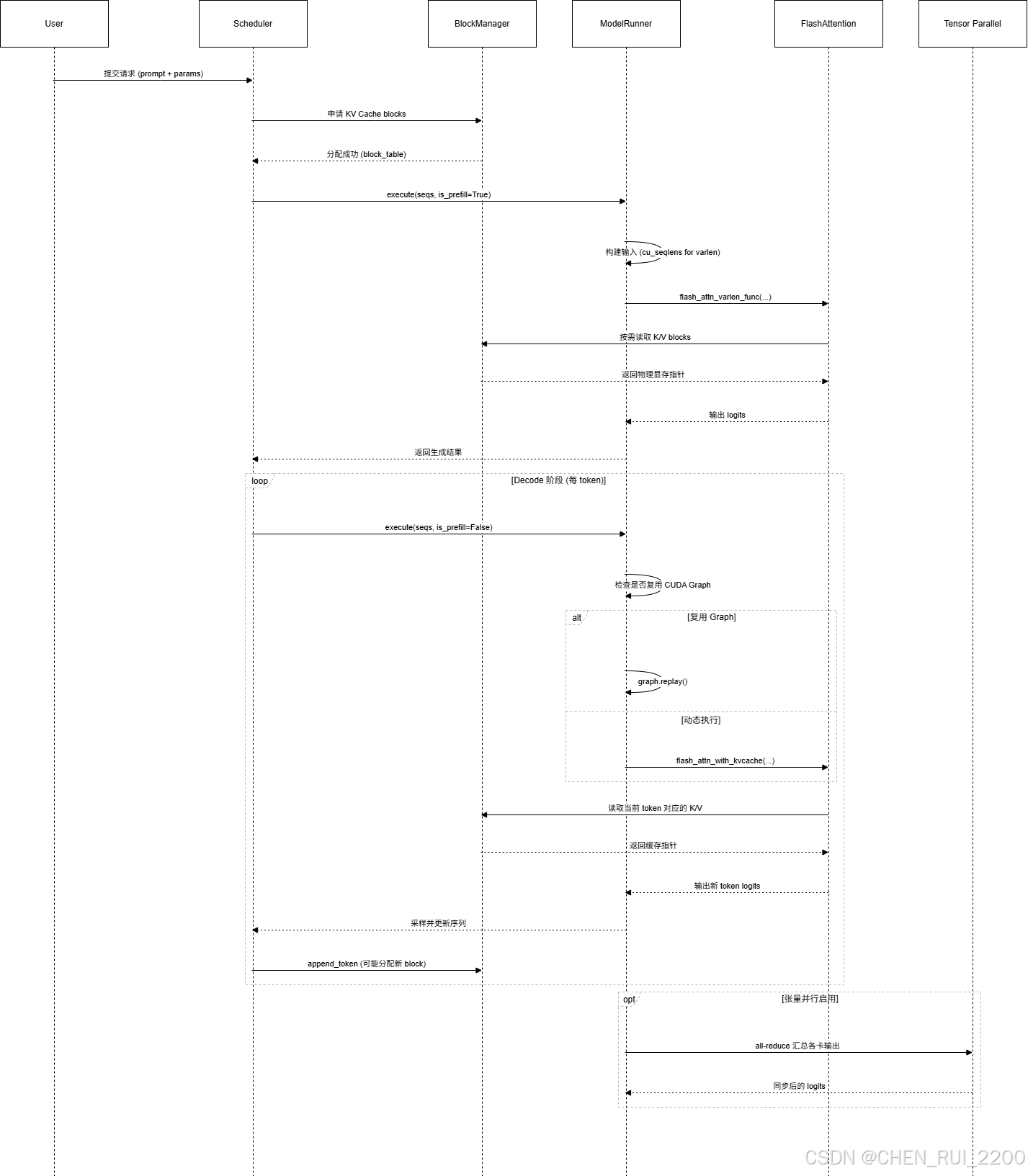
两阶段调度:Prefill vs Decode
为什么需要区分阶段?
|
阶段 |
计算特征 |
优化目标 |
|---|---|---|
|
Prefill |
处理整个 prompt,计算量 O(n²),但只需执行 1 次 |
最大化并行度,吃满 GPU |
|
Decode |
每次生成 1 个 token,计算量 O(n),但需执行多次 |
最小化延迟,减少 CPU-GPU 同步 |
Scheduler 核心逻辑
# nanovllm/engine/scheduler.py
class Scheduler:
def __init__(self, config: Config):
self.waiting = deque() # 等待进入预处理的请求
self.running = deque() # 正在生成的请求
self.swapped = deque() # 被换出到 CPU 的请求(本简化版未实现)
self.max_num_batched_tokens = config.max_num_batched_tokens # 批处理上限
self.max_num_seqs = config.max_num_seqs # 最大并发序列数
def add_request(self, seq: Sequence):
"""接收新请求"""
self.waiting.append(seq)
def schedule(self) -> Tuple[List[Sequence], bool]:
"""
调度决策:选择下一批执行的序列
Returns: (scheduled_seqs, is_prefill_phase)
"""
scheduled_seqs = []
# ── 策略 1: 优先处理 Prefill 阶段的新请求 ──
# 原因: Prefill 计算量大,尽早完成可释放显存
while self.waiting and self._can_schedule(scheduled_seqs, is_prefill=True):
seq = self.waiting[0]
# 1. 检查 KV Cache 是否足够
if not self.block_manager.can_allocate(seq):
break # 显存不足,等待其他序列释放
# 2. 分配资源并转移状态
self.block_manager.allocate(seq)
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)
seq.status = SequenceStatus.RUNNING_PREFILL
if scheduled_seqs:
return scheduled_seqs, True # is_prefill=True
# ── 策略 2: 处理 Decode 阶段的增量生成 ──
# 原因: Decode 延迟敏感,需保证高优先级序列及时响应
while self.running and self._can_schedule(scheduled_seqs, is_prefill=False):
seq = self.running[0]
# 1. 检查是否能追加新 token(block 是否满)
if not self.block_manager.can_append(seq):
# 尝试 evict 低优先级序列(简化版直接跳过)
break
scheduled_seqs.append(seq)
seq.status = SequenceStatus.RUNNING_DECODE
return scheduled_seqs, False # is_prefill=False
def _can_schedule(self, current_batch: List[Sequence], is_prefill: bool) -> bool:
"""检查是否还能添加更多序列到当前 batch"""
if len(current_batch) >= self.max_num_seqs:
return False
# 计算当前 batch 的总 token 数
total_tokens = sum(
len(seq.token_ids) if is_prefill else 1 # Decode 阶段每序列只算 1 个新 token
for seq in current_batch
)
# 预估新序列的 token 消耗
new_seq = self.waiting[0] if is_prefill else self.running[0]
new_tokens = len(new_seq.token_ids) if is_prefill else 1
return total_tokens + new_tokens <= self.max_num_batched_tokens动态批处理示例
时间线: t0 → t1 → t2 → t3
t0:
waiting: [ReqA(prompt=50t), ReqB(prompt=30t)]
running: []
→ 调度: ReqA + ReqB 一起 Prefill (总 80t < max_16384)
t1:
waiting: [ReqC(prompt=100t)]
running: [ReqA(gen=1), ReqB(gen=1)] # 进入 Decode
→ 调度: 优先 Decode(延迟敏感),ReqC 等待
t2:
running: [ReqA(gen=10, done), ReqB(gen=10), ReqC(prompt=100t)]
→ ReqA 完成释放显存
→ 调度: ReqC 进入 Prefill + ReqB 继续 Decode (混合 batch)
t3:
running: [ReqB(gen=50), ReqC(gen=1)]
→ 纯 Decode 阶段,小 batch 高频调度关键优化:Continuous Batching
# ModelRunner 中处理混合 batch 的核心
def execute_model(self, seqs: List[Sequence], is_prefill: bool):
# 1. 构建输入张量(处理变长序列)
if is_prefill:
# Prefill: 所有 token 一起处理 → 需 padding 或 varlen 支持
input_ids = [seq.token_ids for seq in seqs] # List[List[int]]
positions = [list(range(len(ids))) for ids in input_ids]
# 使用 cu_seqlens 支持变长序列 FlashAttention
cu_seqlens = [0]
for ids in input_ids:
cu_seqlens.append(cu_seqlens[-1] + len(ids))
context.cu_seqlens_q = torch.tensor(cu_seqlens, dtype=torch.int32, device="cuda")
else:
# Decode: 每个序列只取最后一个 token → 无需 padding
input_ids = [[seq.token_ids[-1]] for seq in seqs] # [[token], [token], ...]
positions = [[len(seq.token_ids)-1] for seq in seqs]
# 记录每个序列的 context 长度,用于 KV Cache 索引
context.context_lens = torch.tensor(
[len(seq.token_ids)-1 for seq in seqs], dtype=torch.int32, device="cuda"
)
# 2. 执行模型前向传播(FlashAttention 内部处理变长逻辑)
output = self.model(input_ids, positions, is_prefill)
# 3. 采样并更新序列状态
for i, seq in enumerate(seqs):
next_token = sample(output[i], seq.sampling_params)
seq.append_token(next_token)
# 检查是否生成结束
if next_token == seq.sampling_params.eos_token_id:
seq.status = SequenceStatus.FINISHED
self.block_manager.free(seq) # 立即释放 KV Cache不等待所有序列完成,而是动态地将完成/新到达的请求插入执行流,最大化 GPU 利用率,降低平均延迟。
FlashAttention 集成:IO 感知的注意力计算
传统 Attention 的瓶颈
# 标准 Self-Attention (O(n²) 内存)
def naive_attention(q, k, v):
scores = q @ k.transpose(-2, -1) / sqrt(d) # [B, H, n, n] ← 显存爆炸!
probs = softmax(scores, dim=-1)
return probs @ v问题:当序列长度 n=4096 时,score 矩阵需要 4096²×4bytes ≈ 64MB/头,多 head+batch 时显存不足。
FlashAttention 核心思想
分块计算 + 在线 softmax + 重计算,将内存复杂度从 O(n²) 降为 O(n):
传统: 计算完整 score 矩阵 → softmax → 加权求和
Flash:
for 每个 query 块:
for 每个 key/value 块:
1. 加载小块 K/V 到 SRAM
2. 计算局部 score + softmax (在线更新全局统计量)
3. 累加输出
4. 丢弃小块 K/V (不保存完整 score 矩阵)nano-vllm 中的 FlashAttention 封装
# nanovllm/layers/attention.py
class Attention(nn.Module):
def __init__(self, config: Config):
super().__init__()
self.num_heads = config.num_attention_heads
self.head_dim = config.hidden_size // self.num_heads
self.block_size = config.block_size # PagedAttention 的 block 大小
# 线性层
self.qkv_proj = nn.Linear(config.hidden_size, 3 * config.hidden_size)
self.o_proj = nn.Linear(config.hidden_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor,
context: ExecutionContext) -> torch.Tensor:
# 1. 投影到 Q/K/V
qkv = self.qkv_proj(hidden_states) # [total_tokens, 3*hidden]
q, k, v = qkv.chunk(3, dim=-1)
q = q.view(-1, self.num_heads, self.head_dim)
k = k.view(-1, self.num_heads, self.head_dim)
v = v.view(-1, self.num_heads, self.head_dim)
# 2. 根据阶段选择 FlashAttention 变体
if context.is_prefill:
# ── Prefill: 变长序列,使用 varlen FlashAttention ──
# cu_seqlens: [0, len1, len1+len2, ...] 标记每个序列边界
output = flash_attn_varlen_func(
q, k, v,
cu_seqlens_q=context.cu_seqlens_q, # query 序列边界
cu_seqlens_k=context.cu_seqlens_k, # key 序列边界(通常相同)
max_seqlen_q=context.max_seqlen_q, # 最长序列长度
max_seqlen_k=context.max_seqlen_k,
causal=True, # 自回归掩码
softmax_scale=1.0 / (self.head_dim ** 0.5)
)
else:
# ── Decode: 单 token 生成,使用 kvcache 优化版本 ──
# 关键: k/v 不是传入的张量,而是从 PagedAttention 的 block 中读取
output = flash_attn_with_kvcache(
q.unsqueeze(1), # [batch, 1, heads, dim]
k_cache=self.k_cache, # [num_blocks, 2, block_size, heads, dim]
v_cache=self.v_cache,
cache_seqlens=context.context_lens, # 每个序列当前长度
causal=True,
softmax_scale=1.0 / (self.head_dim ** 0.5)
)
output = output.squeeze(1) # [batch, heads, dim]
# 3. 输出投影
output = output.reshape(-1, self.num_heads * self.head_dim)
return self.o_proj(output)FlashAttention 与 PagedAttention 的协同
Decode 阶段数据流:
1. Scheduler 决定执行哪些序列
2. BlockManager 提供每个序列的 block_table + 当前写入位置
3. Attention.forward 调用 flash_attn_with_kvcache:
a. 根据 cache_seqlens 计算每个 token 在哪个 block 的哪个 slot
b. Triton kernel 按需加载对应的 K/V blocks 到 SRAM
c. 分块计算 attention,避免加载整个 KV Cache
4. 输出新 token,更新 block_manager 的写入位置
关键协同点:
• PagedAttention 提供"逻辑地址 → 物理 block"的映射
• FlashAttention 提供"按需加载 + 分块计算"的执行引擎
• 两者结合实现: 大 context + 高并发 + 低显存占用性能对比(理论)
|
方案 |
显存占用 |
计算效率 |
适用场景 |
|---|---|---|---|
|
标准 Attention |
O(n²) |
高(但 OOM 限制 n) |
n < 2048 |
|
FlashAttention v1 |
O(n) |
中(需重计算) |
n ≤ 8192 |
|
FlashAttention v2 + Paged |
O(n) + 分页开销 |
高(IO 优化 + 缓存复用) |
n ≤ 32768+ |
nano-vllm 的选择:集成
flash-attn库的 v2 版本,通过flash_attn_varlen_func和flash_attn_with_kvcache两个 API 分别覆盖 Prefill/Decode 场景,在保持代码简洁的同时获得工业级性能。
张量并行(Tensor Parallelism):多卡分布式推理
单卡显存限制(如 RTX 4090 24GB)无法加载大模型(如 Qwen-7B 需 ~14GB 权重 + KV Cache),需将模型切分到多卡。
nano-vllm 的 TP 实现(简化版)
# nanovllm/engine/model_runner.py
class ModelRunner:
def __init__(self, config: Config, rank: int, event: multiprocessing.Event):
self.rank = rank
self.world_size = config.tensor_parallel_size
# 1. 初始化 NCCL 通信组
if self.world_size > 1:
dist.init_process_group(
backend="nccl",
init_method="tcp://localhost:2333", # 简化:单机多卡
world_size=self.world_size,
rank=rank
)
torch.cuda.set_device(rank) # 每张卡绑定一个 GPU
# 2. 加载模型(按 rank 切分权重)
self.model = self._load_sharded_model(config, rank)
# 3. 等待所有进程就绪
event.wait()
def _load_sharded_model(self, config: Config, rank: int):
"""按列/行切分线性层权重"""
model = Qwen3ForCausalLM(config)
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
weight = module.weight.data # [out_features, in_features]
# Column Parallel: 切分输出维度 (qkv_proj, o_proj 的输出)
if self._is_column_parallel(name):
# 将 out_features 按 rank 切分
chunk_size = weight.shape[0] // self.world_size
start = rank * chunk_size
end = start + chunk_size if rank < self.world_size-1 else weight.shape[0]
module.weight.data = weight[start:end].clone()
module.out_features = chunk_size # 更新元信息
# Row Parallel: 切分输入维度 (o_proj 的输入)
elif self._is_row_parallel(name):
chunk_size = weight.shape[1] // self.world_size
start = rank * chunk_size
end = start + chunk_size if rank < self.world_size-1 else weight.shape[1]
module.weight.data = weight[:, start:end].clone()
return model.cuda()
def forward(self, input_ids: torch.Tensor, positions: torch.Tensor,
is_prefill: bool) -> torch.Tensor:
# 1. 本地前向传播(只计算本卡负责的部分)
hidden = self.model(input_ids, positions, is_prefill) # [tokens, local_hidden]
# 2. 如果是 Row Parallel 层输出,需要 all-reduce 汇总
if self._needs_all_reduce:
dist.all_reduce(hidden, op=dist.ReduceOp.SUM) # 多卡结果求和
return hidden张量并行切分示意图(以 QKV 投影为例)
原始 Linear: out=3072, in=2048 [████████████████████████] 3072 × 2048 TP=2 切分: Rank 0: [████████████] 1536 × 2048 ← 计算 Q0,K0,V0 Rank 1: [████████████] 1536 × 2048 ← 计算 Q1,K1,V1 Attention 计算: • 每个 rank 独立计算自己的 Q/K/V attention • 输出拼接: [O0, O1] → 全连接层输入 Row Parallel (o_proj): Rank 0: [████] 2048 × 1536 ← 处理 O0 部分 Rank 1: [████] 2048 × 1536 ← 处理 O1 部分 → all-reduce 求和得到最终输出
nano-vllm 的 TP 实现是教学级简化,与工业版 vLLM 相比:
|
特性 |
nano-vllm |
工业 vLLM |
|---|---|---|
|
通信优化 |
基础 all-reduce |
NCCL 异步 + 通信计算重叠 |
|
负载均衡 |
均匀切分 |
考虑层间差异的动态调度 |
|
容错 |
无 |
支持节点故障恢复 |
|
多节点 |
仅单机多卡 |
支持多机多卡(Ray 调度) |
通过 50 行代码理解 TP 的核心思想——权重切分 + 通信同步
CUDA Graph:减少 CPU 调度开销
传统 PyTorch 执行流程:
CPU: 解析 Python 代码 → 构建计算图 → 启动 CUDA kernel → 等待完成 → 下一轮
↑ 每步都有 CPU-GPU 同步开销,Decode 阶段高频调用时成为瓶颈
UDA Graph 核心思想
将静态计算图捕获为 GPU 原生指令序列,后续执行时 CPU 只需触发一次 launch:
首次执行(Capture 阶段):
CPU: 记录所有 kernel launch + 内存操作 → 生成 CUDA Graph
后续执行(Replay 阶段):
CPU: graph.replay() ← 单次系统调用
GPU: 按预录指令流执行,无 CPU 干预nano-vllm 中的 CUDA Graph 集成
# nanovllm/engine/model_runner.py
class ModelRunner:
def __init__(self, config: Config, ...):
self.enforce_eager = config.enforce_eager
self.cuda_graphs = {} # batch_size → graph
def capture_cudagraph(self, batch_size: int):
"""捕获指定 batch size 的静态计算图"""
# 1. 准备静态输入(占位符,实际推理时替换)
input_ids = torch.zeros(batch_size, 1, dtype=torch.long, device="cuda")
positions = torch.zeros(batch_size, 1, dtype=torch.long, device="cuda")
# 2. 创建 CUDA Graph
self.cuda_graphs[batch_size] = torch.cuda.CUDAGraph()
with torch.cuda.graph(self.cuda_graphs[batch_size]):
static_output = self.model(input_ids, positions, is_prefill=False)
# 3. 保存静态张量引用(用于 replay 时更新输入)
self.static_inputs[batch_size] = {"input_ids": input_ids, "positions": positions}
self.static_outputs[batch_size] = static_output
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor,
is_prefill: bool) -> torch.Tensor:
batch_size = input_ids.shape[0]
# 小 batch decode + 非 eager 模式 → 尝试复用 CUDA Graph
if not is_prefill and not self.enforce_eager and batch_size in self.cuda_graphs:
# 1. 更新静态输入张量的内容(零拷贝)
self.static_inputs[batch_size]["input_ids"].copy_(input_ids)
self.static_inputs[batch_size]["positions"].copy_(positions)
# 2. 重放计算图(CPU 开销 ~10μs vs 传统 ~100μs)
self.cuda_graphs[batch_size].replay()
# 3. 返回静态输出(内容已更新)
return self.static_outputs[batch_size].clone() # 避免后续修改污染
else:
# Prefill 或大 batch → 动态执行(无法捕获静态图)
return self.model(input_ids, positions, is_prefill)适用条件与收益
|
条件 |
是否适用 CUDA Graph |
原因 |
|---|---|---|
|
✅ batch size 固定 |
是 |
计算图结构不变 |
|
✅ Decode 阶段 |
是 |
每次输入 1 token,计算模式稳定 |
|
❌ Prefill 阶段 |
否 |
序列长度可变,图结构动态 |
|
❌ 动态 control flow |
否 |
if/while 导致图结构变化 |
协同工作全景

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)