【vllm】 DP并行2
这段代码是一个职责划分的逻辑开关。离线工作者: 只关心自己。集群总指挥 (rank 0): 必须关心所有人(所有普通计算节点 (rank > 0): 只关心自己手下的人(在自己节点上启动的通过这种方式,vLLM 确保了在复杂的分布式部署中,每个进程都有明确的职责,启动和同步过程既完整又高效。这是一个非常好的问题,因为它触及了理解这段代码的关键!这里的**“我”指的是当前正在执行这个函数的那个vll
好的,我们来深入且完整地剖析 data-parallel-rpc-port 这个参数,并梳理它在代码中的完整流程。
https://docs.vllm.ai/en/latest/serving/data_parallel_deployment/#internal-load-balancing
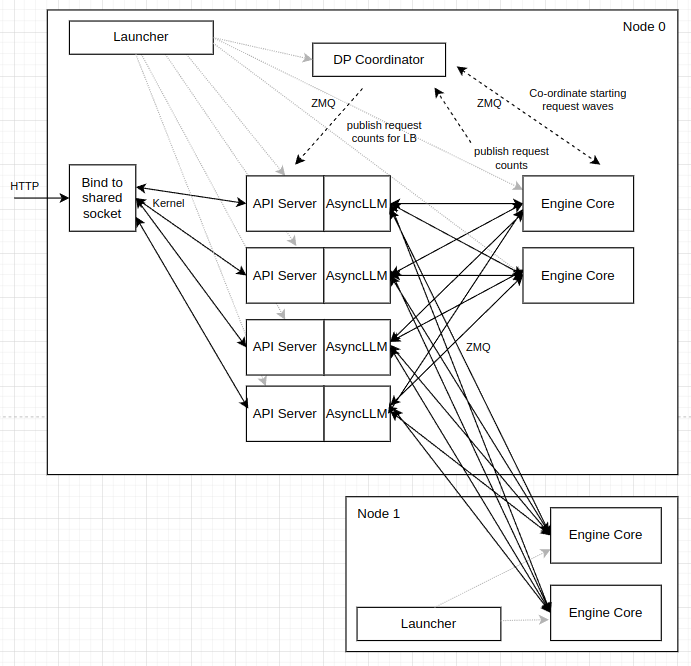
您好!这两个问题都非常棒,直击这张架构图的核心。
1. 图中的 “Launcher” 是指什么?
图中的 “Launcher” 指的是用户在命令行中执行的那个初始进程,也就是 vllm serve ... 这个命令本身所启动的那个父进程。
它之所以被称为“启动器”,是因为它的核心职责就是**“启动和协调”**整个 vLLM 服务的所有其他组件。
让我们看看它具体做了哪些“启动”工作(以 Node 0 为例):
- 启动
DP Coordinator: Launcher 进程创建并启动了DP Coordinator这个独立的后台进程。 - 启动
API Server: Launcher 进程创建并启动了所有API Server工作进程。在多 API Server 模式下,它会创建共享套接字,然后fork出多个子进程。 - 启动
Engine Core: Launcher 进程创建并启动了在本地节点上运行的Engine Core进程。
图中的虚线箭头从 Launcher 指向这些组件,正是表示这种“创建”或“启动”的关系。
可以把 “Launcher” 理解为整个 vLLM 服务的“总司令”或“入口点进程”。 它负责解析配置、搭建好通信框架、把所有需要的“士兵”(API Server, Engine Core, DP Coordinator)都派到各自的岗位上,然后监控整个战场的运行。
在 Node 1 上,Launcher 的角色更简单,因为它是在 --headless 模式下运行的,所以它只需要负责启动 Node 1 本地的 Engine Core 进程即可。
2. 为什么 “API Server” 后面有 “AsyncLLM”?
这个标注是为了揭示 API Server 内部的核心逻辑和关键对象。API Server 和 AsyncLLM 是两个不同层面但紧密相关的概念:
-
API Server: 这是一个进程级别的概念。它指的是一个完整的、独立的 Web 服务器进程(通常由uvicorn运行)。它的职责是:- 监听网络端口,接收 HTTP 请求。
- 解析 OpenAI 兼容的 API 请求(比如
/v1/chat/completions)。 - 将 HTTP 响应返回给客户端。
-
AsyncLLM: 这是一个对象/类级别的概念。它是 vLLM 提供的一个核心异步引擎接口类。在每个API Server进程内部,都会有一个AsyncLLM的实例。这个实例是前端(Web 服务)和后端(模型推理)之间的桥梁。它的职责是:- 提供异步方法,如
generate()或chat()。 - 将上层
API Server传来的请求(如 prompt, sampling_params 等)打包成 vLLM 内部的Request对象。 - 通过它内部的
EngineCoreClient(如AsyncMPClient),使用 ZMQ 将请求发送给后端的Engine Core。 - 异步地从
Engine Core接收流式返回的 token,并将它们传递回API Server。
- 提供异步方法,如
所以,“API Server | AsyncLLM” 这个标注的含义是:
“这是一个 API Server 进程,其内部的核心驱动逻辑是由一个
AsyncLLM对象实例来完成的。”
API Server 负责“外壳”(处理 HTTP 协议),而 AsyncLLM 负责“内核”(与 vLLM 的分布式推理引擎进行实际的异步交互)。这个标注帮助我们理解,当一个 HTTP 请求进入 API Server 后,它最终会被转换成对 AsyncLLM 对象的调用,从而进入 vLLM 的推理流程。
简而言之:API Server 是房子的外观,AsyncLLM 是房子里的智能管家。
data-parallel-rpc-port 详解
简单来说,data-parallel-rpc-port 定义了在多节点数据并行部署中,所有计算节点(Worker Nodes)用来向主节点(Head Node)“报到”和进行初始同步的那个唯一的、指定的网络端口。
您可以把它想象成一个**“报到大厅的门牌号”**。
- 主节点 (Head Node):它在启动时,会在自己的 IP 地址和这个指定的端口上开设这个“报到大厅”。它在这里等待所有其他节点的工作人员前来登记。
- 计算节点 (Worker Node):它们在启动时,被告知“报到大厅”的完整地址(IP + 端口)。它们会主动前往这个地址,完成登记(握手),并领取后续工作的指令(获取
DP Coordinator等组件的地址)。
它的核心作用
-
初始集结点 (Initial Rendezvous Point): 在一个分布式系统中,各个独立的进程需要一个共同的、预先知道的“地方”来首次建立联系。
data-parallel-rpc-port和data-parallel-address共同构成了这个集结点的地址。 -
握手通信通道 (Handshake Channel): 它是
wait_for_engine_startup函数进行两阶段握手(HELLO/READY)所使用的网络通道。所有Engine Core,无论本地还是远程,都通过这个端口与主节点的启动程序进行通信。 -
配置分发通道 (Configuration Distribution Channel): 在握手过程中,主节点需要将关键的配置信息(如
DP Coordinator的地址)分发给所有Engine Core。这个分发过程也是通过这个端口建立的 ZMQ 连接完成的。
为什么需要这个参数?
因为在多机环境下,进程无法像在单机上那样轻易地共享资源或发现彼此。必须有一个稳定、可预测的地址作为通信的起点。这个端口必须是在主节点上一个可用的、且在计算节点防火墙策略中允许访问的端口。
完整代码流程
下面我们来追踪当用户在命令行指定 --data-parallel-rpc-port 13345 后,这个值在代码中是如何被使用的。
第 1 步: 命令行输入与参数解析
用户在两个节点上分别执行命令:
- 主节点 (Node 0):
vllm serve ... --data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345 - 计算节点 (Node 1):
vllm serve --headless ... --data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345 - 代码位置:
vllm/entrypoints/cli/serve.py - 发生的事:
ServeSubcommand类中的argparse解析器会读取这些参数,并将13345存入args.data_parallel_rpc_port。
第 2 步: 创建配置对象
在 serve.py 的 cmd 方法或其调用的函数中,VllmConfig 对象会被创建。
- 代码位置:
vllm.AsyncEngineArgs.from_cli_args(args).create_engine_config(...) - 发生的事: 命令行参数
args.data_parallel_rpc_port的值被用来初始化ParallelConfig,最终存储在vllm_config.parallel_config.data_parallel_rpc_port。现在,这个端口号成为了整个 vLLM 实例配置的一部分。
第 3 步: 启动核心引擎 (launch_core_engines)
这是最关键的协调步骤,发生在主节点上(对于 headless 节点,流程类似但更简化)。
-
代码位置:
vllm/v1/engine/utils.py->launch_core_engines函数 -
发生的事:
- 获取配置: 函数从传入的
vllm_config中读取host(data_parallel_address) 和port(data_parallel_rpc_port)。parallel_config = vllm_config.parallel_config host = parallel_config.data_parallel_master_ip port = parallel_config.data_parallel_rpc_port - 构建握手地址: 使用
host和port构建一个完整的 ZMQ TCP 地址。# from vllm.utils.network_utils import get_tcp_uri handshake_address = get_tcp_uri(host, port) # 结果为 "tcp://10.0.0.1:13345" - 主节点绑定套接字 (开设“报到大厅”):
launch_core_engines函数内部使用一个上下文管理器来创建和管理握手套接字。
这里,主节点创建了一个with zmq_socket_ctx( local_handshake_address, zmq.ROUTER, bind=True ) as handshake_socket: # ...ROUTER类型的 ZMQ 套接字,并绑定 (bind) 到了"tcp://10.0.0.1:13345"。它现在开始在这个地址上监听传入的连接。
- 获取配置: 函数从传入的
第 4 步: 启动工作进程并传递地址
主节点和计算节点都会执行这一步来启动它们各自的 Engine Core 进程。
-
代码位置:
vllm/v1/engine/utils.py->CoreEngineProcManager -
发生的事:
- 在
launch_core_engines的with块内部,CoreEngineProcManager被实例化。 - 在创建
CoreEngineProcManager时,上一步构建的handshake_address(“tcp://10.0.0.1:13345”) 被作为参数传递进去。local_engine_manager = CoreEngineProcManager( ..., handshake_address=handshake_address, # "tcp://10.0.0.1:13345" ... ) CoreEngineProcManager在其__init__方法中,为每个要启动的Engine Core创建一个multiprocessing.Process。handshake_address作为kwargs的一部分,被准备好传递给子进程的目标函数。
- 在
第 5 步: 工作进程连接主节点 (前来“报到”)
每个新创建的 Engine Core 子进程会执行其目标函数 EngineCoreProc.run_engine_core。
-
代码位置:
vllm/v1/engine/core.py->EngineCoreProc.run_engine_core -
发生的事:
- 子进程从其启动参数中获取
handshake_address。 - 在
EngineCore的初始化过程中,它会创建一个 ZMQDEALER套接字。 - 然后,它使用这个
DEALER套接字连接 (connect) 到handshake_address。# EngineCore 内部逻辑的简化表示 handshake_client = context.socket(zmq.DEALER) handshake_client.connect(handshake_address) # 连接到 "tcp://10.0.0.1:13345" - 连接成功后,它立刻通过这个连接发送 “HELLO” 消息,开始握手流程。
- 子进程从其启动参数中获取
第 6 步: 握手和同步
- 代码位置:
vllm/v1/engine/utils.py->wait_for_engine_startup - 发生的事:
- 主节点上的
wait_for_engine_startup函数使用它在第 3 步创建的handshake_socket(它监听在13345端口)接收来自所有Engine Core(包括远程的)的 “HELLO” 和 “READY” 消息。 - 它通过同一个套接字将配置信息发回给每个
Engine Core。 - 一旦所有
Engine Core都完成了这个过程,wait_for_engine_startup函数结束,整个集群的初始同步完成。
- 主节点上的
总结
data-parallel-rpc-port 是多机部署的“生命线端口”。它定义了一个众所周知的集合点,让分散在网络中的各个 vLLM 进程能够找到彼此,完成身份验证和初始配置交换。一旦这个引导(bootstrap)过程完成,这个端口的使命就基本结束了,后续的常规通信(如请求分发、结果返回、状态同步)会通过在握手过程中分发的其他 ZMQ 地址和端口来进行。
多机部署的后端选择
在您提到的配置中(--data-parallel-size 2 --data-parallel-size-local 1),默认不使用 Ray 后端,而是使用 multiprocessing 后端。
后端选择逻辑
vLLM 的数据并行后端由 data_parallel_backend 参数控制: 1
data_parallel_backend: DataParallelBackend = "mp"
"""Backend to use for data parallel, either "mp" or "ray"."""
默认行为
在多节点部署中,系统默认选择 multiprocessing 后端: 2
elif current_platform.is_cuda() and self.nnodes > 1:
backend = "mp"
如何使用 Ray 后端
要使用 Ray 后端,需要显式指定:
# 主节点
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--api-server-count 2 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-backend ray
# 计算节点
python -m vllm.entrypoints.openai.api_server \
--model llama-2-7b \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address 192.168.1.100 \
--data-parallel-backend ray
Ray 后端的优势
使用 Ray 后端时的优势: 3
- 只需在任意节点运行单个启动命令
- 无需指定
--data-parallel-address - 无需指定
--data-parallel-rpc-port - 自动分配远程 DP 副本
执行器选择
系统根据后端选择相应的执行器: 4
elif distributed_executor_backend == "ray":
from vllm.v1.executor.ray_executor import RayDistributedExecutor
executor_class = RayDistributedExecutor
elif distributed_executor_backend == "mp":
from vllm.v1.executor.multiproc_executor import MultiprocExecutor
executor_class = MultiprocExecutor
Notes
总结:您提到的配置默认使用 multiprocessing 后端,不是 Ray 后端。要使用 Ray 后端必须显式添加 --data-parallel-backend ray 参数。Ray 后端简化了多节点部署但需要 Ray 集群环境,而 multiprocessing 后端更适合传统集群环境。
Wiki pages you might want to explore:
Citations
File: vllm/config/parallel.py (L119-120)
data_parallel_backend: DataParallelBackend = "mp"
"""Backend to use for data parallel, either "mp" or "ray"."""
File: vllm/engine/arg_utils.py (L610-612)
self.attention_config = AttentionConfig(**self.attention_config)
if isinstance(self.kernel_config, dict):
self.kernel_config = KernelConfig(**self.kernel_config)
File: docs/serving/data_parallel_deployment.md (L67-73)
There are several notable differences when using Ray:
- A single launch command (on any node) is needed to start all local and remote DP ranks, therefore it is more convenient compared to launching on each node
- There is no need to specify `--data-parallel-address`, and the node where the command is run is used as `--data-parallel-address`
- There is no need to specify `--data-parallel-rpc-port`
- When a single DP group requires multiple nodes, *e.g.* in case a single model replica needs to run on at least two nodes, make sure to set `VLLM_RAY_DP_PACK_STRATEGY="span"` in which case `--data-parallel-size-local` is ignored and will be automatically determined
- Remote DP ranks will be allocated based on node resources of the Ray cluster
File: vllm/v1/executor/abstract.py (L59-66)
elif distributed_executor_backend == "ray":
from vllm.v1.executor.ray_executor import RayDistributedExecutor
executor_class = RayDistributedExecutor
elif distributed_executor_backend == "mp":
from vllm.v1.executor.multiproc_executor import MultiprocExecutor
executor_class = MultiprocExecutor
Coordinator 部署位置详解
这句注释解释了 DP Coordinator 进程的部署位置决策逻辑:在非外部或混合负载均衡模式下,假设协调器与前端进程共址部署。 1
核心逻辑
# Assume coordinator is colocated with front-end procs when not in
# either external or hybrid DP LB mode.
local_only = not parallel_config.local_engines_only
部署模式判断
local_engines_only 属性定义了不同负载均衡模式下的部署策略: 2
@property
def local_engines_only(self) -> bool:
"""
Client manages local+remote EngineCores in pure internal LB case.
Client manages local EngineCores in hybrid and external LB case.
"""
return self.data_parallel_external_lb or self.data_parallel_hybrid_lb
三种负载均衡模式的部署差异
| 负载均衡模式 | local_engines_only |
local_only |
Coordinator 位置 | 通信方式 |
|---|---|---|---|---|
| 内部 LB (默认) | False |
True |
与前端进程共址 | IPC (本地) |
| 外部 LB | True |
False |
与 DP rank 0 共址 | TCP (跨节点) |
| 混合 LB | True |
False |
与本地前端共址 | TCP (跨节点) |
地址生成影响
这个决策直接影响 ZMQ 地址的生成: 3
front_publish_address = get_engine_client_zmq_addr(
local_only=local_only, host=host
)
local_only=True: 使用 IPC 地址 (ipc:///tmp/vllm_rpc/...)local_only=False: 使用 TCP 地址 (tcp://host:port)
实际应用场景
- 内部负载均衡:单节点或多节点部署,API Server 管理所有引擎,Coordinator 与 API Server 在同一节点
- 外部负载均衡:每个 DP rank 独立部署,Coordinator 与 rank 0 的引擎在同一节点
- 混合负载均衡:每个节点有本地 API Server,Coordinator 与本地前端在同一节点
Notes
这种设计确保了在不同负载均衡模式下,Coordinator 能够以最优的通信方式与相关进程通信,同时简化了部署配置的复杂性。内部模式下的共址部署减少了网络开销,而外部/混合模式下的分布式部署支持了更大规模的扩展需求。
Wiki pages you might want to explore:
Citations
File: vllm/v1/engine/coordinator.py (L66-68)
# Assume coordinator is colocated with front-end procs when not in
# either external or hybrid DP LB mode.
local_only = not parallel_config.local_engines_only
File: vllm/v1/engine/coordinator.py (L69-75)
front_publish_address = get_engine_client_zmq_addr(
local_only=local_only, host=host
)
local_only_eng = dp_size == parallel_config.data_parallel_size_local
back_publish_address = get_engine_client_zmq_addr(local_only_eng, host)
back_output_address = get_engine_client_zmq_addr(local_only_eng, host)
File: vllm/config/parallel.py (L375-380)
def local_engines_only(self) -> bool:
"""
Client manages local+remote EngineCores in pure internal LB case.
Client manages local EngineCores in hybrid and external LB case.
"""
return self.data_parallel_external_lb or self.data_parallel_hybrid_lb
Coordinator 部署位置示例
1. 内部负载均衡模式 (默认)
场景:单节点或多节点部署,API Server 管理所有引擎
# 单节点部署 - DP=2
vllm serve $MODEL --data-parallel-size 2
Coordinator 位置:与 API Server 共址部署
local_engines_only = Falselocal_only = True- 使用 IPC 地址通信 1
# 生成的地址示例
front_publish_address = "ipc:///tmp/vllm_rpc/abc123"
2. 外部负载均衡模式
场景:每个 DP rank 独立部署,外部负载均衡器分发请求
# Node 0
vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 0 \
--data-parallel-address 192.168.1.100 --port 8000
# Node 1
vllm serve $MODEL --data-parallel-size 2 --data-parallel-rank 1 \
--data-parallel-address 192.168.1.100 --port 8001
Coordinator 位置:与 DP rank 0 引擎共址
local_engines_only = Truelocal_only = False- 使用 TCP 地址通信 2
# 生成的地址示例
front_publish_address = "tcp://192.168.1.100:5555"
3. 混合负载均衡模式
场景:每个节点有本地 API Server,上游负载均衡器分发请求
# Node 0
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 0 --data-parallel-hybrid-lb
# Node 1
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 --data-parallel-hybrid-lb
Coordinator 位置:与本地前端进程共址
local_engines_only = Truelocal_only = False- 使用 TCP 地址进行跨节点通信 3
部署架构对比
| 模式 | Coordinator 位置 | 通信方式 | 典型用例 |
|---|---|---|---|
| 内部 LB | 与 API Server 共址 | IPC (本地) | 简化部署,中小规模 |
| 外部 LB | 与 DP rank 0 共址 | TCP (跨节点) | 大规模,Kubernetes |
| 混合 LB | 与本地前端共址 | TCP (跨节点) | 多节点,避免单点瓶颈 |
Notes
内部负载均衡模式下,Coordinator 与前端进程共址部署可以使用高效的 IPC 通信,减少网络开销。而外部和混合模式需要跨节点通信,因此使用 TCP 地址。 4
Wiki pages you might want to explore:
Wiki pages you might want to explore:
Citations
File: vllm/v1/engine/coordinator.py (L66-75)
# Assume coordinator is colocated with front-end procs when not in
# either external or hybrid DP LB mode.
local_only = not parallel_config.local_engines_only
front_publish_address = get_engine_client_zmq_addr(
local_only=local_only, host=host
)
local_only_eng = dp_size == parallel_config.data_parallel_size_local
back_publish_address = get_engine_client_zmq_addr(local_only_eng, host)
back_output_address = get_engine_client_zmq_addr(local_only_eng, host)
File: vllm/config/parallel.py (L375-380)
def local_engines_only(self) -> bool:
"""
Client manages local+remote EngineCores in pure internal LB case.
Client manages local EngineCores in hybrid and external LB case.
"""
return self.data_parallel_external_lb or self.data_parallel_hybrid_lb
File: docs/serving/data_parallel_deployment.md (L83-94)
## Hybrid Load Balancing
Hybrid load balancing sits between the internal and external approaches. Each node runs its own API server(s) that only queue requests to the data-parallel engines colocated on that node. An upstream load balancer (for example, an ingress controller or traffic router) spreads user requests across those per-node endpoints.
Enable this mode with `--data-parallel-hybrid-lb` while still launching every node with the global data-parallel size. The key differences from internal load balancing are:
- You must provide `--data-parallel-size-local` and `--data-parallel-start-rank` so each node knows which ranks it owns.
- Not compatible with `--headless` since every node exposes an API endpoint.
- Scale `--api-server-count` per node based on the number of local ranks
In this configuration, each node keeps scheduling decisions local, which reduces cross-node traffic and avoids single node bottlenecks at larger DP sizes.
这是一个非常好的问题,选择 zmq.ROUTER 类型是 ZMQ 中一个经过深思熟虑的、非常经典的设计模式,尤其适用于这种“一个中心服务对多个客户端”的场景。
简单来说,选择 zmq.ROUTER 的核心原因是:它能够让服务端(在这里是主节点的 launch_core_engines 进程)准确地知道消息是哪个客户端(哪个 Engine Core)发来的,并且能够精确地将回复发送回那个特定的客户端。
让我们来详细分解为什么 ROUTER 是最佳选择,并与其他类型进行对比。
zmq.ROUTER 套接字的特性
ROUTER 套接字(曾被称为 XREP)有两个关键特性,使其非常适合作为中心服务器:
-
自动添加身份帧 (Identity Frame):
- 当一个客户端(通常是
DEALER或REQ类型)连接到ROUTER并发送消息时,ROUTER在接收这个消息时,并不会直接收到消息内容。它会在消息的最前面自动添加一个额外的**“身份帧 (identity frame)”**。 - 这个身份帧包含了发送方客户端的唯一标识。如果客户端没有设置
identity,ZMQ 会自动为其生成一个 UUID。在 vLLM 中,Engine Core会将自己的 rank 设置为identity。 - 所以,当
ROUTER调用recv_multipart()时,它收到的消息结构是:[<identity_frame>, <empty_frame>, <message_content>]。 - 效果: 服务端可以通过读取第一个帧,准确地知道“这是谁发来的消息”。
- 当一个客户端(通常是
-
精确路由回复:
- 当
ROUTER服务端想要回复一个消息时,它必须使用send_multipart(),并且消息的格式必须是:[<identity_frame_of_recipient>, <empty_frame>, <reply_content>]。 ROUTER会读取第一个帧(身份帧),并确保这条回复消息只会被发送给具有该身份的那个客户端。- 效果: 服务端可以与多个客户端同时通信,并且能够进行精确的、点对点的回复,而不会发生混淆。
- 当
为什么在 vLLM 的握手场景中 ROUTER 是必需的?
在 wait_for_engine_startup 的握手过程中,主节点需要处理以下任务:
- 接收报到: 多个
Engine Core(客户端)会几乎同时发来 “HELLO” 消息。主节点需要区分哪个 “HELLO” 来自 rank 0,哪个来自 rank 1,哪个来自远程的 rank 2… - 发送配置: 在收到一个
Engine Core的 “HELLO” 后,主节点需要将包含DP Coordinator地址的配置信息只发送回给那个特定的Engine Core。如果把配置信息广播给所有Engine Core,虽然在这个场景下问题不大,但不是一个好的设计,而且在其他场景下会引发严重问题。 - 接收就绪信号: 主节点需要接收每个
Engine Core发来的 “READY” 消息,并更新对应Engine Core的状态。
ROUTER 套接字完美地满足了这些需求:
- 当
Engine Core(使用DEALER套接字) 发送 “HELLO” 时,handshake_socket(ROUTER) 收到的第一帧就是Engine Core的 rank (eng_identity)。 wait_for_engine_startup函数可以据此知道是哪个Engine Core报到了。- 当它需要回复配置时,它将
eng_identity作为send_multipart()的第一个帧,确保了配置信息被准确路由回正确的Engine Core。
# wait_for_engine_startup 简化逻辑
# 1. 接收消息,第一帧就是身份
eng_identity, ready_msg_bytes = handshake_socket.recv_multipart()
# 2. 根据身份解析
eng_index = int.from_bytes(eng_identity, "little")
# ... 处理消息 ...
# 3. 精确回复,将身份帧放在最前面
handshake_socket.send_multipart((eng_identity, init_message), copy=False)
与其他套接字类型的对比
-
为什么不用
REP(Reply)?REP套接字强制执行严格的“请求-响应”(recv-send-recv-send...)循环。REP服务器一次只能处理一个请求。在收到一个请求后,它必须发送一个回复,然后才能接收下一个请求。- 这不适用于 vLLM 的场景,因为多个
Engine Core会并发地发送 “HELLO” 消息。如果使用REP,当第一个Engine Core发来 “HELLO” 后,在主节点回复之前,其他所有Engine Core的 “HELLO” 都会被阻塞,导致启动变慢甚至死锁。ROUTER是完全异步的,可以随时接收来自任何客户端的消息。
-
为什么不用
PULL?PULL套接字用于从多个PUSH源接收数据,形成一个单向的管道。PULL套接字无法知道消息的来源,也无法回复消息。它只是一个纯粹的、匿名的消息汇集点。- 这显然不满足握手过程中需要身份识别和点对点回复的需求。
-
为什么客户端用
DEALER而不是REQ?DEALER是ROUTER的天然搭档。它也是完全异步的,可以随时发送消息,而不用等待回复。REQ套接字和REP一样,也强制执行send-recv-send-recv...的循环。如果Engine Core使用REQ,它在发送 “HELLO” 之后就必须阻塞等待回复,然后才能发送 “READY”,这会限制异步能力。使用DEALER,Engine Core可以在发送 “HELLO” 后继续做其他事,异步地等待回复。
结论
在 ZMQ 中,ROUTER-DEALER 组合是构建健壮、异步、多客户端的服务器的黄金搭档。
在 vLLM 的握手场景中,主节点作为中心服务器,需要同时处理来自多个 Engine Core 客户端的连接和消息,并能对每个客户端进行独立的、精确的响应。zmq.ROUTER 是唯一能完美满足“识别来源”和“精确路由”这两个核心需求的套接字类型。
好的,我们来逐段详细解释这段代码的含义。这段代码位于 launch_core_engines 函数中,它的核心作用是确定当前这个 vLLM 进程需要与哪些 Engine Core 进程进行握手(handshake)。
这个决策逻辑根据不同的部署模式(离线模式、内部负载均衡、外部负载均衡等)而有所不同。让我们分解来看:
上下文理解
在进入代码细节之前,先理解几个关键变量:
offline_mode: 是否为离线推理模式。在这种模式下,通常没有 API 服务器,每个进程独立工作。dp_rank: 当前这个vllm serve进程在数据并行(DP)全局中的 rank(索引)。从 0 开始。dp_size: 数据并行的总大小,即Engine Core的总数量。local_engine_count: 将要在这个节点上启动的Engine Core的数量。local_engines_only: 一个布尔值,用于区分不同的负载均衡模式。
if offline_mode:
if offline_mode:
assert local_engine_count == 1
engines_to_handshake = [CoreEngine(index=dp_rank, local=True)]
- 含义: 这是处理离线推理的场景。
- 逻辑: 在离线模式下,每个 DP 进程通常只管理一个与自己 rank 相同的
Engine Core。它们之间没有复杂的协调关系。 - 代码解释:
assert local_engine_count == 1: 确认在这种模式下,本地只会启动一个Engine Core。engines_to_handshake = [CoreEngine(index=dp_rank, local=True)]: 这段代码的意思是:“我是一个离线推理进程,我的 rank 是dp_rank。我只需要和我自己启动的那个、与我同 rank 的Engine Core进行握手,确认它已准备就绪就行了。我不需要关心其他任何Engine Core。”
elif dp_rank == 0:
elif dp_rank == 0:
# Rank 0 holds Coordinator, so it handshakes with all Cores
# in both external dplb and internal dplb mode.
# Note this also covers the case where we have zero local engines
# and rank 0 is headless.
engines_to_handshake = [
CoreEngine(index=i, local=(i < local_engine_count)) for i in range(dp_size)
]
- 含义: 这是处理**主节点(rank 0)的场景。在任何数据并行部署中,
rank 0进程都扮演着“总协调者”**的角色。 - 逻辑:
rank 0进程负责启动DP Coordinator。- 它需要确保所有的
Engine Core(无论是在本地还是在远程节点上)都已成功启动并连接到协调系统。 - 因此,它必须与集群中的每一个
Engine Core进行握手。
- 代码解释:
engines_to_handshake = [...] for i in range(dp_size): 创建一个包含所有Engine Core的列表,从 rank 0 到dp_size - 1。这表明它期望收到来自所有Engine Core的报到。local=(i < local_engine_count): 这是一个巧妙的判断。rank 0进程知道前local_engine_count个Engine Core是在它自己的节点上启动的(本地的),而其余的都是远程的。它会用这个local标志来追踪本地和远程Engine Core的启动进度。- 一个特殊情况: 注释中提到,这也覆盖了
rank 0自身是headless(即local_engine_count为 0)的情况。此时,rank 0进程只作为协调者存在,它仍然需要与所有(此时全都是远程的)Engine Core进行握手。
else: (即 dp_rank > 0)
else:
# Rank > 0 handshakes with just the local cores it is managing.
assert local_engines_only, (
"Attempting to launch core_engines from dp_rank > 0, but "
"found internal DPLB, which is incompatible."
)
engines_to_handshake = [
CoreEngine(index=i, local=True)
for i in range(dp_rank, dp_rank + local_engine_count)
]
- 含义: 这是处理非主节点(rank > 0),也就是计算节点的场景。
- 逻辑: 一个非主节点的
vllm serve进程,其职责是管理好在它自己节点上启动的那些Engine Core。它不需要像rank 0那样关心整个集群的状态。 - 代码解释:
assert local_engines_only, ...: 这是一个重要的断言。它检查是否处于local_engines_only模式(通常意味着外部或混合负载均衡)。在这种模式下,一个rank > 0的进程是允许存在的,它只管理本地引擎。如果不是这种模式(即是内部负载均衡),那么所有的协调都应该由rank 0完成,rank > 0的进程根本不应该走到这一步,所以会报错。engines_to_handshake = [...] for i in range(dp_rank, dp_rank + local_engine_count): 这段代码的意思是:“我是一个计算节点,我的起始 rank 是dp_rank,我负责启动local_engine_count个Engine Core。因此,我只需要与我负责的这些Engine Core(它们的 rank 范围是[dp_rank, dp_rank + local_engine_count))进行握手,确保它们都已准备好就行了。至于集群里的其他Engine Core,那是rank 0的事,我不管。”local=True: 因为这些Engine Core都是在本节点上启动的,所以local标志自然是True。
总结
这段代码是一个职责划分的逻辑开关。它根据当前进程的角色(离线工作者、集群总指挥、普通计算节点)来精确地定义它的“握手范围”:
- 离线工作者: 只关心自己。
- 集群总指挥 (rank 0): 必须关心所有人(所有
Engine Core)。 - 普通计算节点 (rank > 0): 只关心自己手下的人(在自己节点上启动的
Engine Core)。
通过这种方式,vLLM 确保了在复杂的分布式部署中,每个进程都有明确的职责,启动和同步过程既完整又高效。
这是一个非常好的问题,因为它触及了理解这段代码的关键!
这里的**“我”指的是当前正在执行 launch_core_engines 这个函数的那个 vllm serve 进程**。
让我们把这个概念具象化。
场景重现
回想一下我们在多节点部署时执行的命令:
在主节点 (Node 0) 上,你输入了:
vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345
- 这个命令启动了一个进程。在这个进程的上下文中,
dp_rank是0(默认值)。 - 当这个进程执行到我们讨论的代码块时,它会进入
elif dp_rank == 0:这个分支。 - 这里的“我”就是主节点上的
vllm serve进程。它的任务是与所有 4 个Engine Core握手。
在计算节点 (Node 1) 上,你输入了:
vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \
--data-parallel-start-rank 2 \
--data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345
- 这个命令也启动了一个进程。在这个进程的上下文中,
dp_rank是2(由--data-parallel-start-rank 2指定)。 - 当这个进程执行到我们讨论的代码块时,它会进入
else:(dp_rank > 0) 这个分支。 - 这里的“我”就是计算节点上的
vllm serve --headless进程。它的任务是只与它自己负责的、从 rank 2 开始的 2 个Engine Core(即 rank 2 和 rank 3)进行握手。
进程关系图
为了更清晰地理解,我们可以画一个简化的进程关系图:
+----------------------------------- Node 0 ------------------------------------+
| |
| +---------------------------+ |
| | vllm serve (dp_rank=0) | <--- "我" (主节点) |
| | (The Coordinator Process) | |
| +---------------------------+ |
| | (forks) |
| +----------------------> +------------------+ |
| | | Engine Core (r=0)| <--\ |
| | (forks) +------------------+ | |
| +----------------------> +------------------+ | 主节点的"我" |
| | Engine Core (r=1)| <--+ 需要与这4个握手 |
| +------------------+ | |
| <--/ |
| <--\ (via network) |
+--------------------------------------------------------------------------------+
|
+----------------------------------- Node 1 ------------------------------------+
| |
| +--------------------------------+ |
| | vllm serve --headless (dp_rank=2)| <--- "我" (计算节点) |
| | (The Worker Launcher Process) | |
| +--------------------------------+ |
| | (forks) |
| +-------------------------> +------------------+ |
| | | Engine Core (r=2)| <--\ 计算节点的"我" |
| | (forks) +------------------+ | 只需要与这2个握手|
| +-------------------------> +------------------+ | |
| | Engine Core (r=3)| <--/ |
| +------------------+ |
| |
+--------------------------------------------------------------------------------+
总结一下:
vllm serve命令本身会启动一个父进程/管理进程。- 这个父进程会根据自己的
dp_rank来确定自己的角色。 - 这个父进程就是代码逻辑中的“我”。
- 然后,“我”会创建(
fork)它所负责的Engine Core子进程,并与它们进行握手,以确认它们已准备就绪。
所以,在 else: 分支中,“我”特指那个在计算节点上运行的、dp_rank > 0 的、通常是 --headless 的 vllm serve 进程。它的职责范围被限定在管理本节点的资源上。
bash vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \ --data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345 […Truncated 6 lines…] vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \ --data-parallel-start-rank 2 \ --data-parallel-address 10.0.0.1 --data-parallel-rpc-port 13345 — 这里的“我”就是计算节点上的 vllm serve --headless 进程。它的任务是只与它自己负责的、从 rank 2 开始的 2 个 Engine Core(即 rank 2 和 rank 3)进行握手。 节点上的哪个进程会分别与 Engincore进程握手。 节点0 已经和所有Engincore 握手了, 节点1 还会和本地的握手吗,为什么,更新到文档中
这是local 场景下节点1 要与其他节点通信
节点握手机制详解
在您描述的跨节点部署场景中,握手机制如下:
Node 0 (主节点) 的握手行为
Node 0 上的 launch_core_engines 函数会与所有 Engine Core 进行握手: 1
elif dp_rank == 0:
# Rank 0 holds Coordinator, so it handshakes with all Cores
# in both external dplb and internal dplb mode.
engines_to_handshake = [
CoreEngine(index=i, local=(i < local_engine_count)) for i in range(dp_size)
]
Node 1 (计算节点) 的握手行为
Node 1 上的 run_headless 进程创建 CoreEngineProcManager,该管理器负责与本地的 Engine Core (rank 2 和 3) 握手: 2
engine_manager = CoreEngineProcManager(
target_fn=EngineCoreProc.run_engine_core,
local_engine_count=local_engine_count,
start_index=vllm_config.parallel_config.data_parallel_rank,
local_start_index=0,
vllm_config=vllm_config,
local_client=False,
handshake_address=handshake_address,
executor_class=Executor.get_class(vllm_config),
log_stats=not engine_args.disable_log_stats,
)
为什么 Node 1 还需要与本地 Engine Core 握手?
- 进程管理需要:Node 1 上的
run_headless进程需要启动和管理本地的 Engine Core 进程 - 状态同步:确保本地 Engine Core 正确初始化并返回就绪状态
- 资源分配:验证本地 GPU 资源和 KV 缓存配置
完整握手流程
关键代码位置
Notes
总结:Node 1 上的 run_headless 进程会与本地 Engine Core 进行握手,这是为了确保本地进程正确启动和初始化。虽然 Node 0 已经与所有 Engine Core 完成了握手用于建立通信连接,但 Node 1 仍需要与本地引擎进行握手来管理进程生命周期和状态同步。
Wiki pages you might want to explore:
Wiki pages you might want to explore:
Citations
File: vllm/v1/engine/utils.py (L864-880)
# Rank 0 holds Coordinator, so it handshakes with all Cores
# in both external dplb and internal dplb mode.
# Note this also covers the case where we have zero local engines
# and rank 0 is headless.
engines_to_handshake = [
CoreEngine(index=i, local=(i < local_engine_count)) for i in range(dp_size)
]
else:
# Rank > 0 handshakes with just the local cores it is managing.
assert local_engines_only, (
"Attempting to launch core_engines from dp_rank > 0, but "
"found internal DPLB, which is incompatible."
)
engines_to_handshake = [
CoreEngine(index=i, local=True)
for i in range(dp_rank, dp_rank + local_engine_count)
]
File: vllm/v1/engine/utils.py (L937-950)
def wait_for_engine_startup(
handshake_socket: zmq.Socket,
addresses: EngineZmqAddresses,
core_engines: list[CoreEngine],
parallel_config: ParallelConfig,
coordinated_dp: bool,
cache_config: CacheConfig,
proc_manager: CoreEngineProcManager | None,
coord_process: Process | None,
):
# Wait for engine core process(es) to send ready messages.
local_count = parallel_config.data_parallel_size_local
remote_count = len(core_engines) - local_count
# [local, remote] counts
File: vllm/entrypoints/cli/serve.py (L199-209)
engine_manager = CoreEngineProcManager(
target_fn=EngineCoreProc.run_engine_core,
local_engine_count=local_engine_count,
start_index=vllm_config.parallel_config.data_parallel_rank,
local_start_index=0,
vllm_config=vllm_config,
local_client=False,
handshake_address=handshake_address,
executor_class=Executor.get_class(vllm_config),
log_stats=not engine_args.disable_log_stats,
)
您观察得非常敏锐,并且准确地抓住了问题的关键!是的,您说得完全正确。
rank > 0 的 vllm serve 进程只与它自己本地的 Engine Core 进行握手,这种行为是特定于某些部署模式的,特别是那些 local_engines_only 为 True 的场景。
让我们来深入解析 assert local_engines_only 这句代码,因为它正是这个逻辑的“守门员”。
local_engines_only 是什么?
这个布尔标志 local_engines_only 是 ParallelConfig 的一个属性,它用来区分两种主要的多节点 DP 部署模式:
-
内部负载均衡 (Internal Load Balancing)
- 在这种模式下,只有一个地方有
API Server和DP Coordinator,那就是rank 0的主节点。 - 主节点上的
API Server会直接与所有的Engine Core(包括远程节点上的)进行通信和负载均衡。 - 在这种架构下,计算节点(
rank > 0)上运行的vllm serve --headless进程的角色非常纯粹:它只需要启动本地的Engine Core进程,然后这些Engine Core进程会自己去和主节点报到。计算节点上的父进程(vllm serve --headless)在启动完子进程后,就不再参与后续的协调工作了。 - 在这种模式下,
local_engines_only通常是False。
- 在这种模式下,只有一个地方有
-
外部/混合负载均衡 (External/Hybrid Load Balancing)
- 在这种模式下,架构更加去中心化。每个节点(或每组节点)可能会有自己的“小前端”或 API 入口。
- 一个
rank > 0的进程可能不仅仅是启动Engine Core,它可能还需要运行一个本地的API Server,这个API Server只服务于它本地的Engine Core。 - 在这种情况下,这个
rank > 0的进程就需要自己确认本地的Engine Core是否准备就绪,因为它要直接使用它们。 - 在这种模式下,
local_engines_only会被设置为True。
assert local_engines_only 的作用
现在我们来看 else: 分支中的那句断言:
else: # (即 dp_rank > 0)
# Rank > 0 handshakes with just the local cores it is managing.
assert local_engines_only, (
"Attempting to launch core_engines from dp_rank > 0, but "
"found internal DPLB, which is incompatible."
)
# ...
这句代码的意思是:
“如果我是一个
rank > 0的进程,并且我正准备启动core_engines,那么我必须处于一个local_engines_only的模式下。如果我发现当前是内部负载均衡模式(local_engines_only为False),那肯定是哪里搞错了,因为在内部负载均衡模式下,所有的协调和握手都应该由rank 0的主节点统一完成,我作为一个rank > 0的进程根本不应该走到这一步来尝试自己进行握手。所以,我必须立即报错退出。”
换句话说,rank > 0 的进程自己去和本地 Engine Core 握手的行为,是为“外部/混合负载均衡”这种更复杂的、分片式的部署模式设计的。
在最常见的内部负载均衡多节点部署场景中:
- 主节点 (rank 0): 执行
elif dp_rank == 0:分支,准备与所有Engine Core握手。 - 计算节点 (rank > 0): 它的
vllm serve --headless进程在launch_core_engines函数中会因为assert local_engines_only失败而报错吗?不会。 因为在内部负载均衡的典型设置下,rank > 0的vllm serve --headless进程的职责更加简化,它可能根本就不会调用到launch_core_engines这个复杂的协调函数,或者在调用时local_engines_only会是True。它的主要任务就是根据命令行参数启动CoreEngineProcManager,然后由CoreEngineProcManager启动的子进程自己去连接主节点。
结论
您完全正确。rank > 0 进程与它本地的 Engine Core 进行握手,是特定于 local_engines_only 场景的。
在标准的、集中的内部负载均衡模式下,所有握手和协调的“重担”都压在了 rank 0 主节点身上,而 rank > 0 的计算节点则扮演着更纯粹的“启动器”角色,它启动完本地的 Engine Core 之后,这些 Engine Core 就像被放出巢的信鸽,会自己飞向主节点去报到。这个 assert 语句正是保证了这种职责划分的正确性。
coord_socket.send(b"\x01")
HELLO/READY 握手机制
HELLO/READY 握手是 EngineCore 与 Frontend 进程 之间的通信机制,不是直接与 API Server。 1
Frontend 与 API Server 的区别
Frontend 进程的定义
Frontend 是一个更广泛的概念,根据部署场景可以指代不同的进程: 2
"""
Here, "front-end" process can mean the process containing the engine
core client (which is the API server process in the case the API
server is not scaled out), OR the launcher process running the
run_multi_api_server() function in serve.py.
"""
具体场景
- 单 API Server 场景:Frontend = API Server 进程
- 多 API Server 场景:Frontend = Launcher 进程 (
run_multi_api_server)
握手流程
关键代码位置
Notes
总结:HELLO/READY 是 EngineCore 与其管理进程(Frontend)之间的握手协议。在大多数情况下,Frontend 就是 API Server 进程或管理 API Server 的 Launcher 进程。这个握手机制用于建立通信连接和交换初始化配置信息。 6
Wiki pages you might want to explore:
Citations
File: vllm/v1/engine/core.py (L834-837)
Here, "front-end" process can mean the process containing the engine
core client (which is the API server process in the case the API
server is not scaled out), OR the launcher process running the
run_multi_api_server() function in serve.py.
File: vllm/v1/engine/core.py (L892-912)
# Send ready message.
num_gpu_blocks = vllm_config.cache_config.num_gpu_blocks
# We pass back the coordinator stats update address here for the
# external LB case for our colocated front-end to use (coordinator
# only runs with rank 0).
dp_stats_address = self.frontend_stats_publish_address
# Include config hash for DP configuration validation
ready_msg = {
"status": "READY",
"local": local_client,
"headless": headless,
"num_gpu_blocks": num_gpu_blocks,
"dp_stats_address": dp_stats_address,
}
if vllm_config.parallel_config.data_parallel_size > 1:
ready_msg["parallel_config_hash"] = (
vllm_config.parallel_config.compute_hash()
)
handshake_socket.send(msgspec.msgpack.encode(ready_msg))
File: vllm/v1/engine/core.py (L914-950)
@staticmethod
def startup_handshake(
handshake_socket: zmq.Socket,
local_client: bool,
headless: bool,
parallel_config: ParallelConfig | None = None,
) -> EngineZmqAddresses:
# Send registration message.
handshake_socket.send(
msgspec.msgpack.encode(
{
"status": "HELLO",
"local": local_client,
"headless": headless,
}
)
)
# Receive initialization message.
logger.debug("Waiting for init message from front-end.")
if not handshake_socket.poll(timeout=HANDSHAKE_TIMEOUT_MINS * 60_000):
raise RuntimeError(
"Did not receive response from front-end "
f"process within {HANDSHAKE_TIMEOUT_MINS} "
f"minutes"
)
init_bytes = handshake_socket.recv()
init_message: EngineHandshakeMetadata = msgspec.msgpack.decode(
init_bytes, type=EngineHandshakeMetadata
)
logger.debug("Received init message: %s", init_message)
if parallel_config is not None:
for key, value in init_message.parallel_config.items():
setattr(parallel_config, key, value)
return init_message.addresses
File: vllm/v1/engine/utils.py (L990-1007)
# Receive HELLO and READY messages from the input socket.
eng_identity, ready_msg_bytes = handshake_socket.recv_multipart()
eng_index = int.from_bytes(eng_identity, "little")
engine = next((e for e in core_engines if e.identity == eng_identity), None)
if engine is None:
raise RuntimeError(
f"Message from engine with unexpected data parallel rank: {eng_index}"
)
msg = msgspec.msgpack.decode(ready_msg_bytes)
status, local, headless = msg["status"], msg["local"], msg["headless"]
if local != engine.local:
raise RuntimeError(
f"{status} message from "
f"{'local' if local else 'remote'} "
f"engine {eng_index}, expected it to be "
f"{'local' if engine.local else 'remote'}"
)
File: vllm/v1/engine/utils.py (L1023-1044)
if status == "HELLO" and engine.state == CoreEngineState.NEW:
# Send init message with DP config info.
init_message = msgspec.msgpack.encode(
EngineHandshakeMetadata(
addresses=addresses,
parallel_config={
k: getattr(parallel_config, k)
for k in (
"data_parallel_master_ip",
"data_parallel_master_port",
"_data_parallel_master_port_list",
"data_parallel_size",
)
}
if coordinated_dp
else {},
)
)
handshake_socket.send_multipart((eng_identity, init_message), copy=False)
conn_pending[0 if local else 1] -= 1
start_pending[0 if local else 1] += 1
engine.state = CoreEngineState.CONNECTED
DP Coordinator 与其他进程的关系
DP Coordinator 与其他进程的通信关系如下:
1. 与 Engine Core 的关系
DP Coordinator 不直接与 Engine Core 进行 HELLO/READY 握手,而是通过订阅机制建立连接:
# Coordinator 等待所有引擎订阅
for _ in self.engines:
if publish_back.recv() != b"\x01":
logger.error("DP Coordinator received unexpected message...")
return
# 发送 READY 消息给引擎
publish_back.send(b"READY")
```[1](#18-0)
Engine Core 通过 XSUB socket 订阅 Coordinator:
```python
coord_socket.send(b"\x01") # 发送订阅消息
assert coord_socket.recv() == b"READY" # 等待 READY 消息
```[2](#18-1)
### 2. 与 API Server 的关系
DP Coordinator 作为**发布者**,API Server 作为**订阅者**,使用 XPUB/XSUB 模式:
- Coordinator 发布统计信息给 API Server
- API Server 订阅负载均衡更新
- 不使用 HELLO/READY 握手,而是发布-订阅模式
### 3. 握手机制对比
| 进程对 | 握手方式 | 消息格式 |
|--------|----------|----------|
| Engine Core ↔ Frontend | HELLO/READY | JSON 格式 |
| Engine Core ↔ Coordinator | 订阅机制 | `\x01` / `READY` |
| Coordinator ↔ API Server | 发布-订阅 | msgpack 编码 |
### 4. 完整通信流程
```mermaid
sequenceDiagram
participant EngineCore
participant DPCoordinator
participant APIServer
Note over EngineCore,DPCoordinator: 订阅建立
EngineCore->>DPCoordinator: 发送 \x01 (订阅)
DPCoordinator->>EngineCore: 发送 READY
Note over EngineCore,Frontend: HELLO/READY 握手
EngineCore->>Frontend: 发送 HELLO
Frontend->>EngineCore: 返回初始化消息
EngineCore->>Frontend: 发送 READY
Note over DPCoordinator,APIServer: 发布-订阅
DPCoordinator->>APIServer: 发布负载统计
APIServer->>DPCoordinator: 订阅更新
关键区别
DP Coordinator 使用的是订阅确认机制而非传统的 HELLO/READY 握手:
- Engine Core 发送
\x01表示订阅 - Coordinator 响应
READY表示接受订阅 - 这是一种轻量级的连接建立方式,专门用于发布-订阅模式
而 Engine Core 与 Frontend 进程之间使用完整的 HELLO/READY 握手机制来交换配置信息和初始化参数。 3
Wiki pages you might want to explore:
Citations
File: vllm/v1/engine/coordinator.py (L189-198)
# Wait until all engines subscribe.
for _ in self.engines:
if publish_back.recv() != b"\x01":
logger.error(
"DP Coordinator received unexpected message while "
"waiting for engines to subscribe"
)
return
# Send ready message to engines.
publish_back.send(b"READY")
File: vllm/v1/engine/core.py (L914-950)
@staticmethod
def startup_handshake(
handshake_socket: zmq.Socket,
local_client: bool,
headless: bool,
parallel_config: ParallelConfig | None = None,
) -> EngineZmqAddresses:
# Send registration message.
handshake_socket.send(
msgspec.msgpack.encode(
{
"status": "HELLO",
"local": local_client,
"headless": headless,
}
)
)
# Receive initialization message.
logger.debug("Waiting for init message from front-end.")
if not handshake_socket.poll(timeout=HANDSHAKE_TIMEOUT_MINS * 60_000):
raise RuntimeError(
"Did not receive response from front-end "
f"process within {HANDSHAKE_TIMEOUT_MINS} "
f"minutes"
)
init_bytes = handshake_socket.recv()
init_message: EngineHandshakeMetadata = msgspec.msgpack.decode(
init_bytes, type=EngineHandshakeMetadata
)
logger.debug("Received init message: %s", init_message)
if parallel_config is not None:
for key, value in init_message.parallel_config.items():
setattr(parallel_config, key, value)
return init_message.addresses
File: vllm/v1/engine/core.py (L1220-1235)
# Send subscription message to coordinator.
coord_socket.send(b"\x01")
# Register sockets with poller.
poller = zmq.Poller()
for input_socket in input_sockets:
# Send initial message to each input socket - this is required
# before the front-end ROUTER socket can send input messages
# back to us.
input_socket.send(b"")
poller.register(input_socket, zmq.POLLIN)
if coord_socket is not None:
# Wait for ready message from coordinator.
assert coord_socket.recv() == b"READY"
poller.register(coord_socket, zmq.POLLIN)
DP coordinator 进程和其他进程的关系 发布订阅,结合代码分析流程?

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 21
21 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)