【vllm】DP并行
内部负载均衡 (Internal Load Balancing)内部负载均衡 (Internal Load Balancing) 是 vLLM 数据并行部署的一种模式,其中系统在内部自动处理请求在多个数据并行引擎之间的分发,对外暴露单一的 API 端点。 1在内部负载均衡模式下,vLLM 通过以下组件实现负载均衡:DP Coordinator 进程:负责收集各 DP 引擎的统计信息并发布给前端进程
内部负载均衡 (Internal Load Balancing)
内部负载均衡 (Internal Load Balancing) 是 vLLM 数据并行部署的一种模式,其中系统在内部自动处理请求在多个数据并行引擎之间的分发,对外暴露单一的 API 端点。 1
工作原理
在内部负载均衡模式下,vLLM 通过以下组件实现负载均衡:
-
DP Coordinator 进程:负责收集各 DP 引擎的统计信息并发布给前端进程用于负载均衡决策 2
-
统计信息收集:每个 DP 引擎收集运行中和等待中的请求数量,通过 ZMQ 套接字发布给协调器 3
-
负载均衡决策:基于各引擎的队列状态和 KV 缓存状态进行智能请求分发 4
配置方式
内部负载均衡通过以下配置启用:
vllm serve $MODEL --data-parallel-size 4 --tensor-parallel-size 2
系统会根据配置自动判断是否使用内部负载均衡: 5
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
适用场景
内部负载均衡适用于:
- 单节点或多节点数据并行部署
- 需要简化部署架构的场景
- 中小规模的并行部署(API 服务器进程可能成为瓶颈时)
对于大规模部署,可以考虑使用 --api-server-count 进行 API 服务器扩展,或者切换到外部负载均衡模式 6 。
Notes
内部负载均衡与外部负载均衡(External Load Balancing)和混合负载均衡(Hybrid Load Balancing)是 vLLM 提供的三种数据并行负载均衡模式。内部模式提供最简单的部署体验,而外部模式更适合大规模生产环境中的复杂负载均衡需求。
Wiki pages you might want to explore:
Citations
File: docs/serving/data_parallel_deployment.md (L17-18)
In all cases, it is beneficial to load-balance requests between DP ranks. For online deployments, this balancing can be optimized by taking into account the state of each DP engine - in particular its currently scheduled and waiting (queued) requests, and KV cache state. Each DP engine has an independent KV cache, and the benefit of prefix caching can be maximized by directing prompts intelligently.
File: docs/serving/data_parallel_deployment.md (L23-27)
## Internal Load Balancing
vLLM supports "self-contained" data parallel deployments that expose a single API endpoint.
It can be configured by simply including e.g. `--data-parallel-size=4` in the vllm serve command line arguments. This will require 4 GPUs. It can be combined with tensor parallel, for example `--data-parallel-size=4 --tensor-parallel-size=2`, which would require 8 GPUs. When sizing DP deployments, remember that `--max-num-seqs` applies per DP rank.
File: docs/serving/data_parallel_deployment.md (L75-78)
Currently, the internal DP load balancing is done within the API server process(es) and is based on the running and waiting queues in each of the engines. This could be made more sophisticated in future by incorporating KV cache aware logic.
When deploying large DP sizes using this method, the API server process can become a bottleneck. In this case, the orthogonal `--api-server-count` command line option can be used to scale this out (for example `--api-server-count=4`). This is transparent to users - a single HTTP endpoint / port is still exposed. Note that this API server scale-out is "internal" and still confined to the "head" node.
File: vllm/v1/engine/coordinator.py (L22-31)
class DPCoordinator:
"""Coordinator process used for data-parallel deployments (DP>1).
Intermediates between multiple DP engine rank processes and one or more
front-end API server processes.
* Collects stats from each DP engine (currently just waiting and running
queue lengths), and publishes these to all front-ends for use in
load-balancing decisions.
File: vllm/v1/engine/core_client.py (L1093-1082)
File: vllm/v1/engine/core.py (L753-759)
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
# Only publish request queue stats to coordinator for "internal"
# and "hybrid" LB modes.
self.publish_dp_lb_stats = internal_dp_balancing
对外暴露单一的 API 端点, 什么是单一的API断点, API端点是什么,代码怎么实现的
单一 API 端点的含义
单一 API 端点指的是 vLLM 在内部负载均衡模式下,虽然底层可能有多个数据并行引擎和多个 API 服务器进程,但对客户端只暴露一个统一的 HTTP 地址和端口(如 http://localhost:8000),客户端只需连接这一个端点即可使用所有服务。 1
API 端点的概念
API 端点是 HTTP 服务器监听的网络地址,通常由 IP 地址和端口组成。在 vLLM 中,API 端点提供 OpenAI 兼容的 REST API 接口,包括:
/v1/completions- 文本补全/v1/chat/completions- 对话补全/v1/models- 模型列表/health- 健康检查 2
代码实现
1. 服务器启动和监听
API 服务器通过 FastAPI 创建并监听指定端口:
# vllm/entrypoints/openai/api_server.py
app = FastAPI()
# 服务器启动时会监听配置的端口(默认8000)
2. 多 API 服务器进程管理
当使用 --api-server-count > 1 时,系统会启动多个 API 服务器进程,但它们共享同一个监听端口:
# vllm/entrypoints/cli/serve.py:218-287
def run_multi_api_server(args: argparse.Namespace):
num_api_servers: int = args.api_server_count
# 设置共享的监听地址和socket
listen_address, sock = setup_server(args)
# 启动多个API服务器进程管理器
api_server_manager = APIServerProcessManager(
target_server_fn=run_api_server_worker_proc,
listen_address=listen_address,
sock=sock, # 共享同一个socket
num_servers=num_api_servers,
# ...
)
3. 负载均衡实现
多个 API 服务器进程通过共享 socket 接收请求,操作系统内核自动进行负载均衡。每个 API 服务器进程连接到所有数据并行引擎:
# vllm/v1/engine/utils.py:810-820
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers) # 每个API服务器都有输入地址
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers) # 每个API服务器都有输出地址
],
)
4. 进程架构
典型的内部负载均衡部署架构: 3
| 进程类型 | 数量 | 作用 |
|---|---|---|
| API 服务器 | A (默认等于 DP 大小) |
处理 HTTP 请求,暴露单一端点 |
| 引擎核心 | DP |
调度和 KV 缓存管理 |
| GPU 工作进程 | N (= DP × TP) |
执行模型前向传播 |
| DP 协调器 | 1 (如果 DP > 1) | 跨 DP 秩的负载均衡 |
Notes
单一 API 端点的优势是简化客户端配置,客户端无需知道后端的复杂架构。即使内部有多个 API 服务器进程和数据并行引擎,客户端仍然只需要连接一个地址。这种设计对用户透明,提供了简单的部署体验。 4
Wiki pages you might want to explore:
Citations
File: docs/serving/data_parallel_deployment.md (L23-27)
## Internal Load Balancing
vLLM supports "self-contained" data parallel deployments that expose a single API endpoint.
It can be configured by simply including e.g. `--data-parallel-size=4` in the vllm serve command line arguments. This will require 4 GPUs. It can be combined with tensor parallel, for example `--data-parallel-size=4 --tensor-parallel-size=2`, which would require 8 GPUs. When sizing DP deployments, remember that `--max-num-seqs` applies per DP rank.
File: docs/serving/data_parallel_deployment.md (L75-78)
Currently, the internal DP load balancing is done within the API server process(es) and is based on the running and waiting queues in each of the engines. This could be made more sophisticated in future by incorporating KV cache aware logic.
When deploying large DP sizes using this method, the API server process can become a bottleneck. In this case, the orthogonal `--api-server-count` command line option can be used to scale this out (for example `--api-server-count=4`). This is transparent to users - a single HTTP endpoint / port is still exposed. Note that this API server scale-out is "internal" and still confined to the "head" node.
File: docs/serving/openai_compatible_server.md (L43-60)
## Supported APIs
We currently support the following OpenAI APIs:
- [Completions API](#completions-api) (`/v1/completions`)
- Only applicable to [text generation models](../models/generative_models.md).
- *Note: `suffix` parameter is not supported.*
- [Responses API](#responses-api) (`/v1/responses`)
- Only applicable to [text generation models](../models/generative_models.md).
- [Chat Completions API](#chat-api) (`/v1/chat/completions`)
- Only applicable to [text generation models](../models/generative_models.md) with a [chat template](../serving/openai_compatible_server.md#chat-template).
- *Note: `user` parameter is ignored.*
- *Note:* Setting the `parallel_tool_calls` parameter to `false` ensures vLLM only returns zero or one tool call per request. Setting it to `true` (the default) allows returning more than one tool call per request. There is no guarantee more than one tool call will be returned if this is set to `true`, as that behavior is model dependent and not all models are designed to support parallel tool calls.
- [Embeddings API](#embeddings-api) (`/v1/embeddings`)
- Only applicable to [embedding models](../models/pooling_models.md).
- [Transcriptions API](#transcriptions-api) (`/v1/audio/transcriptions`)
- Only applicable to [Automatic Speech Recognition (ASR) models](../models/supported_models.md#transcription).
- [Translation API](#translations-api) (`/v1/audio/translations`)
File: docs/design/arch_overview.md (L117-127)
### Process Count Summary
For a deployment with `N` GPUs, `TP` tensor parallel size, `DP` data parallel size, and `A` API server count:
| Process Type | Count | Notes |
|---|---|---|
| API Server | `A` (default `DP`) | Handles HTTP requests and input processing |
| Engine Core | `DP` (default 1) | Scheduler and KV cache management |
| GPU Worker | `N` (= `DP x TP`) | One per GPU, executes model forward passes |
| DP Coordinator | 1 if `DP > 1`, else 0 | Load balancing across DP ranks |
| **Total** | **`A + DP + N` (+ 1 if DP > 1)** | |
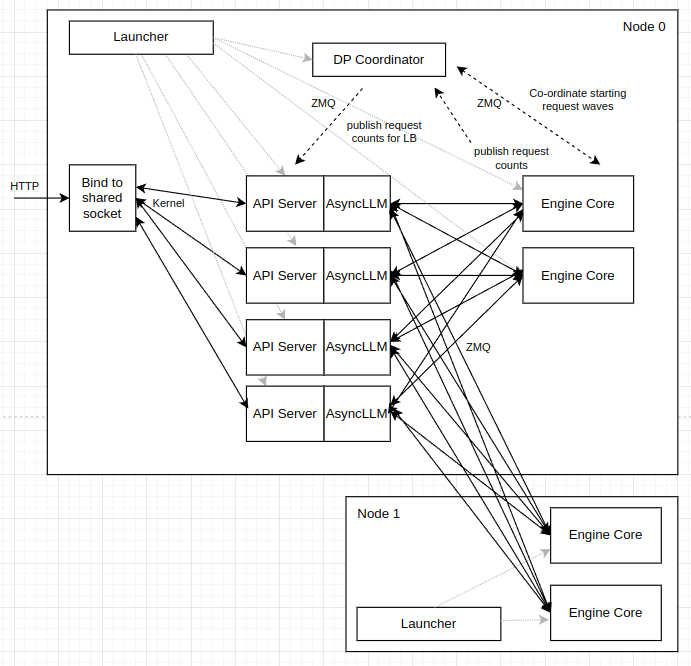
好的,我们来详细解释这张 vLLM 数据并行部署架构图。这张图展示了一个跨两个节点的、采用内部负载均衡的数据并行部署方案。
核心组件概览
这张图包含了几个关键的组件,分布在两个物理节点(Node 0 和 Node 1)上:
- Launcher: 启动器进程,负责在每个节点上启动 vLLM 服务。
- API Server (AsyncLLM): 前端进程,接收外部 HTTP 请求,并与后端的 Engine Core 通信。这里显示了多个 API Server 实例,表示 API 服务本身也可以横向扩展。
- Engine Core: 后端计算核心,负责实际的模型推理。每个 Engine Core 都是一个独立的数据并行(DP)单元。
- DP Coordinator: 数据并行协调器,一个独立的进程,用于在所有 Engine Core 和 API Server 之间同步状态和协调工作。
- Bind to shared socket: 一个操作系统级别的机制,允许多个 API Server 进程监听同一个网络端口。
工作流程和交互详解
我们按照数据流和控制流的路径来解读这张图:
1. 启动流程 (Launcher)
- 在 Node 0 和 Node 1 上,
Launcher进程(即用户执行的vllm serve ...命令)被分别启动。 - Node 0 的 Launcher(主节点)负责启动:
DP Coordinator进程。- 多个
API Server进程。 - Node 0 上的
Engine Core进程(在此图中是 2 个)。
- Node 1 的 Launcher 负责启动:
- Node 1 上的
Engine Core进程(在此图中也是 2 个)。它以--headless模式运行,意味着不启动 API Server。
- Node 1 上的
- 虚线箭头从
Launcher指向其他组件,表示这种“创建”或“启动”关系。
2. 外部 HTTP 请求处理
- 外部的
HTTP请求到达 Node 0。 Bind to shared socket机制(通常是 Linux 内核的SO_REUSEPORT特性)允许多个API Server进程绑定到同一个端口(例如 8000)。- Kernel(操作系统内核)会将传入的 HTTP 连接以轮询(Round-Robin)的方式分发给其中一个
API Server进程,实现了第一层的负载均衡。
3. API Server 与 Engine Core 的交互 (核心数据流)
- 当一个
API Server收到一个 HTTP 请求后,它内部的AsyncLLM实例需要将这个请求发送给一个Engine Core进行处理。 - 负载均衡决策: 在发送之前,
API Server需要决定将请求发往哪个Engine Core。这个决策是基于从DP Coordinator获取的信息(详见第 4 点)。 - 通信方式:
API Server和Engine Core之间通过 ZMQ 套接字进行通信。图中的实线黑箭头表示了这种通信关系。 - 全连接网络: 注意,每个
API Server都可以与所有的Engine Core(包括 Node 0 和 Node 1 上的)直接通信。这是一个全连接的网络拓扑,为动态负载均衡提供了基础。一个请求可以被 Node 0 上的 API Server 接收,然后被发送到 Node 1 上的 Engine Core 去处理。
4. DP Coordinator 的协调作用 (核心控制流)
DP Coordinator 是整个数据并行架构的“大脑”,负责两件大事,图中用虚线箭头表示:
-
A. 发布请求计数用于负载均衡 (publish request counts for LB)
- 每个
Engine Core会定期向DP Coordinator上报 (publish) 自己的负载状态,主要是正在运行 (running) 和等待中 (waiting) 的请求数量。 DP Coordinator收集并聚合所有Engine Core的状态。- 然后,
DP Coordinator将这个全局的负载视图广播 (publish) 给所有订阅了它的API Server。 API Server收到这些最新的负载计数后,就可以做出智能的负载均衡决策,例如,将新请求发送到当前负载最低(等待队列最短)的Engine Core。
- 每个
-
B. 协调请求波次 (Co-ordinate starting request waves)
- 这主要用于 MoE 模型。为了保证所有 DP rank 的同步,即使某些
Engine Core没有请求,也需要执行“虚拟”前向传播。 DP Coordinator维护一个全局的“运行/暂停”状态和“请求波次 (request wave)”编号。- 当所有
Engine Core都空闲时,DP Coordinator会将全局状态标记为“暂停”。 - 当一个处于“暂停”状态的
API Server收到新请求时,它会通知DP Coordinator。 DP Coordinator随即向所有的Engine Core广播一个“开始新波次 (START_DP_WAVE)”的命令,唤醒所有Engine Core,使其进入同步运行状态。Engine Core也会在特定情况下(例如收到过时的请求)通知DP Coordinator,以处理竞态条件。
- 这主要用于 MoE 模型。为了保证所有 DP rank 的同步,即使某些
总结
这张架构图描绘了一个高度可扩展和健壮的 vLLM 部署方案:
- 横向扩展:
- API 服务层: 通过
Bind to shared socket和增加API Server进程数量(--api-server-count)来实现。 - 计算层: 通过增加
Engine Core数量(--data-parallel-size)和增加节点来实现。
- API 服务层: 通过
- 解耦: 前端(API Server)和后端(Engine Core)是完全解耦的独立进程,可以通过网络进行灵活部署。
- 智能负载均衡:
DP Coordinator作为中央协调者,收集全局状态并指导API Server进行负载均衡,从而优化资源利用率和吞- 吐量。 - 同步机制: 对于需要同步的 MoE 模型,
DP Coordinator通过“请求波次”机制确保所有 DP rank 的正确执行。
简而言之,这是一个典型的“控制器-工作者” (Controller-Worker) 模式,其中 API Server 和 Engine Core 是工作者,而 DP Coordinator 则是控制器,通过 ZMQ 这个高性能的消息总线将它们联系在一起。
内部负载均衡实现详解
关键数据结构
1. EngineState
class EngineState:
def __init__(self):
self.request_counts = [0, 0] # [waiting, running]
```[1](#2-0)
#### 2. EngineZmqAddresses
管理ZMQ通信地址,包含输入、输出和协调器地址:
```python
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
```[2](#2-1)
#### 3. 负载均衡统计
每个引擎维护waiting和running队列长度,用于负载均衡决策:
```python
waiting, running = current_counts[idx]
score = waiting * 4 + running
```[3](#2-2)
### 涉及的进程架构
| 进程类型 | 数量 | 作用 |
|---------|------|------|
| API Server | `A` (默认等于DP大小) | 处理HTTP请求,负载均衡决策 |
| Engine Core | `DP` | 调度和KV缓存管理 |
| GPU Worker | `N` (= `DP × TP`) | 执行模型前向传播 |
| DP Coordinator | 1 (如果DP > 1) | 收集统计信息,协调请求波次 | [4](#2-3)
### 完整流程
#### 1. 初始化阶段
```mermaid
sequenceDiagram
participant Main
participant DPCoordinator
participant EngineCore
participant APIServer
Main->>DPCoordinator: 启动协调器进程
Main->>EngineCore: 启动DP个引擎核心
Main->>APIServer: 启动A个API服务器
DPCoordinator->>APIServer: 发布统计信息地址
APIServer->>EngineCore: 建立ZMQ连接
2. 统计信息收集
每个引擎核心定期发布队列状态:
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
self.publish_dp_lb_stats = internal_dp_balancing
```[5](#2-4)
#### 3. 负载均衡决策
API服务器使用`DPLBAsyncMPClient`进行负载均衡:
```python
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
for i in range(num_engines):
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running
if score < min_score:
min_score = score
eng_index = idx
```[6](#2-5)
#### 4. 请求处理流程
```mermaid
sequenceDiagram
participant Client
participant APIServer
participant DPCoordinator
participant EngineCore
participant GPUWorker
Client->>APIServer: HTTP请求
APIServer->>APIServer: 选择最优引擎
APIServer->>EngineCore: 发送请求
EngineCore->>DPCoordinator: 更新队列状态
EngineCore->>GPUWorker: 执行模型
GPUWorker-->>EngineCore: 返回结果
EngineCore-->>APIServer: 返回输出
APIServer-->>Client: HTTP响应
关键实现细节
1. 协调器启动
coordinator = DPCoordinator(
parallel_config,
enable_wave_coordination=vllm_config.model_config.is_moe,
)
```[7](#2-6)
#### 2. 请求波次协调
对于MoE模型,协调器还负责请求波次同步:
```python
* Keeps track of the current DP "request wave" number and running state
of the engines. This is received from the DP rank 0 engine and published
to the front-end processes along with the current load stats.
```[8](#2-7)
#### 3. 统计信息发布
协调器收集并发布引擎统计信息:
```python
* Collects stats from each DP engine (currently just waiting and running
queue lengths), and publishes these to all front-ends for use in
load-balancing decisions.
```[9](#2-8)
## Notes
内部负载均衡的核心是通过DP Coordinator收集各引擎的队列状态,API服务器基于这些统计信息做出智能的请求分发决策。这种设计实现了对用户透明的单一API端点,同时充分利用了多个数据并行引擎的处理能力。 [10](#2-9)
Wiki pages you might want to explore:
- [Overview (vllm-project/vllm)](/wiki/vllm-project/vllm#1)
### Citations
**File:** vllm/v1/engine/coordinator.py (L28-30)
```python
* Collects stats from each DP engine (currently just waiting and running
queue lengths), and publishes these to all front-ends for use in
load-balancing decisions.
File: vllm/v1/engine/coordinator.py (L32-34)
* Keeps track of the current DP "request wave" number and running state
of the engines. This is received from the DP rank 0 engine and published
to the front-end processes along with the current load stats.
File: vllm/v1/engine/coordinator.py (L108-110)
class EngineState:
def __init__(self):
self.request_counts = [0, 0] # [waiting, running]
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/utils.py (L830-834)
if run_coordinator:
coordinator = DPCoordinator(
parallel_config,
enable_wave_coordination=vllm_config.model_config.is_moe,
)
File: vllm/v1/engine/core_client.py (L1242-1262)
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
# Engines are in rank order.
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines
# TODO use P2C alg for larger DP sizes
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
for i in range(num_engines):
# Start from client_index to help with balancing when engines
# are empty.
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running
if score < min_score:
min_score = score
eng_index = idx
# Increment local waiting count for better balancing between stats
# updates from the coordinator (which happen every 100ms).
current_counts[eng_index][0] += self.client_count
File: docs/design/arch_overview.md (L117-127)
### Process Count Summary
For a deployment with `N` GPUs, `TP` tensor parallel size, `DP` data parallel size, and `A` API server count:
| Process Type | Count | Notes |
|---|---|---|
| API Server | `A` (default `DP`) | Handles HTTP requests and input processing |
| Engine Core | `DP` (default 1) | Scheduler and KV cache management |
| GPU Worker | `N` (= `DP x TP`) | One per GPU, executes model forward passes |
| DP Coordinator | 1 if `DP > 1`, else 0 | Load balancing across DP ranks |
| **Total** | **`A + DP + N` (+ 1 if DP > 1)** | |
File: vllm/v1/engine/core.py (L753-759)
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
# Only publish request queue stats to coordinator for "internal"
# and "hybrid" LB modes.
self.publish_dp_lb_stats = internal_dp_balancing
File: docs/serving/data_parallel_deployment.md (L75-78)
Currently, the internal DP load balancing is done within the API server process(es) and is based on the running and waiting queues in each of the engines. This could be made more sophisticated in future by incorporating KV cache aware logic.
When deploying large DP sizes using this method, the API server process can become a bottleneck. In this case, the orthogonal `--api-server-count` command line option can be used to scale this out (for example `--api-server-count=4`). This is transparent to users - a single HTTP endpoint / port is still exposed. Note that this API server scale-out is "internal" and still confined to the "head" node.
## 内部负载均衡实现详解
### 关键数据结构
#### 1. EngineState
```python
class EngineState:
def __init__(self):
self.request_counts = [0, 0] # [waiting, running]
```[1](#2-0)
#### 2. EngineZmqAddresses
管理ZMQ通信地址,包含输入、输出和协调器地址:
```python
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
```[2](#2-1)
#### 3. 负载均衡统计
每个引擎维护waiting和running队列长度,用于负载均衡决策:
```python
waiting, running = current_counts[idx]
score = waiting * 4 + running
```[3](#2-2)
### 涉及的进程架构
| 进程类型 | 数量 | 作用 |
|---------|------|------|
| API Server | `A` (默认等于DP大小) | 处理HTTP请求,负载均衡决策 |
| Engine Core | `DP` | 调度和KV缓存管理 |
| GPU Worker | `N` (= `DP × TP`) | 执行模型前向传播 |
| DP Coordinator | 1 (如果DP > 1) | 收集统计信息,协调请求波次 | [4](#2-3)
### 完整流程
#### 1. 初始化阶段
```mermaid
sequenceDiagram
participant Main
participant DPCoordinator
participant EngineCore
participant APIServer
Main->>DPCoordinator: 启动协调器进程
Main->>EngineCore: 启动DP个引擎核心
Main->>APIServer: 启动A个API服务器
DPCoordinator->>APIServer: 发布统计信息地址
APIServer->>EngineCore: 建立ZMQ连接
2. 统计信息收集
每个引擎核心定期发布队列状态:
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
self.publish_dp_lb_stats = internal_dp_balancing
```[5](#2-4)
#### 3. 负载均衡决策
API服务器使用`DPLBAsyncMPClient`进行负载均衡:
```python
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
for i in range(num_engines):
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running
if score < min_score:
min_score = score
eng_index = idx
```[6](#2-5)
#### 4. 请求处理流程
```mermaid
sequenceDiagram
participant Client
participant APIServer
participant DPCoordinator
participant EngineCore
participant GPUWorker
Client->>APIServer: HTTP请求
APIServer->>APIServer: 选择最优引擎
APIServer->>EngineCore: 发送请求
EngineCore->>DPCoordinator: 更新队列状态
EngineCore->>GPUWorker: 执行模型
GPUWorker-->>EngineCore: 返回结果
EngineCore-->>APIServer: 返回输出
APIServer-->>Client: HTTP响应
关键实现细节
1. 协调器启动
coordinator = DPCoordinator(
parallel_config,
enable_wave_coordination=vllm_config.model_config.is_moe,
)
```[7](#2-6)
#### 2. 请求波次协调
对于MoE模型,协调器还负责请求波次同步:
```python
* Keeps track of the current DP "request wave" number and running state
of the engines. This is received from the DP rank 0 engine and published
to the front-end processes along with the current load stats.
```[8](#2-7)
#### 3. 统计信息发布
协调器收集并发布引擎统计信息:
```python
* Collects stats from each DP engine (currently just waiting and running
queue lengths), and publishes these to all front-ends for use in
load-balancing decisions.
```[9](#2-8)
## Notes
内部负载均衡的核心是通过DP Coordinator收集各引擎的队列状态,API服务器基于这些统计信息做出智能的请求分发决策。这种设计实现了对用户透明的单一API端点,同时充分利用了多个数据并行引擎的处理能力。 [10](#2-9)
Wiki pages you might want to explore:
- [Overview (vllm-project/vllm)](/wiki/vllm-project/vllm#1)
### Citations
**File:** vllm/v1/engine/coordinator.py (L28-30)
```python
* Collects stats from each DP engine (currently just waiting and running
queue lengths), and publishes these to all front-ends for use in
load-balancing decisions.
File: vllm/v1/engine/coordinator.py (L32-34)
* Keeps track of the current DP "request wave" number and running state
of the engines. This is received from the DP rank 0 engine and published
to the front-end processes along with the current load stats.
File: vllm/v1/engine/coordinator.py (L108-110)
class EngineState:
def __init__(self):
self.request_counts = [0, 0] # [waiting, running]
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/utils.py (L830-834)
if run_coordinator:
coordinator = DPCoordinator(
parallel_config,
enable_wave_coordination=vllm_config.model_config.is_moe,
)
File: vllm/v1/engine/core_client.py (L1242-1262)
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
# Engines are in rank order.
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines
# TODO use P2C alg for larger DP sizes
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
for i in range(num_engines):
# Start from client_index to help with balancing when engines
# are empty.
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running
if score < min_score:
min_score = score
eng_index = idx
# Increment local waiting count for better balancing between stats
# updates from the coordinator (which happen every 100ms).
current_counts[eng_index][0] += self.client_count
File: docs/design/arch_overview.md (L117-127)
### Process Count Summary
For a deployment with `N` GPUs, `TP` tensor parallel size, `DP` data parallel size, and `A` API server count:
| Process Type | Count | Notes |
|---|---|---|
| API Server | `A` (default `DP`) | Handles HTTP requests and input processing |
| Engine Core | `DP` (default 1) | Scheduler and KV cache management |
| GPU Worker | `N` (= `DP x TP`) | One per GPU, executes model forward passes |
| DP Coordinator | 1 if `DP > 1`, else 0 | Load balancing across DP ranks |
| **Total** | **`A + DP + N` (+ 1 if DP > 1)** | |
File: vllm/v1/engine/core.py (L753-759)
internal_dp_balancing = (
self.has_coordinator
and not vllm_config.parallel_config.data_parallel_external_lb
)
# Only publish request queue stats to coordinator for "internal"
# and "hybrid" LB modes.
self.publish_dp_lb_stats = internal_dp_balancing
File: docs/serving/data_parallel_deployment.md (L75-78)
Currently, the internal DP load balancing is done within the API server process(es) and is based on the running and waiting queues in each of the engines. This could be made more sophisticated in future by incorporating KV cache aware logic.
When deploying large DP sizes using this method, the API server process can become a bottleneck. In this case, the orthogonal `--api-server-count` command line option can be used to scale this out (for example `--api-server-count=4`). This is transparent to users - a single HTTP endpoint / port is still exposed. Note that this API server scale-out is "internal" and still confined to the "head" node.
前端进程(API Server)概述
**前端进程(API Server)**是 vLLM 中处理 HTTP 请求的进程,负责接收客户端请求、进行输入处理(如 tokenization)、执行负载均衡决策,并将请求转发给后端的引擎核心进程。 1
完整的请求流程代码追踪
1. API Server 启动
API Server 通过 run_multi_api_server 函数启动: 2
def run_multi_api_server(args: argparse.Namespace):
# 设置共享的监听地址和socket
listen_address, sock = setup_server(args)
# 启动API服务器进程管理器
api_server_manager = APIServerProcessManager(
target_server_fn=run_api_server_worker_proc,
listen_address=listen_address,
sock=sock, # 共享同一个socket
num_servers=num_api_servers,
# ...
)
2. 请求接收与处理
HTTP 请求到达后,API Server 使用 AsyncLLM 处理请求: 3
3. 负载均衡决策
API Server 使用 DPLBAsyncMPClient 进行负载均衡,选择最优的引擎: 4
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
# 如果请求没有指定DP rank,则进行负载均衡
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines # 获取各引擎的负载统计
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
# 遍历所有引擎,计算负载分数
for i in range(num_engines):
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running # 等待队列权重更高
if score < min_score:
min_score = score
eng_index = idx
# 增加本地等待计数,提高均衡性
current_counts[eng_index][0] += self.client_count
chosen_engine = self.core_engines[eng_index]
return chosen_engine
4. 请求转发
选择引擎后,通过 add_request_async 将请求发送到选定引擎: 5
async def add_request_async(self, request: EngineCoreRequest) -> None:
self._ensure_stats_update_task()
request.current_wave = self.current_wave
request.client_index = self.client_index
# 选择最优引擎
chosen_engine = self.get_core_engine_for_request(request)
# 发送请求到选定引擎
to_await = self._send_input(EngineCoreRequestType.ADD, request, chosen_engine)
if not self.engines_running:
# 通知协调器有新请求
req_msg = msgspec.msgpack.encode(("FIRST_REQ", chosen_engine))
await self.first_req_send_socket.send(req_msg)
await to_await
5. 统计信息更新
API Server 定期从 DP Coordinator 接收各引擎的统计信息: 6
async def run_engine_stats_update_task():
# 订阅协调器的统计信息发布
await socket.send(b"\x01") # 发送订阅消息
while True:
# 接收统计信息更新
buf = socket.recv(flags=zmq.NOBLOCK).result()
counts, wave, running = msgspec.msgpack.decode(buf)
self.current_wave = wave
self.engines_running = running
if counts is not None:
# 更新本地负载均衡状态
sliced_counts = counts[count_slice]
self.lb_engines = sliced_counts
完整流程图
关键数据结构关系
- EngineState: 存储每个引擎的
[waiting, running]计数 7 - lb_engines: API Server 本地维护的各引擎负载统计
- EngineZmqAddresses: 管理 ZMQ 通信地址 8
Notes
API Server 作为前端进程,通过 DPLBAsyncMPClient 实现智能的内部负载均衡。它定期从 DP Coordinator 获取各引擎的实时负载信息,基于等待队列和运行队列长度计算负载分数,选择最优引擎处理请求。整个过程对用户透明,实现了单一 API 端点下的高效负载分发。 9
Wiki pages you might want to explore:
Citations
File: docs/design/arch_overview.md (L85-91)
### API Server Process
The API server process handles HTTP requests (e.g., the OpenAI-compatible API), performs input processing (tokenization, multi-modal data loading), and streams results back to clients. It communicates with the engine core process(es) via ZMQ sockets.
By default, there is **1 API server process**, but when data parallelism is used, the API server count automatically scales to match the data parallel size. This can also be manually configured with the `--api-server-count` flag. Each API server connects to **all** engine cores via ZMQ in a many-to-many topology, enabling any API server to route requests to any engine core. Each API server process uses multiple CPU threads for media loading (controlled by `VLLM_MEDIA_LOADING_THREAD_COUNT`, default 8).
The code can be found in [vllm/entrypoints/openai/api_server.py](../../vllm/entrypoints/openai/api_server.py) and [vllm/v1/utils.py](../../vllm/v1/utils.py).
File: vllm/entrypoints/cli/serve.py (L218-288)
def run_multi_api_server(args: argparse.Namespace):
assert not args.headless
num_api_servers: int = args.api_server_count
assert num_api_servers > 0
if num_api_servers > 1:
setup_multiprocess_prometheus()
listen_address, sock = setup_server(args)
engine_args = vllm.AsyncEngineArgs.from_cli_args(args)
engine_args._api_process_count = num_api_servers
engine_args._api_process_rank = -1
usage_context = UsageContext.OPENAI_API_SERVER
vllm_config = engine_args.create_engine_config(usage_context=usage_context)
if num_api_servers > 1 and envs.VLLM_ALLOW_RUNTIME_LORA_UPDATING:
raise ValueError(
"VLLM_ALLOW_RUNTIME_LORA_UPDATING cannot be used with api_server_count > 1"
)
executor_class = Executor.get_class(vllm_config)
log_stats = not engine_args.disable_log_stats
parallel_config = vllm_config.parallel_config
dp_rank = parallel_config.data_parallel_rank
assert parallel_config.local_engines_only or dp_rank == 0
api_server_manager: APIServerProcessManager | None = None
with launch_core_engines(
vllm_config, executor_class, log_stats, num_api_servers
) as (local_engine_manager, coordinator, addresses):
# Construct common args for the APIServerProcessManager up-front.
api_server_manager_kwargs = dict(
target_server_fn=run_api_server_worker_proc,
listen_address=listen_address,
sock=sock,
args=args,
num_servers=num_api_servers,
input_addresses=addresses.inputs,
output_addresses=addresses.outputs,
stats_update_address=coordinator.get_stats_publish_address()
if coordinator
else None,
)
# For dp ranks > 0 in external/hybrid DP LB modes, we must delay the
# start of the API servers until the local engine is started
# (after the launcher context manager exits),
# since we get the front-end stats update address from the coordinator
# via the handshake with the local engine.
if dp_rank == 0 or not parallel_config.local_engines_only:
# Start API servers using the manager.
api_server_manager = APIServerProcessManager(**api_server_manager_kwargs)
# Start API servers now if they weren't already started.
if api_server_manager is None:
api_server_manager_kwargs["stats_update_address"] = (
addresses.frontend_stats_publish_address
)
api_server_manager = APIServerProcessManager(**api_server_manager_kwargs)
# Wait for API servers
wait_for_completion_or_failure(
api_server_manager=api_server_manager,
engine_manager=local_engine_manager,
coordinator=coordinator,
)
File: vllm/v1/engine/async_llm.py (L1-54)
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
import asyncio
import os
import socket
import time
import warnings
from collections.abc import AsyncGenerator, Iterable, Mapping
from copy import copy
from typing import Any
import torch
import vllm.envs as envs
from vllm import TokensPrompt
from vllm.config import VllmConfig
from vllm.distributed.weight_transfer.base import (
WeightTransferInitRequest,
WeightTransferUpdateRequest,
)
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.engine.protocol import EngineClient, StreamingInput
from vllm.inputs import ProcessorInputs, PromptType
from vllm.logger import init_logger
from vllm.lora.request import LoRARequest
from vllm.multimodal import MULTIMODAL_REGISTRY, MultiModalRegistry
from vllm.outputs import STREAM_FINISHED, PoolingRequestOutput, RequestOutput
from vllm.plugins.io_processors import get_io_processor
from vllm.pooling_params import PoolingParams
from vllm.renderers import renderer_from_config
from vllm.renderers.inputs.preprocess import extract_prompt_components
from vllm.sampling_params import RequestOutputKind, SamplingParams
from vllm.tasks import SupportedTask
from vllm.tokenizers import TokenizerLike
from vllm.tracing import init_tracer
from vllm.transformers_utils.config import maybe_register_config_serialize_by_value
from vllm.usage.usage_lib import UsageContext
from vllm.utils.async_utils import cancel_task_threadsafe
from vllm.utils.collection_utils import as_list
from vllm.v1.engine import EngineCoreRequest, PauseMode
from vllm.v1.engine.core_client import EngineCoreClient
from vllm.v1.engine.exceptions import EngineDeadError, EngineGenerateError
from vllm.v1.engine.input_processor import InputProcessor
from vllm.v1.engine.output_processor import OutputProcessor, RequestOutputCollector
from vllm.v1.engine.parallel_sampling import ParentRequest
from vllm.v1.executor import Executor
from vllm.v1.metrics.loggers import (
StatLoggerFactory,
StatLoggerManager,
load_stat_logger_plugin_factories,
)
from vllm.v1.metrics.prometheus import shutdown_prometheus
from vllm.v1.metrics.stats import IterationStats
File: vllm/v1/engine/core_client.py (L1093-1186)
def _ensure_stats_update_task(self):
resources = self.resources
if resources.stats_update_task is not None:
return
assert self.stats_update_address is not None
stats_addr: str = self.stats_update_address
assert len(self.engine_ranks_managed) > 0
# NOTE: running and waiting counts are all global from
# the Coordinator include all global EngineCores. This
# slice includes just the cores managed by this client.
count_slice = slice(
self.engine_ranks_managed[0], self.engine_ranks_managed[-1] + 1
)
async def run_engine_stats_update_task():
with (
make_zmq_socket(self.ctx, stats_addr, zmq.XSUB, linger=0) as socket,
make_zmq_socket(
self.ctx, self.first_req_sock_addr, zmq.PAIR, bind=False, linger=0
) as first_req_rcv_socket,
):
assert isinstance(socket, zmq.asyncio.Socket)
assert isinstance(first_req_rcv_socket, zmq.asyncio.Socket)
self.resources.stats_update_socket = socket
self.resources.first_req_rcv_socket = first_req_rcv_socket
# Send subscription message.
await socket.send(b"\x01")
poller = zmq.asyncio.Poller()
poller.register(socket, zmq.POLLIN)
poller.register(first_req_rcv_socket, zmq.POLLIN)
while True:
events = await poller.poll()
if (
not self.engines_running
and len(events) == 2
or (events[0][0] == first_req_rcv_socket)
):
# Check if this is a regular request notification or
# scale up notification
buf = first_req_rcv_socket.recv(flags=zmq.NOBLOCK).result()
decoded = msgspec.msgpack.decode(buf)
if (
isinstance(decoded, (list, tuple))
and len(decoded) == 2
and decoded[0] == "SCALE_ELASTIC_EP"
):
# Extract new engine count from the decoded message
new_engine_count = decoded[1]
# Send scale up notification to coordinator
scale_msg = msgspec.msgpack.encode(
("SCALE_ELASTIC_EP", new_engine_count)
)
await socket.send(scale_msg)
continue
# we're sending a request while the engines are
# paused, so that it can wake the others up
# (to run dummy EP loop).
assert decoded[0] == "FIRST_REQ"
target_eng_index = decoded[1]
self.engines_running = True
msg = msgspec.msgpack.encode(
(target_eng_index, self.current_wave)
)
await socket.send(msg)
buf = None
while True:
# Drain all stats events (we only care about latest).
future: asyncio.Future[bytes] = socket.recv(flags=zmq.NOBLOCK)
if isinstance(future.exception(), zmq.Again):
break
buf = future.result()
if buf is None:
continue
# Update local load-balancing state.
counts, wave, running = msgspec.msgpack.decode(buf)
self.current_wave = wave
self.engines_running = running
if counts is not None:
sliced_counts = counts[count_slice]
self.lb_engines = sliced_counts
logger.debug(
"Received counts: %s (%s)", sliced_counts, count_slice
)
resources.stats_update_task = asyncio.create_task(
run_engine_stats_update_task()
)
File: vllm/v1/engine/core_client.py (L1188-1204)
async def add_request_async(self, request: EngineCoreRequest) -> None:
self._ensure_stats_update_task()
request.current_wave = self.current_wave
request.client_index = self.client_index
chosen_engine = self.get_core_engine_for_request(request)
to_await = self._send_input(EngineCoreRequestType.ADD, request, chosen_engine)
if not self.engines_running:
# Notify coordinator that we're sending a request
req_msg = msgspec.msgpack.encode(("FIRST_REQ", chosen_engine))
await self.first_req_send_socket.send(req_msg)
await to_await
self._ensure_output_queue_task()
File: vllm/v1/engine/core_client.py (L1242-1266)
def get_core_engine_for_request(self, request: EngineCoreRequest) -> EngineIdentity:
# Engines are in rank order.
if (eng_index := request.data_parallel_rank) is None:
current_counts = self.lb_engines
# TODO use P2C alg for larger DP sizes
num_engines = len(current_counts)
min_score = sys.maxsize
eng_index = 0
for i in range(num_engines):
# Start from client_index to help with balancing when engines
# are empty.
idx = (self.eng_start_index + i) % num_engines
waiting, running = current_counts[idx]
score = waiting * 4 + running
if score < min_score:
min_score = score
eng_index = idx
# Increment local waiting count for better balancing between stats
# updates from the coordinator (which happen every 100ms).
current_counts[eng_index][0] += self.client_count
chosen_engine = self.core_engines[eng_index]
# Record which engine is chosen for this request, to handle aborts.
self.reqs_in_flight[request.request_id] = chosen_engine
return chosen_engine
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: docs/serving/data_parallel_deployment.md (L75-78)
Currently, the internal DP load balancing is done within the API server process(es) and is based on the running and waiting queues in each of the engines. This could be made more sophisticated in future by incorporating KV cache aware logic.
When deploying large DP sizes using this method, the API server process can become a bottleneck. In this case, the orthogonal `--api-server-count` command line option can be used to scale this out (for example `--api-server-count=4`). This is transparent to users - a single HTTP endpoint / port is still exposed. Note that this API server scale-out is "internal" and still confined to the "head" node.
多个 API Server 的通信机制
共享监听端口接收请求
多个 API Server 进程通过共享同一个监听 socket 来接收 HTTP 请求。操作系统内核负责在多个进程间分发连接,实现负载均衡。 1
# 设置共享的监听地址和socket
listen_address, sock = setup_server(args)
API Server 进程管理
APIServerProcessManager 负责启动和管理多个 API Server 工作进程: 2
class APIServerProcessManager:
def __init__(self, target_server_fn, listen_address, sock, args, num_servers,
input_addresses, output_addresses, stats_update_address=None):
# 启动多个API服务器工作进程
for i, in_addr, out_addr in zip(range(num_servers), input_addresses, output_addresses):
client_config = {
"input_address": in_addr,
"output_address": out_addr,
"client_count": num_servers,
"client_index": i,
}
proc = spawn_context.Process(
target=target_server_fn,
name=f"ApiServer_{i}",
args=(listen_address, sock, args, client_config),
)
proc.start()
与 Engine Core 的 ZMQ 通信
每个 API Server 通过 ZMQ socket 与所有 Engine Core 进程建立多对多连接: 3
# 为每个API服务器设置输入输出地址
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
与 DP Coordinator 的统计信息订阅
API Server 订阅 DP Coordinator 发布的负载统计信息: 4
async def run_engine_stats_update_task():
# 订阅协调器的统计信息发布
await socket.send(b"\x01") # 发送订阅消息
while True:
# 接收统计信息更新
counts, wave, running = msgspec.msgpack.decode(buf)
if counts is not None:
# 更新本地负载均衡状态
sliced_counts = counts[count_slice]
self.lb_engines = sliced_counts
完整通信流程
关键通信机制
1. Socket 共享机制
- 多个 API Server 进程共享同一个监听 socket
- 操作系统内核自动进行连接分发
- 对客户端透明,只需连接单一端口
2. ZMQ 多对多拓扑
- 每个 API Server 连接到所有 Engine Core
- 使用 DEALER/PUSH 模式进行请求发送
- 使用 ROUTER/PULL 模式接收响应
3. 发布-订阅模式
- DP Coordinator 作为发布者
- API Server 作为订阅者
- 实时分发引擎负载统计信息
Notes
多个 API Server 通过共享监听端口和 ZMQ 通信机制实现了高效的并行处理。这种设计既保持了单一 API 端点的简洁性,又能够充分利用多核 CPU 资源进行输入处理和负载均衡决策。 5
Wiki pages you might want to explore:
Citations
File: vllm/entrypoints/cli/serve.py (L226-227)
listen_address, sock = setup_server(args)
File: vllm/v1/utils.py (L159-218)
class APIServerProcessManager:
"""Manages a group of API server processes.
Handles creation, monitoring, and termination of API server worker
processes. Also monitors extra processes to check if they are healthy.
"""
def __init__(
self,
target_server_fn: Callable,
listen_address: str,
sock: Any,
args: argparse.Namespace,
num_servers: int,
input_addresses: list[str],
output_addresses: list[str],
stats_update_address: str | None = None,
):
"""Initialize and start API server worker processes.
Args:
target_server_fn: Function to call for each API server process
listen_address: Address to listen for client connections
sock: Socket for client connections
args: Command line arguments
num_servers: Number of API server processes to start
input_addresses: Input addresses for each API server
output_addresses: Output addresses for each API server
stats_update_address: Optional stats update address
"""
self.listen_address = listen_address
self.sock = sock
self.args = args
# Start API servers
spawn_context = multiprocessing.get_context("spawn")
self.processes: list[BaseProcess] = []
for i, in_addr, out_addr in zip(
range(num_servers), input_addresses, output_addresses
):
client_config = {
"input_address": in_addr,
"output_address": out_addr,
"client_count": num_servers,
"client_index": i,
}
if stats_update_address is not None:
client_config["stats_update_address"] = stats_update_address
proc = spawn_context.Process(
target=target_server_fn,
name=f"ApiServer_{i}",
args=(listen_address, sock, args, client_config),
)
self.processes.append(proc)
proc.start()
logger.info("Started %d API server processes", len(self.processes))
File: vllm/v1/engine/utils.py (L810-820)
# Set up input and output addresses.
addresses = EngineZmqAddresses(
inputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
outputs=[
get_engine_client_zmq_addr(client_local_only, host)
for _ in range(num_api_servers)
],
)
File: vllm/v1/engine/core_client.py (L1093-1186)
def _ensure_stats_update_task(self):
resources = self.resources
if resources.stats_update_task is not None:
return
assert self.stats_update_address is not None
stats_addr: str = self.stats_update_address
assert len(self.engine_ranks_managed) > 0
# NOTE: running and waiting counts are all global from
# the Coordinator include all global EngineCores. This
# slice includes just the cores managed by this client.
count_slice = slice(
self.engine_ranks_managed[0], self.engine_ranks_managed[-1] + 1
)
async def run_engine_stats_update_task():
with (
make_zmq_socket(self.ctx, stats_addr, zmq.XSUB, linger=0) as socket,
make_zmq_socket(
self.ctx, self.first_req_sock_addr, zmq.PAIR, bind=False, linger=0
) as first_req_rcv_socket,
):
assert isinstance(socket, zmq.asyncio.Socket)
assert isinstance(first_req_rcv_socket, zmq.asyncio.Socket)
self.resources.stats_update_socket = socket
self.resources.first_req_rcv_socket = first_req_rcv_socket
# Send subscription message.
await socket.send(b"\x01")
poller = zmq.asyncio.Poller()
poller.register(socket, zmq.POLLIN)
poller.register(first_req_rcv_socket, zmq.POLLIN)
while True:
events = await poller.poll()
if (
not self.engines_running
and len(events) == 2
or (events[0][0] == first_req_rcv_socket)
):
# Check if this is a regular request notification or
# scale up notification
buf = first_req_rcv_socket.recv(flags=zmq.NOBLOCK).result()
decoded = msgspec.msgpack.decode(buf)
if (
isinstance(decoded, (list, tuple))
and len(decoded) == 2
and decoded[0] == "SCALE_ELASTIC_EP"
):
# Extract new engine count from the decoded message
new_engine_count = decoded[1]
# Send scale up notification to coordinator
scale_msg = msgspec.msgpack.encode(
("SCALE_ELASTIC_EP", new_engine_count)
)
await socket.send(scale_msg)
continue
# we're sending a request while the engines are
# paused, so that it can wake the others up
# (to run dummy EP loop).
assert decoded[0] == "FIRST_REQ"
target_eng_index = decoded[1]
self.engines_running = True
msg = msgspec.msgpack.encode(
(target_eng_index, self.current_wave)
)
await socket.send(msg)
buf = None
while True:
# Drain all stats events (we only care about latest).
future: asyncio.Future[bytes] = socket.recv(flags=zmq.NOBLOCK)
if isinstance(future.exception(), zmq.Again):
break
buf = future.result()
if buf is None:
continue
# Update local load-balancing state.
counts, wave, running = msgspec.msgpack.decode(buf)
self.current_wave = wave
self.engines_running = running
if counts is not None:
sliced_counts = counts[count_slice]
self.lb_engines = sliced_counts
logger.debug(
"Received counts: %s (%s)", sliced_counts, count_slice
)
resources.stats_update_task = asyncio.create_task(
run_engine_stats_update_task()
)
File: docs/design/arch_overview.md (L85-91)
### API Server Process
The API server process handles HTTP requests (e.g., the OpenAI-compatible API), performs input processing (tokenization, multi-modal data loading), and streams results back to clients. It communicates with the engine core process(es) via ZMQ sockets.
By default, there is **1 API server process**, but when data parallelism is used, the API server count automatically scales to match the data parallel size. This can also be manually configured with the `--api-server-count` flag. Each API server connects to **all** engine cores via ZMQ in a many-to-many topology, enabling any API server to route requests to any engine core. Each API server process uses multiple CPU threads for media loading (controlled by `VLLM_MEDIA_LOADING_THREAD_COUNT`, default 8).
The code can be found in [vllm/entrypoints/openai/api_server.py](../../vllm/entrypoints/openai/api_server.py) and [vllm/v1/utils.py](../../vllm/v1/utils.py).

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)