从 CUDA OOM 到彻底榨干 GPU:DeepSeek 等大模型高效推理与部署全攻略
本文深入剖析大模型部署中的显存瓶颈问题,以DeepSeek-V3为例,系统分析显存占用的四大来源(模型权重、KV缓存、激活值、运行时上下文),并通过量化、动态优化、分布式扩展等策略提供解决方案。文章包含工业级诊断工具和实战代码,帮助开发者在资源受限环境下高效部署大模型,涵盖INT8/INT4量化、FlashAttention优化及vLLM集群部署等关键技术。
文章目录
作者按:作为一名在 AI 工程化摸爬滚打多年的老兵,过去的一年里,我见过无数优秀的算法模型在实验室里跑得飞起,却在走向生产环境时被“CUDA Out Of Memory”按在地上摩擦。尤其是随着 DeepSeek-V3/R1 等新一代数百亿、上千亿参数 MoE 巨兽的开源,显存焦虑几乎成了每一个 MLOps 工程师和系统架构师的日常。
这篇文章,我将脱下晦涩难懂的学术外衣,用最接地气的语言、最直观的图表和最硬核的代码,带你系统级地打通大模型部署的“任督二脉”。无论你是手里只有一张 RTX 4090 的极客,还是掌控千卡 H100 集群的架构师,这篇指南都将是你不可多得的避坑宝典。
📖 核心速览
本文专为解决大模型显存瓶颈而生,我们将沿着以下主线层层深入:
- 灵魂拷问:透视 DeepSeek 架构,算一算它到底凭什么这么“吃”显存?
- 病理切片:解剖 CUDA OOM 的报错信息,揪出显存碎片的幕后黑手。
- 降维打击(模型量化):INT8/INT4/FP8 轮番上阵,给模型做“抽脂手术”。
- 凌波微步(动态优化):FlashAttention、PagedAttention、混合精度,榨干硬件的最后一滴血。
- 分身术(分布式扩展):TP、PP、EP 大显神通,解锁 vLLM 与 SGLang 的集群之力。
- 实战演练:提供可直接 Copy-Paste 的工业级部署代码。
🛑 引言:大模型落地的“阿喀琉斯之踵”
2025 年无疑是开源大模型彻底爆发的一年,DeepSeek 凭借极高的性价比和惊艳的推理能力席卷全球。但当我们兴冲冲地把模型下载到本地,敲下 model.generate() 的那一刻,屏幕上那一抹刺眼的红色报错,瞬间把人拉回现实:
RuntimeError: CUDA out of memory. Tried to allocate 2.00 GiB...
🏎️ 打个比方:
部署大模型就像是保养一辆拥有 F1 级别引擎的顶级跑车(DeepSeek)。它的马力极大(推理能力强),但对赛道宽度(显存容量)和燃油输送效率(显存带宽)的要求极为苛刻。如果我们只是一味地踩油门,而不去优化传动系统(量化)和赛道管理(KV Cache 调度),这辆车连车库都开不出去。
要彻底驯服这头显存“猛兽”,我们必须从它的基因——模型架构开始剖析。
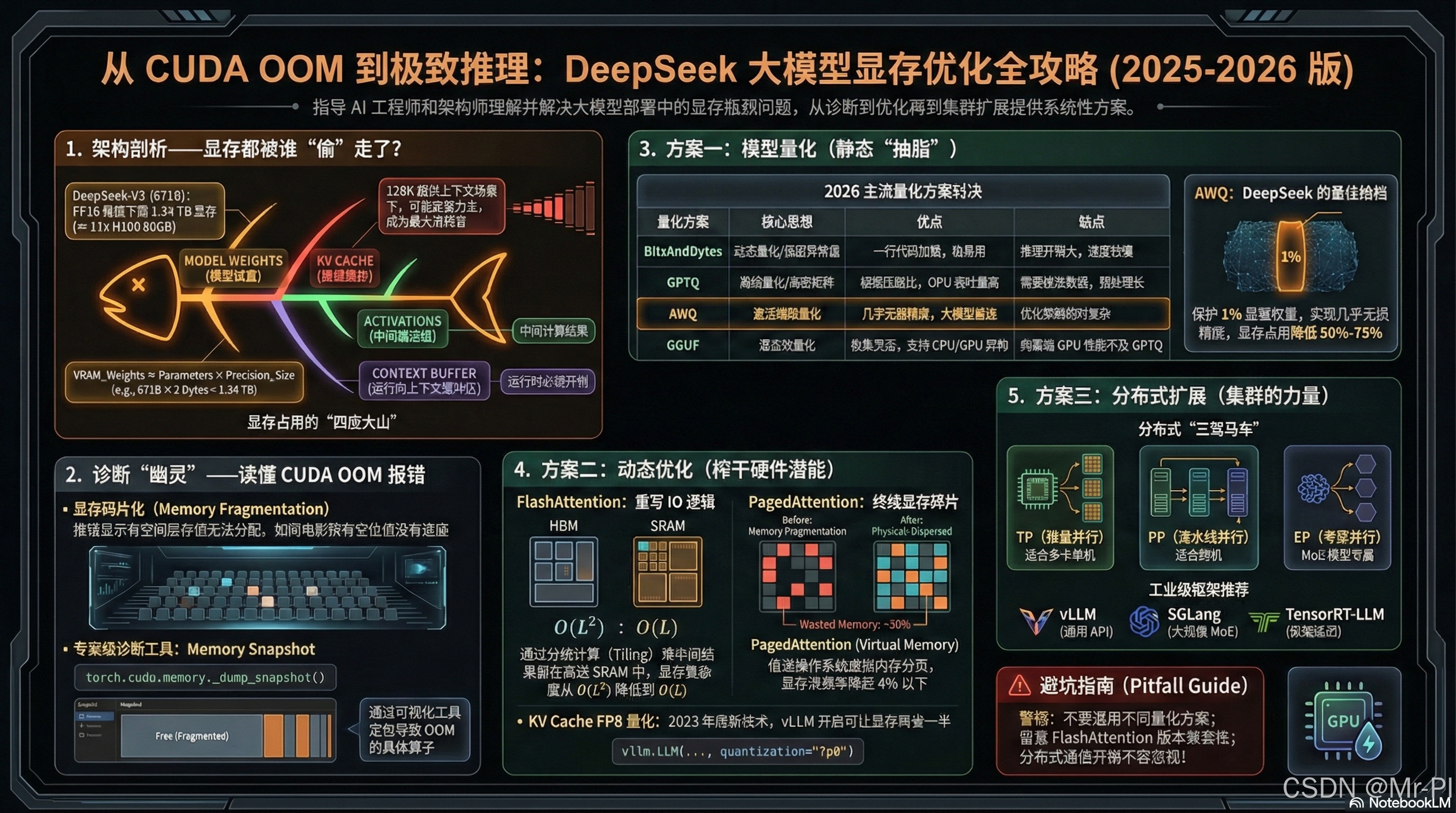
🧬 第一章:架构剖析——DeepSeek 为何如此“吃”显存?
很多新手会有个误区:“我的模型是 7B 的,为什么 8GB 的显卡跑不起来?” 要回答这个问题,我们要搞清楚大模型推理时的显存四座大山。
1.1 显存占用的四大来源
使用 Mermaid 绘制的显存分布鱼骨图,直观展现显存都被谁“偷”走了:
1.2 致命的数学题:DeepSeek-V3 的显存账本
以总参数量 671B 的 DeepSeek-V3 为例。它采用了 MoE (Mixture of Experts) 架构。MoE 的特点是“平时养兵千日,战时只用一部分”。虽然每次推理前向传播只激活约 37B 的参数,但你必须把所有的专家(671B)都装进显存里准备随时被 Router 调度!
我们来算一笔账:
-
在 FP16 (半精度) 格式下:每个参数占 2 字节。
V R A M w e i g h t s = 671 × 10 9 × 2 Bytes ≈ 1342 GB = 1.34 TB VRAM_{weights} = 671 \times 10^9 \times 2 \text{ Bytes} \approx 1342 \text{ GB} = 1.34 \text{ TB} VRAMweights=671×109×2 Bytes≈1342 GB=1.34 TB
这意味着,仅仅是把模型加载进来,什么都不干,就需要 17 张 80GB 的 A100/H100(算上损耗通常需要 2 个 8 卡节点)。 -
KV Cache 的爆炸:
KV Cache 的计算公式为:
KV_Cache = 2 × B × L × H × N l a y e r s × P b y t e s \text{KV\_Cache} = 2 \times B \times L \times H \times N_{layers} \times P_{bytes} KV_Cache=2×B×L×H×Nlayers×Pbytes
其中 B B B 是 Batch Size, L L L 是序列长度, H H H 是隐藏层维度, N N N 是层数。当处理 128K 超长上下文时,KV Cache 的大小可能高达数百 GB,直接反客为主,成为显存最大的消耗者!
🔍 第二章:OOM 的“幽灵”——病理诊断与排查
当我们遭遇 CUDA out of memory 时,千万不要马上重启机器或者无脑加钱买卡。我们要像个神探一样,解读日志里的蛛丝马迹。
2.1 读懂 PyTorch 的“死亡宣告”
RuntimeError: CUDA out of memory. Tried to allocate 2.00 GiB
(GPU 0; 23.65 GiB total capacity; 21.47 GiB already allocated;
1.14 GiB free; 22.00 GiB reserved in total by PyTorch)
这段报错其实包含了非常丰富的信息:
Tried to allocate 2.00 GiB:压死骆驼的最后一根稻草(通常是某个巨大的注意力矩阵或者 KV Cache 分配)。21.47 GiB already allocated:当前模型权重和真实使用的数据占用的显存。22.00 GiB reserved:PyTorch 的显存池(Allocator)向显卡申请的总显存。
💡 核心痛点:显存碎片化 (Memory Fragmentation)
这里有个细节:reserved (22GB) - allocated (21.47GB) = 0.53GB,加上 free (1.14GB) 共有 1.67GB 空闲,但系统偏偏要申请 2GB,所以崩了。这就是显存碎片化——虽然总空闲容量够,但找不到一块连续的 2GB 内存。就像一个坐满人的电影院,虽然还有 10 个空位,但一家三口想坐在一起却找不到连座了。
2.2 专家级诊断工具箱
在代码中插入以下代码,可以生成详细的显存快照,供系统架构师分析:
import torch
# 开启 PyTorch 内存历史记录
torch.cuda.memory._record_memory_history(max_entries=100000)
try:
# 这里放你的大模型推理代码
outputs = model.generate(**inputs)
except RuntimeError as e:
if "out of memory" in str(e):
print("🚨 检测到 OOM,正在导出内存快照...")
torch.cuda.memory._dump_snapshot("oom_snapshot.pickle")
# 随后可将其拖入 https://pytorch.org/memory_viz 查看可视化
raise e
🔪 第三章:破局策略一——模型量化 (给模型“瘦身”的艺术)
如果显存不够,最直接的办法就是把模型变小。这就是**量化(Quantization)**的舞台。量化本质上是一种有损压缩,用低位宽的数据类型(INT8, INT4 甚至更低)去近似表达 FP16 的浮点数。
3.1 量化的核心数学原理
最基础的线性量化公式如下:
x q = Round ( x S ) + Z x_q = \text{Round}\left( \frac{x}{S} \right) + Z xq=Round(Sx)+Z
x d e q u a n t = ( x q − Z ) × S x_{dequant} = (x_q - Z) \times S xdequant=(xq−Z)×S
其中 x x x 是原数值, S S S 是缩放因子(Scale), Z Z Z 是零点(Zero-point)。
3.2 2026 年主流量化流派华山论剑
| 流派方案 | 核心思想 | 适用场景 | 优缺点点评 |
|---|---|---|---|
| BitsAndBytes (8-bit/4-bit) | 动态量化,保留异常值(Outliers)在 FP16 计算,其余变 INT8。 | 快速验证、零配置加载。 | ✅ 调包侠最爱,一行代码搞定。 ❌ 运行时反量化开销大,推理速度较慢。 |
| GPTQ (INT4/INT3) | 离线量化,利用海森矩阵(Hessian)计算权重重要性,补偿量化误差。 | 纯 GPU 环境下的高吞吐生产部署。 | ✅ 极致的压缩比和 GPU 吞吐量。 ❌ 需要较长时间的校准数据集预处理。 |
| AWQ (INT4) | 激活感知(Activation-aware)。发现仅有 1% 的显著权重对精度至关重要,保护这 1% 不被量化。 | 对精度要求极高的业务场景。 | ✅ 几乎无损的精度保留,MLSys 最佳论文。 ❌ 优化策略稍显复杂。 |
| GGUF (Q4_K_M) | 混合量化,按块(Block)将模型分块量化,支持 CPU/GPU 异构计算。 | 个人 PC、MacBook、边缘设备部署。 | ✅ 极其灵活,显存不够内存来凑。 ❌ 纯高端 GPU 环境下性能不如 GPTQ。 |
3.3 实战代码:优雅加载 AWQ 量化模型
在 Transformers 库中加载 AWQ 仅需简单的配置:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "deepseek-ai/DeepSeek-Coder-V2-Lite-Base-AWQ"
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 加载 AWQ INT4 模型
print("🚀 正在将 AWQ 量化模型加载入显存...")
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto", # 自动切分模型至多卡
torch_dtype=torch.float16, # 计算时自动反量化为 FP16
low_cpu_mem_usage=True # 极低内存加载模式
)
# 验证显存占用
memory_gb = model.get_memory_footprint() / (1024**3)
print(f"✅ 模型加载成功!当前显存占用约: {memory_gb:.2f} GB")
💡 专家提示:DeepSeek-V3 原生推荐使用 FP8 或 AWQ 格式,相比 FP16,不仅显存锐减 50%~75%,显存带宽压力也同步降低,变相提升了推理速度。
⚡ 第四章:破局策略二——动态优化 (榨干硬件潜能)
量化是在静态模型上做文章,而动态优化则是在代码运行的电光火石之间,去抠每一比特的显存和每一纳秒的计算。
4.1 FlashAttention:重写注意力机制的 IO 逻辑
在大模型中,自注意力机制的计算复杂度是 O ( L 2 ) O(L^2) O(L2)(L为序列长度)。更要命的是,它会产生巨大的中间张量(Softmax(Q*K))。
FlashAttention(目前已演进至 V3)通过**Tiling(分块计算)和Recomputation(重计算)**技术,将这些中间结果保留在 GPU 的极速 SRAM 中,而不是写回 HBM(显存)。
显存占用复杂度 : O ( L 2 ) ⟶ O ( L ) \text{显存占用复杂度}: O(L^2) \longrightarrow O(L) 显存占用复杂度:O(L2)⟶O(L)
如何在 PyTorch 中开启?(只需一个参数)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2" # 🚀 一键开启光速引擎
)
4.2 vLLM 与 PagedAttention:终结显存碎片的杀器
前文提到 KV Cache 带来了严重的显存碎片。vLLM 框架横空出世,提出了 PagedAttention 技术。
它的灵感来自操作系统的“虚拟内存分页”。它将连续的 KV 缓存切割成固定大小的“块(Blocks)”,分散存放在显存的各个角落,并通过一个张量映射表来管理。
使用 vLLM 后,显存浪费率直接从 30% 暴降至 不到 4%!
4.3 终极抠门技巧:KV Cache FP8 量化
到了 2025 年底,连 KV Cache 也被大家拿去量化了。在生成极长文本时,将历史生成的 KV 缓存从 FP16 降维到 FP8。
# 在 vLLM 中启用 KV Cache FP8 量化
from vllm import LLM
llm = LLM(
model="deepseek-ai/DeepSeek-V3",
kv_cache_dtype="fp8", # 🪄 魔法参数:显存立省一半
gpu_memory_utilization=0.9 # 把 90% 显存交给 vLLM 调度
)
🌐 第五章:破局策略三——分布式扩展 (集群的力量)
当单卡的显存被彻底榨干后,我们唯一的出路就是组建 GPU 矩阵。分布式推理绝不是简单地把模型拷贝几份,而是极具艺术感的“庖丁解牛”。
5.1 分布式并行的“三驾马车” + MoE 特供版
- 张量并行 (Tensor Parallelism, TP):
将一个巨大的矩阵乘法切开,交给不同的 GPU 计算,然后再做AllReduce通信汇总。适合:单节点内多卡(如 NVLink 互联的 8 卡机器)。 - 流水线并行 (Pipeline Parallelism, PP):
把模型的 80 层像工厂流水线一样切分。GPU 0 负责 1-20 层,算完把结果传给 GPU 1 算 21-40 层。适合:跨节点、网络带宽有限的集群。 - 专家并行 (Expert Parallelism, EP) —— DeepSeek 专属:
因为 MoE 有数百个专家,我们可以把专家分散到不同 GPU 上。Token 流入后,Router 会将它们路由到拥有对应专家的 GPU 上处理。
5.2 2026 工业级框架选型:谁执牛耳?
| 推理框架 | 底层杀手锏 | 对 DeepSeek 的支持度 | 最佳应用场景 |
|---|---|---|---|
| vLLM | PagedAttention, 极佳的社区生态。 | ✅ 原生支持 V3/R1 的 TP+PP。 | 通用在线 API 服务,高并发处理。 |
| SGLang | DeepEP (深度专家并行),PD 分离。 | ✅✅ 官方认证,专为大规模 MoE 打造。 | 超大规模生产环境(多节点集群)。 |
| TensorRT-LLM | NVIDIA 亲儿子,算子级极致编译优化。 | ✅ 需要较复杂的构建流程。 | 对延迟 (Latency) 要求极端的实时应用。 |
5.3 生产级代码实战:基于 vLLM 构建高并发 DeepSeek API
假设你有一台装有 4 张 RTX 4090 (24G) 或 A100 (80G) 的服务器,以下代码展示了如何将其打造成高可用服务:
import time
from vllm import LLM, SamplingParams
def deploy_deepseek_cluster():
# 工业级初始化参数
print("🚀 启动 vLLM 分布式推理引擎...")
llm = LLM(
model="deepseek-ai/DeepSeek-V3-AWQ",
tensor_parallel_size=4, # TP=4,4卡并行处理一个模型
gpu_memory_utilization=0.90, # 预留 10% 显存防 OOM
max_model_len=16384, # 支持 16K 超长上下文
quantization="awq", # 明确声明量化后端
enforce_eager=False, # 启用 CUDA Graph 加速小 Batch
trust_remote_code=True,
)
# 定义生成参数:适合编写代码和逻辑推理
sampling_params = SamplingParams(
temperature=0.6,
top_p=0.9,
max_tokens=2048,
repetition_penalty=1.1
)
prompts =[
"作为资深架构师,请用 Python 实现一个高并发的分布式 ID 生成器(雪花算法)。",
"用通俗的语言解释什么是量子计算中的薛定谔的猫。"
]
start_time = time.time()
# 批处理推理请求
outputs = llm.generate(prompts, sampling_params)
# 打印结果与性能指标
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"\n📝 Prompt: {prompt}")
print(f"🤖 Response: {generated_text[:100]}...\n" + "-"*50)
print(f"⏱️ 总耗时: {time.time() - start_time:.2f}s")
if __name__ == "__main__":
deploy_deepseek_cluster()
避坑指南:血与泪的 MLOps 经验
作为过来人,给你几条价值百万的排坑建议:
- 量化导致智商下降(精度崩塌)?
对于 DeepSeek 等代码和逻辑能力极强的模型,绝对不要随意使用INT8权重量化(会严重破坏数值分布)。优先采用 AWQ 格式,或者采用混合精度(把重要的底层和输出层保留为 FP16)。 - 多卡推理反而变慢?
检查你的硬件拓扑!使用nvidia-smi topo -m查看。如果多卡之间是通过低速的 PCIe 甚至 CPU 通信,而不是 NVLink,那么张量并行(TP)带来的通信开销会彻底吞噬计算收益。此时应改用流水线并行(PP)。 - 显存利用率上不去?
启用 PD 分离 (Prefill-Decode Disaggregation)。由于 Prompt 处理(Prefill)是计算密集型,而生成(Decode)是显存带宽密集型,把这两者分流到不同的 GPU 节点上,能让吞吐量飙升 2 倍以上。
🔮 未来展望:显存优化技术的下一站
在 AI 硬件演进的洪流中,显存之战远未结束。站在 2026 年的节点上,我们已经看到了下一代技术的曙光:
- BitNet b1.58 的降维打击:用三值量化
{-1, 0, +1}代替传统的浮点数。微软的这项研究让乘法运算变成了纯加法,未来的模型显存占用将缩小几十倍。 - CXL 3.0 内存池化技术:GPU 不再局限于自己的独立显卡内存。通过 CXL 总线,GPU 可以直接把主板上的几 TB DDR5 内存当作显存来用,“显卡”这个概念可能将被重新定义。
- AI 编译器的无政府状态结束:诸如 TensorRT 甚至更底层编译器,正在利用强化学习自动搜索每一层模型的最优量化与并行策略,告别“手动调参炼丹”。
🎯 结语
从对抗令人窒息的 CUDA OOM,到从容地利用 vLLM 分发千万级请求;从粗糙的 INT8 截断,到精致的 AWQ 激活感知量化。大模型的部署,就是一部不断榨干硬件极限的“暴力美学”史。
DeepSeek 是开源社区送给我们的最强利器,而掌握了模型量化、动态优化与分布式扩展的你,已经拥有了驾驭这把利器的绝世剑法。不要让几条红色的报错阻挡你探索 AGI 的脚步,打开终端,开始实战吧!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)