大模型推理引擎vLLM(11): vLLM PD分离相关问题和代码
文章目录
本博客是看学习视频的简单笔记,视频地址:[EP03] 大模型推理,从vllm看PD分离,感兴趣的可以直接去看原视频
1 什么是P D
没什么好说的,就是prefill和decode。
2 为什么要做PD分离

3 两个解决方案
前面说了所谓的prefill的调度方案存在的问题就是prefill会把其他用户的decode过程给停住,解决这个问题自然就是prefill的时候不要让decode停,也就是让prefill和decode同时做。
那么具体有两个方法,一个是PD分离,一个就是chunk prefill,
- PD分离:简单说就是比如我们用两个GPU,一个GPU做predill,另一个GPU做decode.
- chunk prefill:其实就是将prefill分块,然后去和docode合到一起做混合batch,也能让prefill和decode同时计算。
4 chunk prefill
chunk size的问题:
- chunk size 设置的太大,那么在这个batch里面的一个docode需要等待一个巨长的prefill处理结束,那么docode的时间变长了。
- chunksize 设置的太小,那么GPU利用率下降了,然后处理完一个prefill又需要很多次才能处理完,那么相当于prefill的时间又变慢了。
5 question
5.1 forward函数
vllm/vllm/model_executor/models/llama.py中的forward函数
def forward(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
) -> torch.Tensor:
qkv, _ = self.qkv_proj(hidden_states)
# if os.environ.get('FA_PAD') == '1' and self.quant_method is None:
# qkv = qkv[...,:-32]
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q, k = self.rotary_emb(positions, q, k)
attn_output = self.attn(q, k, v)
output, _ = self.o_proj(attn_output)
return output
这个函数其实就是根据token词嵌入之后得到的矩阵,球了Q K V,这里求的时候是做了一次矩阵运算,然后求出 QK V之后又增加了位置信息,然后做了注意力运算。
6 PD分离实现问题

6.1 How to transformer KV cache
- polling mode:其实就相当于内存池,发送者将KV cache写到池子中,然后接收者从池子中去拿,
- p2p model:发送者和接受者相互知道是谁,然后直接点对点的传输。
具体的库,
- LMCache:同时支持上面说的这两种mode。LMCache算是一个既支持kv transformer也支持kv extracttion,
- MoonCake:用的是polling mode
- MIXL: 用的是P2P mode。
相当于kv 的传输被从vllm中拿出来了,vllm调用这些库去做kv cache的传输。
6.2 How to extract (and inject) KV cache from (to) vLLM
connector API在哪里被调用的,在vllm/vllm/worker/model_runner.py文件中有下面的两个函数,一个recv,一个send,
bypass_model_exec = False
if self.need_recv_kv(model_input, kv_caches):
hidden_or_intermediate_states, bypass_model_exec, model_input = \
get_kv_transfer_group().recv_kv_caches_and_hidden_states(
# model is used to know which layer the current worker
# is working on, so that we can receive KV for only those
# layers.
model_executable,
model_input,
kv_caches=kv_caches
)
和
# Sending KV cache in distributed KV cache transfer setting
# NOTE: the send operation is non-blocking
if self.need_send_kv(model_input, kv_caches):
get_kv_transfer_group().send_kv_caches_and_hidden_states(
# model_executable is used to know which layer the current
# worker is working on, so that we can send KV for only those
# layers.
model_executable,
model_input,
kv_caches,
hidden_or_intermediate_states,
)

这里就是在model forward之前先接收kv cache,然后forward之后就send KV cache。
然后这里具体的recv和send的实现是在vllm/vllm/distributed/kv_transfer/kv_connector,
这里面有lmcache_connector,有mooncake_connector,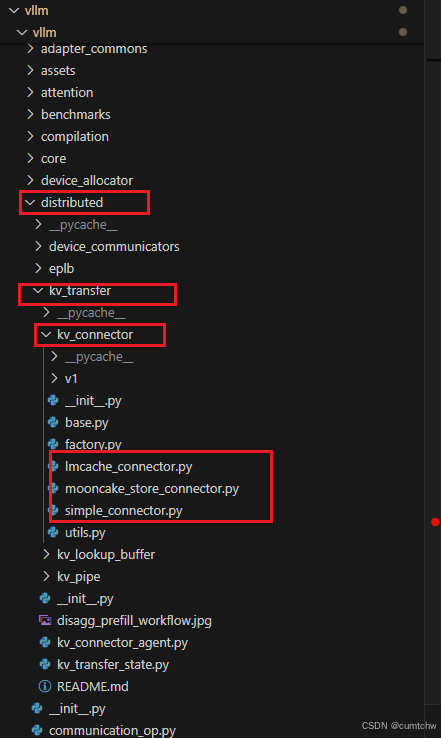
然后在vllm/vllm/distributed/kv_transfer/kv_connector_agent.py是相当于接口层。
def send_kv_caches_and_hidden_states(
self,
model_executable: torch.nn.Module,
model_input: "ModelInputForGPUWithSamplingMetadata",
kv_caches: list[torch.Tensor],
hidden_or_intermediate_states: Union[torch.Tensor,
IntermediateTensors],
) -> None:
self.connector.send_kv_caches_and_hidden_states(
model_executable, model_input, kv_caches,
hidden_or_intermediate_states)
def close(self) -> None:
self.connector.close()
def recv_kv_caches_and_hidden_states(
self, model_executable: torch.nn.Module,
model_input: "ModelInputForGPUWithSamplingMetadata",
kv_caches: list[torch.Tensor]
) -> tuple[Union[torch.Tensor, IntermediateTensors], bool,
"ModelInputForGPUWithSamplingMetadata"]:
return self.connector.recv_kv_caches_and_hidden_states(
model_executable, model_input, kv_caches)
6.3 When to send the request to P and D node
当user来了一个request,那么应该在什么时间点将request发给P node,在什么时间点将request发给D node。
由于有了PD分离,那么P instance 和D instance都需要拿到user的request,那么这里面就有怎么复制request,以及怎么给P D 发request的问题了。
- first P then D
- first D then P

参考文献

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)