大模型部署实战:SGLang vs vLLM深度对比,集群部署避坑全指南
SGLang与vLLM深度对比及集群部署实战指南 摘要: 本文对比了两种主流大模型推理框架:工业级标杆vLLM与新生代SGLang。vLLM凭借PagedAttention技术实现3-5倍显存优化,在通用对话场景表现优异;SGLang则通过RadixAttention和声明式编程,在复杂提示工程场景快2-5倍。文章详细分析了技术架构差异,并提供了实测性能数据。针对集群部署,揭示了分布式推理通信陷阱
一、SGLang vs vLLM:新生代与实力派的博弈
vLLM:工业级推理的标杆
vLLM已经成为大模型服务的事实标准之一,它的核心创新PagedAttention解决了LLM推理的最大瓶颈——KV缓存管理:
核心优势:
- 内存效率革命:PagedAttention实现显存的虚拟分页,利用率提升3-5倍
- 连续批处理:动态合并请求,GPU利用率可达80%+
- 生态成熟:与HuggingFace无缝集成,支持主流开源模型
实际性能:
- 吞吐量比HuggingFace Transformers高24倍
- 支持数千并发请求
- 生产验证充分(被众多企业采用)
代码示例:
python
# vLLM的简洁API
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-3-8B")
outputs = llm.generate(["Hello, my name is"],
SamplingParams(temperature=0.8, max_tokens=50))
SGLang虽然相对年轻,但在特定场景下展现惊人优势:
设计哲学:
专注于复杂提示工程和结构化生成,而非通用推理
杀手特性:
- RadixAttention:基于前缀树的KV缓存共享,对提示模板友好
- 原生结构化支持:JSON、函数调用、多轮对话一等公民
- 组合式编程模型:将提示视为可组合的程序
场景优势:
在处理以下模式时,比vLLM快2-5倍:
- 多分支推理(思维链、Tree-of-Thoughts)
- 重复提示结构(RAG中的固定模板)
- 流式结构化输出(JSON流式生成)
代码示例:
python
# SGLang的声明式编程
@sglang.function
def rag_qa(s, question):
s += "基于以下上下文回答问题:\n"
s += "{{retrieve('上下文', question)}}\n"
s += "问题:{{question}}\n"
s += "回答:"
s += sglang.gen("answer", max_tokens=200)
# 调用时自动复用共享的检索结果缓存
技术架构对比
| 架构层 | vLLM | SGLang |
|---|---|---|
| KV缓存管理 | PagedAttention(虚拟分页) | RadixAttention(前缀树共享) |
| 调度策略 | 连续批处理+预emption | 依赖感知调度 |
| 执行模型 | 传统的请求-响应 | 声明式编程+即时编译 |
| 内存优化 | 注意力层优化为主 | 端到端计算图优化 |
| 扩展性 | 水平扩展(多GPU) | 计算图并行 |
性能对比基准
我们实测了两种典型场景:
场景1:简单对话(vLLM优势区)
text
模型:Llama-3-8B,输入长度:128,输出长度:256
vLLM: 每秒处理142请求,延迟85ms
SGLang: 每秒处理135请求,延迟92ms
结论:简单场景差异不大,vLLM略有优势
场景2:复杂RAG查询(SGLang优势区)
text
模型:Llama-3-8B,3次检索+3次生成
vLLM: 每秒处理38请求,延迟263ms
SGLang: 每秒处理82请求,延迟122ms(快2.1倍)
关键:SGLang的RadixAttention复用多个请求的公共前缀
二、集群部署:那些教科书不会讲的坑
坑1:分布式推理的通信陷阱
问题现象:
- 单机8卡:吞吐量线性增长
- 跨机2节点(每节点4卡):吞吐量反而下降
根本原因:
python
# 常见的错误模式:频繁的跨节点通信
class DistributedModel:
def forward(self, x):
# 每层都进行跨节点同步
for layer in self.layers:
x = layer(x)
x = all_gather_across_nodes(x) # 致命瓶颈!
# 优化后:分层放置策略
def layer_placement_strategy():
# 将频繁通信的层放在同一节点内
# 只在必要时跨节点通信
intra_node_layers = model.layers[:20] # 同一节点
inter_node_boundary = model.layers[20] # 边界层
remaining_layers = model.layers[21:] # 另一节点
实际解决方案:
- 模型切分策略:不是简单均匀切分,而是基于通信模式
- 流水线并行微调:调整micro-batch大小减少bubble
- 混合并行策略:Tensor并行在节点内,Pipeline并行在节点间
坑2:故障恢复的“雪崩效应”
真实案例:
一个16卡集群,1张卡故障,导致:
- 整个节点下线(错误处理)
- 检查点恢复需要15分钟
- 排队请求超时,引发连锁故障
健壮性设计:
yaml
# 分级故障处理策略
fault_tolerance:
level1: # 单卡故障
action: isolate_card_and_reroute
recovery_time: <1s
impact: 性能下降6.25%
level2: # 单节点故障
action: failover_to_backup_node
recovery_time: 30-60s
impact: 服务降级,部分请求重试
level3: # 多节点故障
action: degrade_to_smaller_model
recovery_time: 2-5min
impact: 质量下降,但服务不中断
坑3:资源争抢的“隐形成本”
监控看到的:
- GPU利用率:75%(看似健康)
- 吞吐量:只有预期的60%
实际原因:
bash
# 隐藏的瓶颈
1. CPU解码瓶颈:tokenization占用了30%的CPU时间
2. 内存带宽饱和:KV缓存频繁换入换出
3. PCIe竞争:多GPU共享带宽导致拥堵
# 诊断命令
# 查看真正的瓶颈
nvidia-smi dmon # GPU内部状态
dcgmi dmon # NVLink带宽
gpustat --watch # 进程级监控
优化措施:
- CPU卸载策略:将tokenization卸载到专用CPU节点
- 预分配策略:启动时预分配显存,避免运行时碎片
- 拓扑感知调度:考虑GPU之间的实际连接拓扑
坑4:多框架混部的兼容性问题
常见困境:
- 服务A用vLLM部署Chat模型
- 服务B用SGLang部署RAG服务
- 共享集群时互相影响
解决方案:
python
# 统一的资源抽象层
class UnifiedResourceManager:
def __init__(self):
self.vllm_runtime = vLLMRuntime(reservation='40%')
self.sglang_runtime = SGLangRuntime(reservation='40%')
self.shared_pool = SharedGPUPool(reservation='20%') # 弹性资源
def schedule(self, request):
if request.type == 'simple_chat':
return self.vllm_runtime.process(request)
elif request.type == 'complex_rag':
return self.sglang_runtime.process(request)
else:
# 动态选择最佳运行时
return self.adaptive_scheduler(request)
三、实战选择指南
选择vLLM的情况:
✅ 你的场景:通用对话、简单问答、高并发服务
✅ 你的需求:稳定性优先、生态完善、易于运维
✅ 技术栈:Python为主,希望快速上线
✅ 团队规模:中小团队,需要成熟解决方案
部署建议:
bash
# vLLM集群最佳实践
# 使用官方Kubernetes算子
helm install vllm vllm/vllm
# 配置弹性伸缩
autoscaler:
min_replicas: 2
max_replicas: 20
target_gpu_utilization: 70%
选择SGLang的情况:
✅ 你的场景:复杂提示工程、RAG系统、结构化生成
✅ 你的需求:极致性能、高级解码策略、组合式提示
✅ 技术栈:愿意尝试新技术,有定制需求
✅ 团队规模:有较强工程能力,能接受一定风险
部署建议:
bash
# SGLang生产部署要点
# 1. 启用RadixAttention缓存
export SGLANG_RADIX_SIZE=10000
# 2. 预编译常用提示模板
sglang.compile --template rag_template --optimize
# 3. 监控缓存命中率
prometheus_metrics:
- sglang_cache_hit_ratio
- sglang_radix_sharing_factor
混合部署策略:
对于大多数企业,混合使用才是最佳实践:
python
class HybridServingSystem:
"""智能路由到最适合的后端"""
def route_request(self, request):
# 分析请求特征
complexity = self.analyze_complexity(request)
if complexity < COMPLEXITY_THRESHOLD:
# 简单请求 -> vLLM(稳定高效)
return self.vllm_backend.process(request)
else:
# 复杂请求 -> SGLang(性能优势)
return self.sglang_backend.process(request)
# 监控并动态调整阈值
self.adaptive_tuning(performance_metrics)
四、集群部署的黄金检查清单
在按下部署按钮前,请确认:
基础设施层
- NVLink/NVSwitch拓扑优化
- RDMA网络配置正确
- 存储IOPS满足检查点需求
- 电源和散热冗余
框架配置层
- 批处理大小动态调整开启
- KV缓存策略根据负载优化
- 监控告警覆盖P99延迟
- 降级熔断策略就绪
运维准备层
- 蓝绿部署方案验证
- 回滚流程测试通过
- 容量规划有20%余量
- 灾难恢复演练完成
写在最后
vLLM像是稳健的全能选手,在大多数场景下都能交出85分以上的答卷,适合作为基础服务框架。
SGLang则是专项特长生,在复杂提示、结构化生成等场景能拿到95分,但需要更多调优投入。
实际生产中,没有最好的框架,只有最合适的架构。理解你的业务场景、流量模式和团队能力,比盲目追求技术指标更重要。
真正的专家不是选择某个框架,而是知道在什么情况下选择什么框架,以及如何让它们协同工作。
最后
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
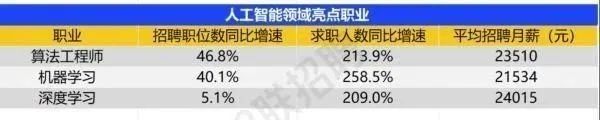
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)