手把手教你在AutoDL上用LLaMA-Factory微调GPT-OSS-20B模型(LoRA版)
本教程详细讲解如何在AutoDL云GPU上使用LLaMA-Factory框架微调GPT-OSS-20B大语言模型,包含完整的环境配置、训练流程、权重合并以及vLLM推理部署全流程。文章最后还分享了笔者踩过的坑和解决方案,建议收藏备用!
本教程详细讲解如何在AutoDL云GPU上使用LLaMA-Factory框架微调GPT-OSS-20B大语言模型,包含完整的环境配置、训练流程、权重合并以及vLLM推理部署全流程。文章最后还分享了笔者踩过的坑和解决方案,建议收藏备用!
前言
最近在做一个智能采购相关的项目,需要对大语言模型进行微调,让它能够更好地理解采购场景的业务需求。在对比了多种方案后,最终选择了LLaMA-Factory + LoRA的组合,原因主要有三点:
- 开箱即用:LLaMA-Factory提供了非常完善的训练框架,支持多种微调方式
- 显存友好:LoRA相比全参数微调,显存占用大幅降低
- 效果不错:在采购对话场景下,LoRA微调已经能够满足业务需求
本文将完整记录从环境配置到模型部署的全过程,希望能够帮助到有同样需求的小伙伴。
一、方案概览
在开始之前,先来看一下整体的技術方案:
| 组件 | 选择 | 说明 |
|---|---|---|
| 微调框架 | LLaMA-Factory 0.9.4 | 开源的大模型训练框架 |
| 基础模型 | GPT-OSS-20B | 200亿参数的MoE大模型 |
| 微调方式 | LoRA | 低秩适配,显存友好 |
| 推理引擎 | vLLM | 高性能推理加速 |
| 实验监控 | SwanLab | 可视化训练过程 |
| GPU资源 | AutoDL H20 | 性价比较高的云GPU |
| 远程传文件 | WinSCP | Windows上免费开源的图形化安全文件传输工具,用于本地与远程服务器之间加密上传、下载、管理文件 |
二、环境配置
在AutoDL租用实例时,镜像配置非常关键,选错了会导致各种兼容性问题。
推荐配置:
| 参数 | 选择 | 说明 |
|---|---|---|
| 基础镜像 | PyTorch | |
| Ubuntu | 22.04 | |
| Python | 3.12 | 必须3.11+,LLaMA-Factory要求 |
| CUDA | 12.8 | 版本不能太低 |
| PyTorch | 2.8.0 |
⚠️ 重要提醒:GPT-OSS模型默认会尝试使用Flash Attention 3,但该特性目前仅支持Hopper架构GPU(如H100/H800等)。
三、项目初始化
3.1 克隆LLaMA-Factory
# 进入工作目录
cd /root/autodl-tmp
# 如果目录不存在,先创建
mkdir -p /root/autodl-tmp
# 下载LLaMA-Factory 0.9.4版本
# 方法一:从GitHub下载
wget https://github.com/hiyouga/LLaMA-Factory/archive/refs/tags/v0.9.4.zip
unzip v0.9.4.zip
mv LlamaFactory-0.9.4 LLaMA-Factory
# 方法二:直接从本地拖拽上传
# 将下载的zip文件解压后拖拽到 /root/autodl-tmp 目录
3.2 安装依赖
cd /root/autodl-tmp/LLaMA-Factory
# 安装基础依赖
pip install -e '.[torch,metrics]' -i https://pypi.tuna.tsinghua.edu.cn/simple
# 如果遇到 evaluate 库缺失,手动安装
pip install evaluate scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
# 验证安装
python -c "import llamafactory, torch; print('LLaMA-Factory版本:', llamafactory.__version__)"
3.3 下载基础模型
使用ModelScope下载GPT-OSS-20B模型:
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
# 下载模型(约20GB)
modelscope download --model openai-mirror/gpt-oss-20b \
--local_dir /root/autodl-tmp/models/gpt-oss-20b
💡 提示:模型下载需要较长时间,建议在不需要使用GPU时就开始下载,这样可以节省GPU计费时间。
3.4 安装SwanLab
pip install swanlab
安装完成后,需要在训练配置中进行设置(详见下一节)。
四、训练配置
4.1 数据集准备
本方案使用两个数据集:
- identity_fixed:根据identity自定义模型身份信息(填充了其中的name参数和author参数)
- alpaca_en_demo:通用的指令微调数据集
identity_fixed数据集示例:
[
{
"instruction": "你好",
"input": "",
"output": "您好,我是智能小助手,一个由刘大漂亮开发的AI助手。"
},
{
"instruction": "你是谁?",
"input": "",
"output": "您好,我是智能小助手,由刘大漂亮发明。我可以为您提供多种多样的服务。"
}
]
4.2 配置文件
编辑 examples/train_lora/gpt_lora_sft.yaml:
# 模型配置
model_name_or_path: /root/autodl-tmp/models/gpt-oss-20b
lora_rank: 8
lora_alpha: 16
lora_dropout: 0.05
# 训练任务配置
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
# 数据集配置
dataset: identity_fixed,alpaca_en_demo
template: gpt_oss #很多文章写的是gpt,实测错误,应该是gpt_oss,参考模板文件`LlamaFactory-0.9.4\src\llamafactory\data\template.py`(template参数,也可以参考:https://github.com/hiyouga/LlamaFactory?tab=readme-ov-file#supported-models)
cutoff_len: 2048
max_samples: 1000
# 训练参数
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
# 验证配置
val_size: 0.1
eval_strategy: steps
eval_steps: 100
load_best_model_at_end: true
# 精度配置
bf16: true
gradient_checkpointing: true
# 日志配置
report_to: swanlab
run_name: gpt-oss-20b-lora
4.3 训练步数计算
理解训练步数的计算有助于预估训练时间:
总样本 = 1090(数据集总量)
训练集 = 1090 × 0.9 = 981个
有效batch = 1 × 8 = 8
每轮步数 = 981 ÷ 8 ≈ 123步
总步数 = 123 × 3轮 = 369步
4.4 开始训练
cd /root/autodl-tmp/LLaMA-Factory
# 开始训练(推荐使用tee同时输出到终端和文件)
llamafactory-cli train examples/train_lora/gpt_lora_sft.yaml \
2>&1 | tee logs/training_$(date +%Y%m%d_%H%M%S).log
训练过程中可以通过SwanLab查看实时的训练曲线:
- 访问 https://swanlab.cn
- 登录后进入对应项目
- 即可查看loss曲线、learning_rate等指标
 在模型训练过程中,会提示上传密钥,这时在swanlab-设置,中的密钥(https://swanlab.cn/space/~/settings),根据终端提示粘贴到终端即可
在模型训练过程中,会提示上传密钥,这时在swanlab-设置,中的密钥(https://swanlab.cn/space/~/settings),根据终端提示粘贴到终端即可
五、权重合并(可选)
权重合并是将LoRA适配器与基础模型合并为一个完整的模型文件。这是可选步骤,不合并也可以直接进行推理。
5.1 为什么要合并?
| 方式 | 优点 | 缺点 |
|---|---|---|
| 合并后推理 | 配置简单,推理速度快 | 需要额外合并步骤 |
| LoRA直接加载 | 无需合并步骤 | 配置稍复杂 |
5.2 合并命令
cd /root/autodl-tmp/LLaMA-Factory
llamafactory-cli export \
--model_name_or_path /root/autodl-tmp/models/gpt-oss-20b \
--adapter_name_or_path saves/gpt-20b/lora/sft \
--export_dir models/gpt20b_lora_sft \
--export_size 2 \
--export_legacy_format false
参数说明:
--model_name_or_path:基础模型路径--adapter_name_or_path:LoRA权重保存路径--export_dir:合并后模型的保存路径
六、vLLM推理部署
vLLM是高性能的推理引擎,支持两种部署方式:
6.1 安装vLLM
pip install vllm fastapi uvicorn pydantic -i https://pypi.tuna.tsinghua.edu.cn/simple
6.2 方案一:直接加载LoRA(不合并权重)⭐推荐
这种方式不需要合并权重,直接动态加载LoRA适配器:
export FLASH_ATTN_FORCE_FA2=1
export DISABLE_FLASH_ATTN_3=1
vllm serve /root/autodl-tmp/models/gpt-oss-20b \
--enable-lora \
--lora-modules gpt-lora=/root/autodl-tmp/LLaMA-Factory/saves/gpt-20b/lora/sft \
--tokenizer /root/autodl-tmp/models/gpt-oss-20b \
--tensor-parallel-size=1 \
--trust-remote-code \
--enable-prefix-caching \
--gpu-memory-utilization 0.9 \
--host 0.0.0.0 \
--port 80 \
--api-key your-secret-api-key
API调用:
curl -X POST "http://你的IP:80/v1/chat/completions" \
-H "Authorization: Bearer your-secret-api-key" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-lora",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 200
}'
6.3 方案二:使用合并后的模型
如果已经完成了权重合并,可以使用合并后的模型:
vllm serve /root/autodl-tmp/LLaMA-Factory/models/gpt20b_lora_sft \
--host 0.0.0.0 \
--port 80 \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--max-model-len 4096 \
--served-model-name gpt-procurement \
--api-key your-secret-api-key

终端出现这个,就代表部署成功了,接下来就可以推理了。
API调用:
curl -X POST "http://你的IP:80/v1/chat/completions" \
-H "Authorization: Bearer your-secret-api-key" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-procurement",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 200
}'
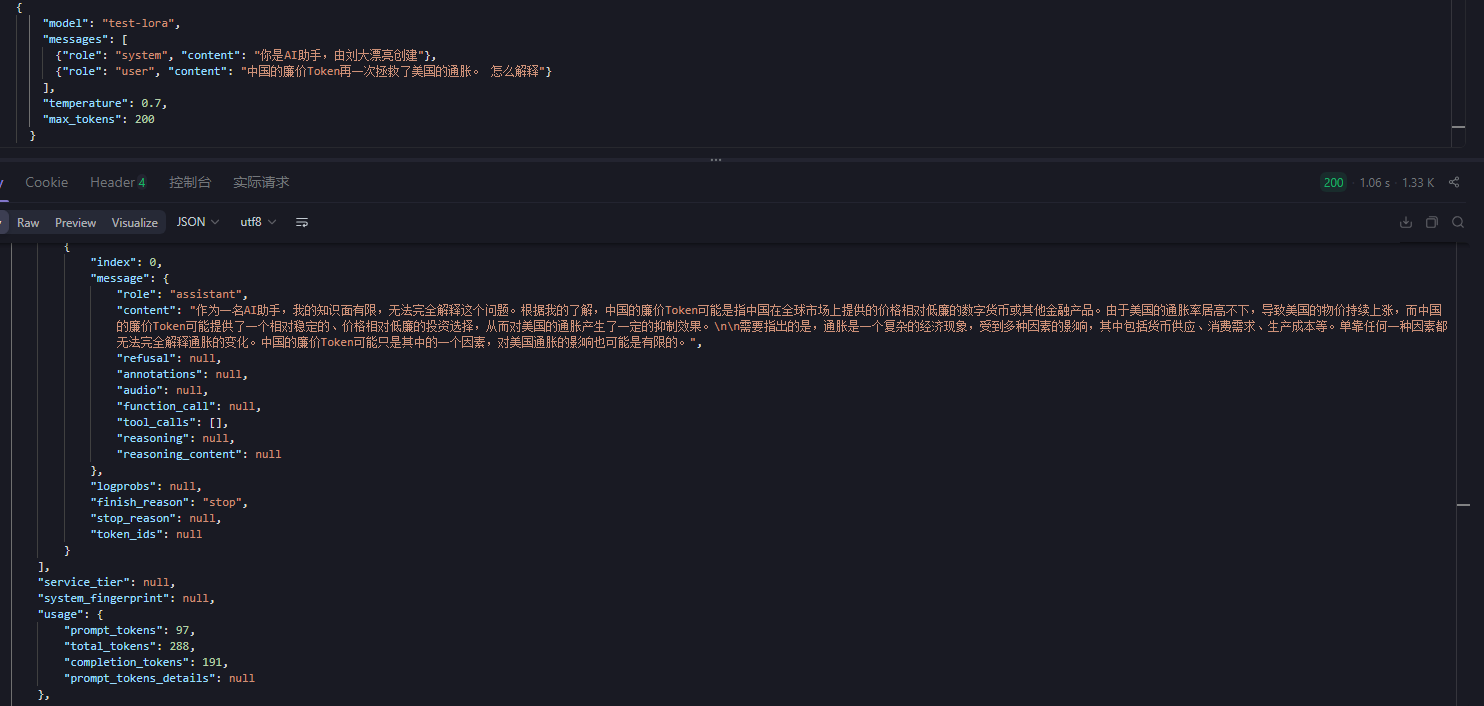
成功调用!
6.4 两种方案对比
| 对比项 | 方案一(LoRA直接加载) | 方案二(合并后使用) |
|---|---|---|
| 是否需要合并 | ❌ 不需要 | ✅ 需要 |
| 配置复杂度 | 稍复杂 | 简单 |
| 推理速度 | 稍慢 | 快 |
| 显存占用 | 略高 | 略低 |
| 灵活切换LoRA | ✅ 支持 | ❌ 不支持 |
| 推荐场景 | 开发测试 | 生产部署 |
七、常见问题汇总
问题1:Token不匹配错误
这个是很隐藏的问题,也是花费我同事很久时间找到的,感谢他!
错误信息:
{
"error": {
"message": "Unexpected token 200002 while expecting start token 200006",
"type": "BadRequestError"
}
}
原因:GPT-OSS模型的模板文件中使用了<|end|>作为结束token,但与实际tokenizer不匹配。
解决方案:
修改 LlamaFactory-0.9.4/src/llamafactory/data/template.py 中的gpt_oss模板:
# 修改前
format_assistant=StringFormatter(slots=["{{content}}<|end|>"]),
# 修改后
format_assistant=StringFormatter(slots=["{{content}}"]),
修改后需要重新训练模型。
问题2:Python版本不匹配
错误信息:
Package 'llamafactory' requires a different Python: 3.10.16 not in '>=3.11.0'
解决方案:创建Python 3.11+的环境
conda create -n py311 python=3.11
conda activate py311
八、总结
本文详细记录了使用LLaMA-Factory在AutoDL上微调GPT-OSS-20B模型的完整流程,包括:
✅ 环境配置与依赖安装
✅ 数据集准备与配置
✅ 模型训练与监控
✅ LoRA权重合并
✅ vLLM推理部署
✅ 常见问题解决方案
整个流程走下来,大约需要:
- 环境配置:30分钟
- 模型下载:1-2小时(视网络情况)
- 模型训练:约1小时(369步)
- 权重合并:10分钟
希望这篇教程能够帮助到你!如果对你有帮助,欢迎点赞、收藏、转发~
九、参考资料
📝 更新日志
- 2026-02-13:初始版本发布
如果有问题,欢迎在评论区留言讨论!

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)