从模型到服务:CANN Recipes-Infer 库让推理部署像“搭积木”一样简单
目标:用结构化配置描述推理部署的“原料”与“工序”,支持 YAML/JSON 格式定义。# 示例:ResNet50 云端高吞吐配方(resnet50_high_throughput.yaml)recipe:scenario: "cloud_high_qps" # 场景标签:云端高吞吐model:source: "resnet50.onnx" # 输入模型(ONNX 格式)target: "resn
在深度学习落地的最后一公里,推理部署往往是最考验工程能力的环节:从模型转换、算子适配、性能调优到服务化封装,每一步都可能暗藏陷阱。尤其是在 CANN 生态中,虽然有 GE 图编译、ops-transformer 等底层加速库,但如何将这些能力串联成一条端到端的高效推理流水线,仍是许多开发者的痛点。
华为 CANN 生态中的 cann-recipes-infer 库(全称 CANN Inference Recipes,推理配方库),正是为解决这一问题而生。它是一套 面向 CANN 平台的“端到端推理部署参考方案与工具集”,将模型转换、优化、校准、服务化等环节封装为可复用的“配方”(Recipe),让开发者无需从零造轮子,只需根据业务场景选择合适的配方,即可快速搭建高性能推理服务。如果说 GE 是模型的“编译器”,ops-transformer 是算子的“加速器”,那么 cann-recipes-infer 就是推理部署的“流水线工厂”。
一、cann-recipes-infer 是什么?为什么需要它?
cann-recipes-infer 是 CANN 中专为 推理部署全流程 设计的参考库,核心定位是:提供经过验证的端到端推理方案(配方),覆盖从模型输入到服务输出的全链路,降低部署门槛,提升落地效率。
核心痛点与解决方案
传统 CANN 推理部署流程中,开发者常面临以下问题:
-
流程碎片化:模型转换(如 ONNX→OM)、量化校准、性能调优、服务化需分别查阅多份文档,手动拼接工具链;
-
场景适配难:不同业务场景(如云端高吞吐、边缘低时延、多模型并发)需不同的优化策略,缺乏现成参考;
-
调优成本高:性能瓶颈定位(如算子不支持、内存不足)需反复试错,依赖专家经验;
-
服务化门槛:从模型文件到 REST/gRPC 服务需自行开发封装逻辑,易出错且维护困难。
cann-recipes-infer 的解决方案是 “配方化封装+场景化模板+自动化工具”:
-
配方(Recipe):将特定场景的部署流程固化为可执行的脚本与配置(如“ResNet50 云端高吞吐配方”“BERT 边缘低时延配方”),包含模型转换参数、优化策略、服务化代码;
-
场景化模板:内置 NLP、CV、多模态等主流场景的参考配方,支持一键复用与定制;
-
自动化工具链:集成模型转换(
atc)、性能分析(msprof)、服务化封装(triton适配器)等工具,实现“一键执行→输出可用服务”; -
可观测性增强:内置监控指标(如 QPS、时延、硬件利用率)与日志分析工具,快速定位部署问题。
二、cann-recipes-infer 的核心架构与功能模块
cann-recipes-infer 的架构围绕 “配方定义→流程执行→服务输出→监控运维” 构建,核心模块可分为五大组件(如图 1 所示),覆盖推理部署全生命周期。
(一)配方定义层(Recipe Definition Layer)
目标:用结构化配置描述推理部署的“原料”与“工序”,支持 YAML/JSON 格式定义。
一个典型的配方包含以下要素:
# 示例:ResNet50 云端高吞吐配方(resnet50_high_throughput.yaml)
recipe:
name: "resnet50_high_throughput"
version: "1.0"
scenario: "cloud_high_qps" # 场景标签:云端高吞吐
model:
source: "resnet50.onnx" # 输入模型(ONNX 格式)
target: "resnet50.om" # 输出模型(CANN OM 格式)
precision: "fp16" # 量化精度(fp16/int8)
conversion: # 模型转换参数
atc_tool: "/usr/local/Ascend/atc/bin/atc"
options: "--framework=5 --input_format=NCHW --input_shape='1,3,224,224'"
optimization: # 性能优化策略
enable_operator_fusion: true # 启用 GE 算子融合
enable_dynamic_batch: true # 启用动态 batch 调度
serving: # 服务化配置
framework: "triton" # 服务框架(triton/nginx+custom)
port: 8000 # 服务端口
batch_size: [1, 4, 8, 16] # 支持的 batch 大小
monitoring: # 监控指标
metrics: ["qps", "latency_p99", "npu_util"]关键特性:
-
可继承性:支持配方继承(如“resnet50_int8”继承“resnet50_high_throughput”并修改 precision);
-
参数化:通过变量替换(如
${BATCH_SIZE})支持不同环境的动态配置; -
验证机制:内置 schema 校验,确保配方参数合法(如模型路径存在、端口未被占用)。
(二)流程执行层(Workflow Execution Layer)
目标:根据配方定义,自动执行模型转换、优化、校准、服务化等步骤,支持本地执行与 CI/CD 集成。
核心执行流程包括:
-
模型转换:调用 CANN 的
atc工具将输入模型(ONNX/TensorFlow/PyTorch)转换为 OM 格式,自动注入配方指定的优化参数; -
量化校准(可选):若目标精度为 int8,自动运行校准工具(如
calibration_tool)生成量化参数; -
性能调优:根据配方的
optimization配置,调用 GE 图优化器或 ops-transformer 融合算子; -
服务化封装:生成 Triton Inference Server 的模型仓库配置(
config.pbtxt)或自定义服务的 Flask/FastAPI 代码; -
启动验证:自动启动服务并执行健康检查(如发送测试请求验证响应正确性)。
示例:执行配方
# 克隆 recipes 仓库
git clone https://atomgit.com/cann/cann-recipes-infer.git
cd cann-recipes-infer/recipes/resnet50_high_throughput
# 执行配方(自动完成转换→优化→服务化)
./run_recipe.sh --input_model ../models/resnet50.onnx --output_dir ./deploy(三)场景化模板库(Scenario Templates Library)
目标:提供覆盖主流业务的预定义配方,开发者可直接复用或微调。
内置模板包括:
-
CV 场景:ResNet50/101、YOLOv5/v8、ViT 等图像分类/检测模型的云端高吞吐、边缘低时延配方;
-
NLP 场景:BERT、GPT、LLaMA 等文本模型的动态 batch 优化、长序列支持配方;
-
多模态场景:CLIP、BLIP 等图文模型的跨模态融合推理配方;
-
边缘场景:针对内存/算力受限设备(如 Atlas 200I DK)的轻量化配方(模型剪枝+int8 量化)。
(四)服务化适配层(Serving Adaptation Layer)
目标:适配主流推理服务框架,提供标准化的服务接口与扩展能力。
支持的服务框架:
-
Triton Inference Server:生成符合 Triton 规范的模型仓库(含
model.py、config.pbtxt),支持动态 batch、多模型并发; -
自定义服务:基于 FastAPI/Flask 生成 RESTful API 服务,支持 gRPC 扩展;
-
容器化部署:提供 Dockerfile 模板,支持 Kubernetes 集群部署(含资源限制、自动扩缩容配置)。
(五)监控与诊断层(Monitoring & Diagnostics Layer)
目标:提供服务运行状态的可观测性,快速定位性能瓶颈与错误。
核心功能:
-
指标采集:通过 Prometheus 客户端暴露 QPS、时延分布(P50/P90/P99)、NPU 利用率、内存占用等指标;
-
日志分析:自动解析 CANN 运行时日志(
npu_log_),标记算子执行异常(如超时、内存越界); -
诊断工具:集成
msprof性能分析器与npu-smi硬件监控工具,生成可视化报告(如算子耗时热力图、硬件资源瓶颈分析)。
三、代码示例:基于配方快速部署 BERT 推理服务
下面以 BERT 文本分类模型为例,演示如何使用 cann-recipes-infer 的预定义配方完成部署。
步骤 1:选择并定制配方
从模板库中复制 BERT 动态 batch 配方:
cp -r recipes/bert_dynamic_batch ./my_bert_deploy
cd my_bert_deploy修改 recipe.yaml适配本地环境:
model:
source: "/path/to/bert_base_uncased.onnx" # 替换为实际模型路径
serving:
port: 9000 # 修改服务端口步骤 2:执行配方生成服务
# 执行配方(自动转换 ONNX→OM、优化、生成 Triton 配置)
./run_recipe.sh --input_model ./bert_base_uncased.onnx --output_dir ./deploy执行成功后,deploy目录结构如下:
deploy/
├── model_repository/ # Triton 模型仓库
│ └── bert/
│ ├── config.pbtxt # Triton 配置文件(动态 batch 策略)
│ └── 1/
│ └── model.om # 转换后的 CANN 模型
├── triton_server/ # Triton 服务启动脚本
└── monitor/ # 监控指标与日志配置步骤 3:启动服务并验证
# 启动 Triton 服务
./triton_server/start.sh
# 发送测试请求(验证服务可用性)
curl -X POST http://localhost:9000/v2/models/bert/infer \
-H "Content-Type: application/json" \
-d '{"inputs": [{"name": "input_ids", "shape": [1, 128], "datatype": "INT32", "data": [101, 2023, ...]}]}'通过监控界面(默认 http://localhost:9090)可查看 QPS、时延等指标,确认服务达到预期性能。
四、cann-recipes-infer 的使用流程图
cann-recipes-infer 的核心部署流程可总结为“选择配方→定制配置→执行流程→服务输出→监控运维”,具体流程如图 2 所示: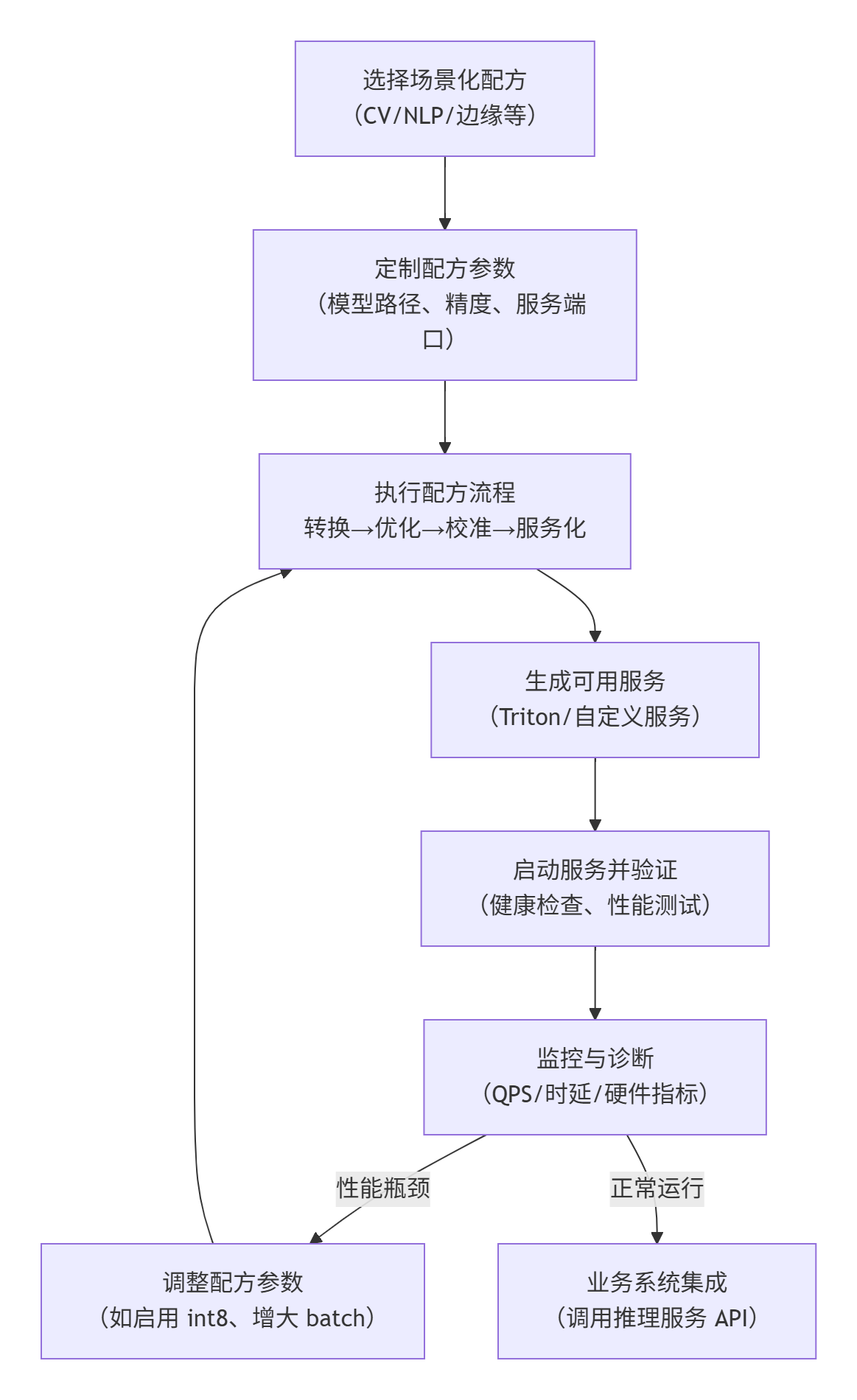
五、cann-recipes-infer 的独特价值
|
维度 |
传统手动部署 |
cann-recipes-infer 配方化部署 |
|---|---|---|
|
部署效率 |
低(数天~数周) |
高(小时级完成) |
|
场景适配性 |
需手动适配多工具链 |
预定义场景模板,一键复用 |
|
性能调优难度 |
依赖专家经验,试错成本高 |
配方内置优化策略,自动生效 |
|
服务化门槛 |
需自行开发封装逻辑 |
自动生成服务代码与配置 |
|
可维护性 |
脚本分散,易丢失 |
配方集中管理,版本可追溯 |
六、典型应用场景
-
企业级模型上线:快速将训练好的模型(PyTorch/TensorFlow)转换为 CANN 可执行服务,满足云端高并发或边缘低时延需求;
-
多模型并发部署:通过配方的动态 batch 与多模型调度策略,在一台服务器上同时运行多个模型(如 ResNet+BERT);
-
边缘设备部署:使用轻量化配方(模型剪枝+int8 量化)将大模型压缩后部署到 Atlas 200I DK 等设备;
-
CI/CD 集成:将配方集成到 Jenkins/GitLab CI 流程,实现模型更新→自动转换→服务滚动升级的全自动化。
七、总结与展望
cann-recipes-infer 库是 CANN 生态中 “推理部署的工程化加速器”,它通过配方化封装将复杂的部署流程转化为可复用、可定制的参考方案,让开发者从“工具链拼凑”中解放出来,聚焦业务逻辑。与 GE 的图优化、ops-transformer 的算子加速、pypto 的 Python 编程形成闭环,cann-recipes-infer 完成了 CANN 从“模型训练”到“服务上线”的最后一块拼图。
未来,随着大模型推理、多模态融合、边缘智能等场景的深化,cann-recipes-infer 将进一步扩展配方库(如 LLaMA 量化部署配方、视频流实时推理配方),并强化与 Kubernetes、Kubeflow 等云原生工具链的集成,成为 CANN 生态中“推理即服务”(Inference as a Service)的核心支撑。
📌 仓库地址:https://atomgit.com/cann/cann-recipes-infer
📌 CANN组织地址:https://atomgit.com/cann

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 6
6 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)