元数据驱动的力量:CANN metadef 库让算子与模型“自描述、自优化”
提供强类型的元数据模式语言下面展示如何用 metadef 定义自定义算子元数据,并在 GE 编译阶段查询其属性。# 创建 FusedGELU 算子元数据inputs=[],outputs=[],},# 注册到全局仓库metadef 库是 CANN 生态的“语义基石”,它通过统一、标准化的元数据管理,打破了工具链间的信息壁垒,让算子、模型、硬件的特性能够被全局感知与智能利用。
在深度学习与高性能计算系统中,“元数据”(Metadata) 常常是被忽视的金矿。它描述了数据的数据:模型的输入输出规格、算子的计算语义、硬件资源需求、约束条件等。如果这些信息能被统一、结构化地管理与利用,不仅可以大幅提升开发效率,还能让系统在编译、优化、部署阶段实现“智能化决策”。
华为 CANN 生态中的 metadef 库(全称 Metadata Definition Library,元数据定义库),正是为此而生。它是一个 面向 CANN 生态的统一元数据建模与解析框架,让算子、模型、硬件资源等信息可以被“自描述”,并在整个工具链(GE 图编译、asc-devkit 算子开发、pypto Python 编程等)中实现元数据的自动流转与智能优化。
如果说 GE 是模型的“交通指挥官”,asc-devkit 是算子的“开发助手”,那么 metadef 就是整个 CANN 生态的“语义中枢”与“知识图谱引擎”。
一、metadef 是什么?为什么需要它?
metadef 是 CANN 中专为 元数据统一管理 设计的库,核心定位是:
-
标准化描述:提供一套通用的 schema(模式)定义算子、模型、硬件的特性与约束;
-
跨工具链互通:让 GE、asc-devkit、pypto、pto-isa 等工具共享一致的元数据,避免“信息孤岛”;
-
智能化驱动:基于元数据实现自动优化决策(如算子融合策略选择、硬件资源分配)。
核心痛点与解决方案
在传统 CANN 开发流程中,元数据往往散落在不同地方:
-
算子开发者在代码注释或文档里描述输入输出规格;
-
模型转换工具用私有 JSON 描述模型结构;
-
硬件适配层用 C++ 宏定义算力参数;
-
优化器靠启发式规则“猜测”最佳策略。
这种碎片化的元数据管理会导致:
-
信息不一致:同一算子在 GE 与 asc-devkit 中的描述不同,引发编译错误;
-
优化受限:优化器无法获取完整的算子语义(如是否支持原位操作、是否可融合);
-
维护成本高:算子升级时需手动同步多处描述,易遗漏。
metadef 的解决方案是 “单一可信源 + 强类型 schema + 自动同步”:
-
所有工具从 metadef 定义的 schema 生成代码与配置;
-
元数据变更时自动触发下游工具更新;
-
支持运行时查询与推理(如“找出所有支持 FP16 且可融合的 Attention 算子”)。
二、metadef 的核心架构与功能模块
metadef 的架构围绕 “Schema 定义 → 元数据实例 → 解析与查询 → 优化驱动” 构建,核心模块可分为四层(如图 1 所示):
(一)Schema 定义层(Schema Definition Layer)
提供 强类型的元数据模式语言(基于 JSON Schema 扩展),描述三类核心实体:
1. 算子元数据(Operator Metadata)
定义算子的输入输出类型、形状约束、属性、支持的硬件特性等。例如:
{
"operator": "FusedAttention",
"version": "1.0",
"inputs": [
{"name": "q", "dtype": "float16", "shape": ["batch", "seq_len", "hidden_dim"]},
{"name": "k", "dtype": "float16", "shape": ["batch", "seq_len", "hidden_dim"]},
{"name": "v", "dtype": "float16", "shape": ["batch", "seq_len", "hidden_dim"]}
],
"outputs": [
{"name": "out", "dtype": "float16", "shape": ["batch", "seq_len", "hidden_dim"]}
],
"attributes": {
"num_heads": {"type": "int", "default": 12},
"supports_inplace": false,
"dynamic_shape": true
},
"hardware_support": ["ai_core_300i", "ai_core_910b"]
}2. 模型元数据(Model Metadata)
描述模型的整体结构、子图划分、输入输出规格、性能指标等。例如:
{
"model": "BertBase",
"version": "1.0",
"subgraphs": [
{"name": "embedding", "operators": ["Embedding"]},
{"name": "encoder_layer", "operators": ["FusedAttention", "FusedFFN"]}
],
"input_spec": {"shape": ["batch", "seq_len"], "dtype": "int32"},
"output_spec": {"shape": ["batch", "seq_len", "hidden_dim"], "dtype": "float16"}
}3. 硬件元数据(Hardware Metadata)
定义 CANN 硬件的资源特性(如 AI Core 数量、向量指令集、内存带宽)。例如:
{
"hardware": "ai_core_910b",
"compute_units": {"vector_width": 128, "matrix_units": 64},
"memory": {"global_bandwidth": "1.2TB/s", "shared_memory_per_block": "64KB"},
"supported_dtypes": ["float16", "bfloat16", "int8"]
}(二)元数据实例层(Metadata Instance Layer)
基于 Schema 创建具体的元数据实例,支持 静态定义(代码生成时)与 动态注册(运行时发现新算子)。
-
静态实例:通过 metadef 的 Python/JSON 接口预定义常用算子与模型的元数据;
-
动态实例:asc-devkit 开发的新算子可自动生成 metadef 描述并注册到全局仓库。
(三)解析与查询层(Parsing & Query Layer)
提供 高效解析器 与 类 SQL 查询接口,支持工具链在编译/运行时检索元数据:
import metadef as md
# 查询所有支持动态 Shape 且可运行在 ai_core_910b 的 Attention 算子
query = """
SELECT operator FROM operators
WHERE attributes.dynamic_shape = true
AND hardware_support CONTAINS 'ai_core_910b'
AND operator LIKE '%Attention%'
"""
results = md.query(query)
print(results) # ['FusedAttention', 'SparseAttention'](四)优化驱动层(Optimization Driver Layer)
基于查询结果自动生成优化策略,例如:
-
GE 图编译:根据算子元数据决定是否融合(如
FusedAttention与FusedFFN可融合); -
asc-devkit:根据硬件元数据推荐最佳 tile 大小;
-
pypto:根据算子属性选择 JIT 编译策略(如动态 Shape 算子启用运行时重编译)。
三、代码示例:用 metadef 定义并查询算子元数据
下面展示如何用 metadef 定义自定义算子元数据,并在 GE 编译阶段查询其属性。
步骤 1:定义算子元数据(Python API)
import metadef as md
# 创建 FusedGELU 算子元数据
gelu_meta = md.OperatorMetadata(
name="FusedGELU",
version="1.0",
inputs=[
md.TensorSpec(name="x", dtype="float16", shape=["batch", "dim"])
],
outputs=[
md.TensorSpec(name="y", dtype="float16", shape=["batch", "dim"])
],
attributes={
"approximate": {"type": "bool", "default": True},
"dynamic_shape": True
},
hardware_support=["ai_core_300i", "ai_core_910b"]
)
# 注册到全局仓库
md.register_operator(gelu_meta)步骤 2:在 GE 编译阶段查询并决策融合
# GE 图优化阶段的伪代码
def should_fuse_attention_and_gelu(attention_op, gelu_op):
# 查询 attention_op 是否支持与 gelu_op 融合
attn_meta = md.get_operator_metadata("FusedAttention")
gelu_meta = md.get_operator_metadata("FusedGELU")
# 条件:两者都支持动态 Shape 且在相同硬件上
if (attn_meta.attributes["dynamic_shape"] and
gelu_meta.attributes["dynamic_shape"] and
set(attn_meta.hardware_support) & set(gelu_meta.hardware_support)):
return True
return False
# 在 GE 优化器中调用
if should_fuse_attention_and_gelu(attn_node, gelu_node):
ge_graph.fuse_nodes(attn_node, gelu_node)metadef 的使用流程图
metadef 的核心工作流可总结为“Schema 定义 → 实例注册 → 解析查询 → 优化驱动”,具体流程如图 2 所示: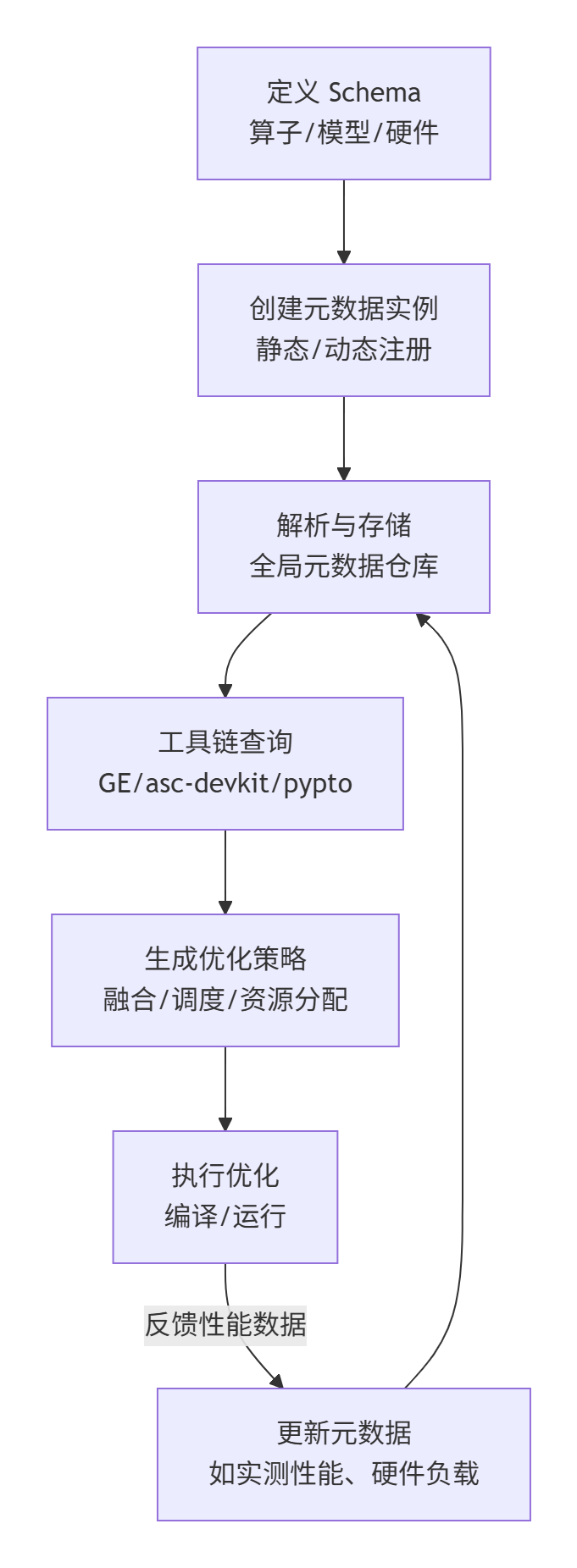
五、metadef 的独特价值
|
维度 |
传统碎片化元数据 |
metadef 统一元数据 |
|---|---|---|
|
信息一致性 |
低(多源易冲突) |
高(单一可信源) |
|
跨工具链互通 |
需手动适配 |
自动同步 |
|
优化智能化程度 |
启发式规则 |
基于完整语义推理 |
|
维护成本 |
高(多处修改) |
低(一次定义) |
|
动态扩展能力 |
弱(需改多处) |
强(插件式注册) |
六、典型应用场景
-
算子库标准化:企业内部多团队协作开发算子时,用 metadef 确保接口与属性描述一致;
-
模型-硬件匹配:自动筛选适合目标硬件的模型子图(如边缘设备选择低算力子图);
-
动态优化决策:运行时根据硬件负载与输入 Shape 查询元数据,调整算子融合策略;
-
文档与测试自动化:从元数据生成算子文档与测试用例(如边界值测试基于 shape 约束)。
七、总结与展望
metadef 库是 CANN 生态的 “语义基石”,它通过统一、标准化的元数据管理,打破了工具链间的信息壁垒,让算子、模型、硬件的特性能够被全局感知与智能利用。与 GE 的图优化、asc-devkit 的算子开发、pypto 的 Python 编程形成深度协同,metadef 让整个 CANN 工具链从“经验驱动”迈向“数据驱动”。
未来,随着大模型与多模态应用的普及,metadef 将进一步扩展对 稀疏性、量化策略、分布式部署 等元数据的支持,并结合机器学习技术实现 元数据的自动补全与优化建议,成为 CANN 生态的“知识大脑”。
📌 仓库地址:https://atomgit.com/cann/metadef
📌CANN组织地址:https://atomgit.com/cann

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 9
9 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)