玩转 catlass 库:CANN 上的“模板级”高性能数学运算利器
catlass 是 CANN 面向底层开发者的“性能神器”,它以模板化 + 构件化 的方式,把硬件特性转化为可编程的优化空间,让开发者既能保持高效开发,又能逼近硬件的理论峰值性能。与 ops-math 的易用性、hixl 的跨语言协作、GE 的图优化形成互补,catlass 在 CANN 生态中承担了“算子性能天花板” 的角色。
在深度学习与高性能计算领域,数学运算库一直是底层性能的核心支柱。CANN 生态中除了我们前面介绍的 ops-math(基础数学运算)、hixl(跨语言交互)与 GE(图编译引擎),还有一个面向 极致性能优化 的底层库—— catlass(源于 “CANN Template-based Linear Algebra Subroutine Library” 的概念),它是面向 CANN 硬件量身打造的 模板化高性能线性代数与张量运算库。如果说 ops-math 是“瑞士军刀”,那么 catlass 就是为特定任务精工锻造的“手术刀”,可以在算子开发者和底层性能工程师手中发挥出极限算力。
一、catlass 是什么?为什么要用模板化设计?
catlass 是 CANN 提供的面向 模板化开发 的高性能数学运算库,专注于 矩阵乘法、张量收缩、批量运算、低精度加速 等核心计算场景。它的设计理念来源于 NVIDIA 的 CUTLASS,但完全针对 CANN 的 AI Core、向量计算单元及内存层次结构做了深度优化。
核心特点
-
模板化编程模型
-
运算逻辑由 C++ 模板参数驱动(数据类型、布局、分块策略、流水线阶段数等),编译器可在实例化时展开为最优代码。
-
支持 编译期融合 与 硬件特性特化(如针对 CANN FP16 / INT8 的向量指令集优化)。
-
-
多层次分块与调度
-
将大规模矩阵/张量运算拆分为 Thread Block → Warp → Vector 三级粒度,充分贴合 CANN 硬件的并行执行模型。
-
自动选择最佳 tile 大小与共享内存布局,减少全局内存访问。
-
-
零额外抽象开销
-
模板直接映射到硬件指令,无虚函数或运行时多态,保证接近手写汇编的性能。
-
-
可组合构件(GEMM、TensorOp、Epilogue)
-
像搭乐高一样组合 GEMM 核心、张量操作(Tensor Operation) 与 后处理(Epilogue),灵活支持 Conv、BatchMatMul、Attention 等高级算子。
-
二、catlass 的架构与核心模块
catlass 的架构可以概括为 “模板参数驱动的层级执行管线”,主要分为三层:
(一)运算描述层(Operation Description)
通过模板参数声明运算的 数学语义 与 数据属性:
-
数据类型:
half_t、float_t、int8_t等 -
布局:
RowMajor、ColMajor、TensorNC等 -
运算类别:
gemm、batched_gemm、tensor_op_gemm -
Epilogue 功能:bias + activation(ReLU、GELU 等)
(二)分块与调度层(Tiling & Scheduling)
决定如何在硬件上划分任务与存储:
-
Threadblock Tile:每个 AI Core 或计算单元处理的子矩阵块大小
-
Warp Tile:warp(线程束)内部进一步细分的计算粒度
-
Instruction Shape:一次向量指令处理的元素个数(如 128-bit vector 处理 8×FP16)
-
共享内存与寄存器分配策略
(三)执行构件层(Kernel Components)
由若干可复用的构件组成:
-
GEMM Mainloop:核心矩阵乘法计算循环
-
Tensor Op Transform:对输入做 layout 变换以适配硬件向量指令
-
Epilogue:融合偏置加、激活函数、量化反量化等
-
Load/Store Streams:优化全局内存到共享内存的数据搬运
三、代码示例:用 catlass 写一个 FP16 GEMM Kernel
下面展示一个基于 catlass 的简化 FP16 GEMM 示例(仅示意,真实项目需链接 CANN 的 device runtime):
#include "catlass/gemm/device/gemm.h"
#include "catlass/epilogue/thread/bias_relu.h"
// 定义 GEMM 运算描述:A(MxK) * B(KxN) -> C(MxN),FP16,RowMajor
using Gemm = catlass::gemm::device::Gemm<
half_t, // Element type
catlass::layout::RowMajor, // Layout A
half_t,
catlass::layout::RowMajor, // Layout B
half_t,
catlass::layout::RowMajor, // Layout C
float, // Accumulator type (FP32 累加提高精度)
catlass::arch::Sm80 // 对应 CANN AI Core 架构代号(示例)
>;
// 定义 Epilogue:C = activation(A*B + bias)
using Epilogue = catlass::epilogue::thread::BiasReLU<
half_t,
catlass::layout::RowMajor,
float, // accumulator
half_t, // bias type
half_t // output type
>;
// 实例化 Kernel
using GemmWithEpilogue = catlass::gemm::device::GemmWithEpilogue<
Gemm, Epilogue
>;
// 调用示例
void run_gemm(
half_t* A, int M, int K,
half_t* B, int N,
half_t* bias,
half_t* C
) {
using namespace catlass;
// 参数准备
GemmWithEpilogue gemm;
typename Gemm::Arguments args{
{M, N, K}, // Problem size
{A, K}, // ptr_A, stride_A
{B, N}, // ptr_B, stride_B
{bias, N}, // ptr_bias, stride_bias
{C, N}, // ptr_C, stride_C
1 // batch_count
};
// 初始化与执行
auto status = gemm.initialize(args);
if (status == Status::kSuccess) {
gemm.run();
}
}亮点:
-
通过模板参数一次性确定所有硬件与数据特性,无运行时分支;
-
Epilogue 与 GEMM 主体融合,避免中间结果写回全局内存;
-
编译器可针对 tile 大小与指令集做激进优化。
四、catlass 在 CANN 上的优势
|
维度 |
传统手写 kernel |
catlass 模板化 |
|---|---|---|
|
开发效率 |
低(需针对每个 shape 手写) |
高(改模板参数即可) |
|
性能 |
依赖个人经验,难达理论峰值 |
接近硬件峰值(自动调度最优 tile) |
|
可维护性 |
难复用,改动风险高 |
模块化构件,易组合扩展 |
|
硬件适配 |
移植成本高 |
模板参数切换即可适配不同 AI Core 版本 |
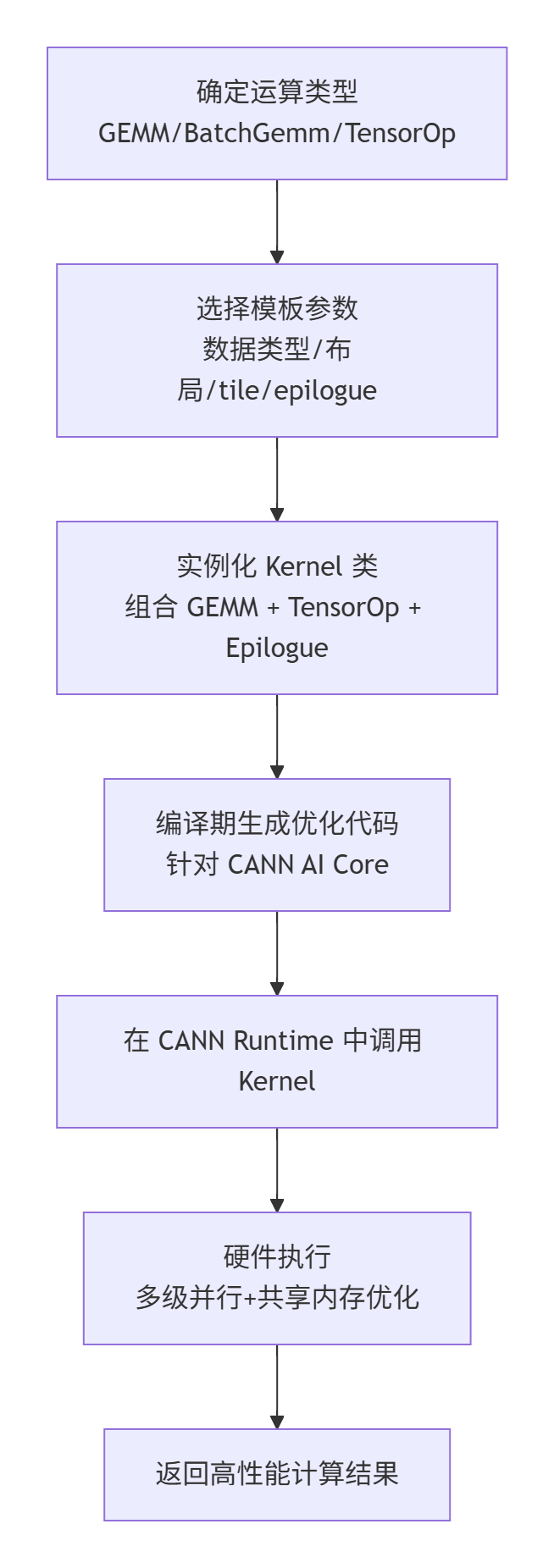
五、catlass 使用流程图
catlass 的开发与应用流程如下:
六、适用场景与最佳实践
-
自研算子开发
当现有 ops-math 无法满足特殊计算模式(如混合精度注意力机制、稀疏矩阵乘)时,可用 catlass 快速搭建高性能 kernel。
-
极致性能调优
在已知输入 shape 分布的情况下,通过调节 tile 参数与 epilogue 融合策略榨干硬件算力。
-
与 GE 配合
GE 在做图优化时可调用 catlass 生成的 kernel 替代通用算子,实现“图级+算子级”双重加速。
建议:
-
先使用 catlass 提供的 profiler 工具评估不同 tile 配置的 occupancy 与带宽利用率;
-
对于变 shape 场景,可保留几套模板参数做运行时选择(multi-kernel dispatch)。
七、总结与展望
catlass 是 CANN 面向底层开发者的“性能神器”,它以 模板化 + 构件化 的方式,把硬件特性转化为可编程的优化空间,让开发者既能保持高效开发,又能逼近硬件的理论峰值性能。与 ops-math 的易用性、hixl 的跨语言协作、GE 的图优化形成互补,catlass 在 CANN 生态中承担了 “算子性能天花板” 的角色。
未来,随着 CANN 对更低位宽(如 INT4)与新数据类型(如 BF16、TF32)的支持,catlass 将进一步扩展模板参数与构件库,让 AI Core 的每一分算力都被精准调度。对于追求极致性能的团队,catlass 值得成为标配工具。
最后,附上相关链接供深入学习与实操:
1. CANN组织链接:https://atomgit.com/cann
2. 仓库链接:https://atomgit.com/cann/catlass

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 3
3 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)