破译 GE 库:CANN 图编译引擎的“大脑”与“交通枢纽”
GE 库是 CANN 生态中“模型翻译”与“性能优化”的核心枢纽,它通过静态图优化与动态执行调度的结合,让深度学习模型在 CANN 硬件上实现了“既快又稳”的执行。只需关注模型本身的算法逻辑,无需成为“硬件优化专家”,就能让模型在 CANN 上发挥极致性能。未来,随着大模型(如千亿参数 LLM)与稀疏计算、量化技术的普及,GE 库将进一步强化对动态图、稀疏算子融合、低精度计算的支持,成为 AI 计
破译 GE 库:CANN 图编译引擎的“大脑”与“交通枢纽”
在深度学习模型的落地过程中,“从算法到硬件的高效执行”始终是最大的挑战之一。即使有了优化的算子和跨语言交互能力,若无法将分散的模型组件(算子、数据、控制流)组织成硬件“能懂且跑得快”的形式,性能依然会大打折扣。华为 CANN 生态中的 GE 库(Graph Engine,图编译引擎)正是解决这一问题的核心枢纽——它像一位“模型翻译官”兼“交通指挥官”,将前端框架的模型转化为硬件友好的执行计划,并调度数据与计算在 CANN 硬件上高效流动。今天,我们就深入 GE 库的内部,揭开它的神秘面纱。
一、GE 库是什么?为什么需要它?
GE(Graph Engine)是 CANN 中负责模型图编译与执行调度的核心库,全称“图编译引擎”。它的核心使命是:将来自 TensorFlow、PyTorch 等框架的模型(以计算图形式表达)转化为 CANN 硬件可高效执行的“优化执行图”,并完成运行时的动态调度。
简单来说,深度学习模型在前端框架中是“算法逻辑图”(如 TensorFlow 的 tf.Graph、PyTorch 的 torch.fx.Graph),但这些图往往存在冗余节点、低效内存访问或不匹配硬件特性的结构。GE 库的作用就是“改造”这张图:
-
消除冗余:合并连续的可融合算子(如 Conv+BN+ReLU 融合为一个复合算子),减少计算与内存开销;
-
适配硬件:根据 CANN 硬件(如 NPU)的算力特性(如向量计算单元、内存带宽)调整图的执行顺序与数据布局;
-
动态调度:在运行时根据实际输入数据(如 batch size、图像分辨率)动态调整图的执行策略,最大化硬件利用率。
没有 GE 库,模型只能“原样”在硬件上执行,性能可能仅为优化后的 30%~50%。GE 仓库地址:https://atomgit.com/cann/ge
二、GE 库的核心架构:“三阶段”编译与“双模式”调度
GE 库的设计围绕“静态优化+动态调度”展开,整体架构可分为三大模块(如图 1 所示),覆盖从模型输入到硬件执行的全流程。
(一)图预处理模块(Graph Preprocessing)
目标:将前端框架的模型图转换为 GE 内部统一的“中间表示(IR)”——GE Graph,并修复图中的“不规范”结构。
前端框架的模型图可能存在以下问题:
-
控制流冗余:如不必要的条件分支(
if-else)或循环(while),GE 会将其简化为硬件友好的顺序执行或向量化分支; -
节点碎片化:多个小算子(如逐元素加减)可能被合并为一个复合算子(如
ElemWiseAddSub); -
数据类型不匹配:前端可能使用
float64,但 CANN 硬件更擅长float16/int8,GE 会自动插入类型转换节点(并尽可能融合到相邻算子中)。
关键技术:
-
图遍历与模式匹配:通过预设的规则库(如“Conv+BN+ReLU”模式)识别可优化的子图;
-
常量折叠:提前计算图中可确定的常量表达式(如
x=2+3直接替换为x=5),减少运行时计算。
(二)图优化模块(Graph Optimization)
目标:对 GE Graph进行深度优化,生成“硬件感知”的执行计划。这是 GE 库最能体现技术深度的环节,核心优化手段包括:
1. 算子融合(Operator Fusion)
将多个连续的小算子合并为一个大算子,减少内存读写次数。例如:
-
计算融合:Conv(卷积)+ BN(批归一化)+ ReLU(激活)融合为一个
ConvBNRelu算子,避免中间特征图多次读写内存; -
控制融合:将条件判断(
if condition)与后续计算融合,根据condition的值动态选择执行路径,减少分支跳转开销。
2. 内存优化(Memory Optimization)
-
生命周期分析:追踪每个张量(Tensor)在图中的“存活时间”,复用不再使用的内存空间(“内存复用”),降低峰值内存占用;
-
数据布局转换:根据硬件的内存访问模式(如 NPU 偏好连续的通道优先布局),将张量从
NHWC( batch, height, width, channel)转换为NCHW( batch, channel, height, width),提升缓存命中率。
3. 并行度优化(Parallelism Optimization)
分析图中可并行执行的子图(如独立的分支),通过“任务拆分”让 CANN 硬件的多计算单元(如多个 AI Core)同时工作,提升吞吐量。
(三)图执行模块(Graph Execution)
目标:将优化后的 GE Graph转换为硬件可执行的指令序列,并在运行时动态调度。
GE 支持两种执行模式:
-
静态执行(Static Execution):优化后的图结构固定,运行时直接按预生成的指令序列执行(适合输入尺寸固定的场景,如固定分辨率的分类模型);
-
动态执行(Dynamic Execution):允许图的部分结构(如分支路径、算子参数)根据输入动态调整(适合输入尺寸变化的场景,如目标检测模型的不同分辨率输入)。
关键技术:
-
内核调度器:根据硬件实时负载(如 AI Core 空闲率)动态分配算子到不同计算单元;
-
数据搬运引擎:管理主机内存与 CANN 设备内存(如 NPU 的 Global Memory)间的数据传输,通过“异步搬运+计算重叠”隐藏传输延迟。
三、GE 库的典型工作流程与代码示例
以 TensorFlow 模型转换为 CANN 可执行模型为例,GE 库的工作流程可分为以下步骤(结合代码示例说明):
步骤 1:导入模型并生成初始图
前端框架(如 TensorFlow)的模型被导入后,首先转换为 GE 的中间表示 GE Graph。
import tensorflow as tf
from ge import GraphBuilder
# 加载 TensorFlow 模型
tf_model = tf.keras.models.load_model("resnet50_tf.h5")
# 使用 GE 的 GraphBuilder 转换为 GE Graph
graph_builder = GraphBuilder()
ge_graph = graph_builder.build_from_tf(tf_model) # 输出:GE Graph 对象步骤 2:图优化(以算子融合为例)
GE 自动识别 Conv+BN+ReLU模式并融合,可通过日志查看优化过程:
from ge import Optimizer
# 配置优化策略(启用算子融合、内存复用)
optimizer = Optimizer(
enable_fusion=True, # 开启算子融合
memory_reuse_threshold=0.5 # 内存复用阈值(50% 以上复用率才触发)
)
# 执行优化,生成优化后的图
optimized_ge_graph = optimizer.optimize(ge_graph)
# 打印优化前后的算子数量(示例输出)
print(f"优化前算子数:{len(ge_graph.nodes)}") # 假设输出:120
print(f"优化后算子数:{len(optimized_ge_graph.nodes)}") # 假设输出:85(融合减少了 35 个算子)步骤 3:生成可执行模型并运行
优化后的 GE Graph被编译为 CANN 硬件支持的 OM模型(Offline Model),可直接在 CANN 运行时执行:
from ge import ModelExporter
from cann_runtime import Runtime
# 导出为 OM 模型
exporter = ModelExporter()
exporter.export(optimized_ge_graph, "resnet50_optimized.om")
# 使用 CANN 运行时加载并执行
runtime = Runtime()
model = runtime.load_model("resnet50_optimized.om")
# 准备输入数据(假设输入为 224x224 RGB 图像)
input_data = ... # 预处理后的 numpy 数组
model.set_input(0, input_data)
# 执行推理
model.run()
# 获取输出
output = model.get_output(0)
print("推理完成,输出 shape:", output.shape)四、GE 库的使用流程图
GE 库的核心流程可总结为“前端图→GE 中间图→优化→可执行模型→硬件执行”,具体流程如图 2 所示:
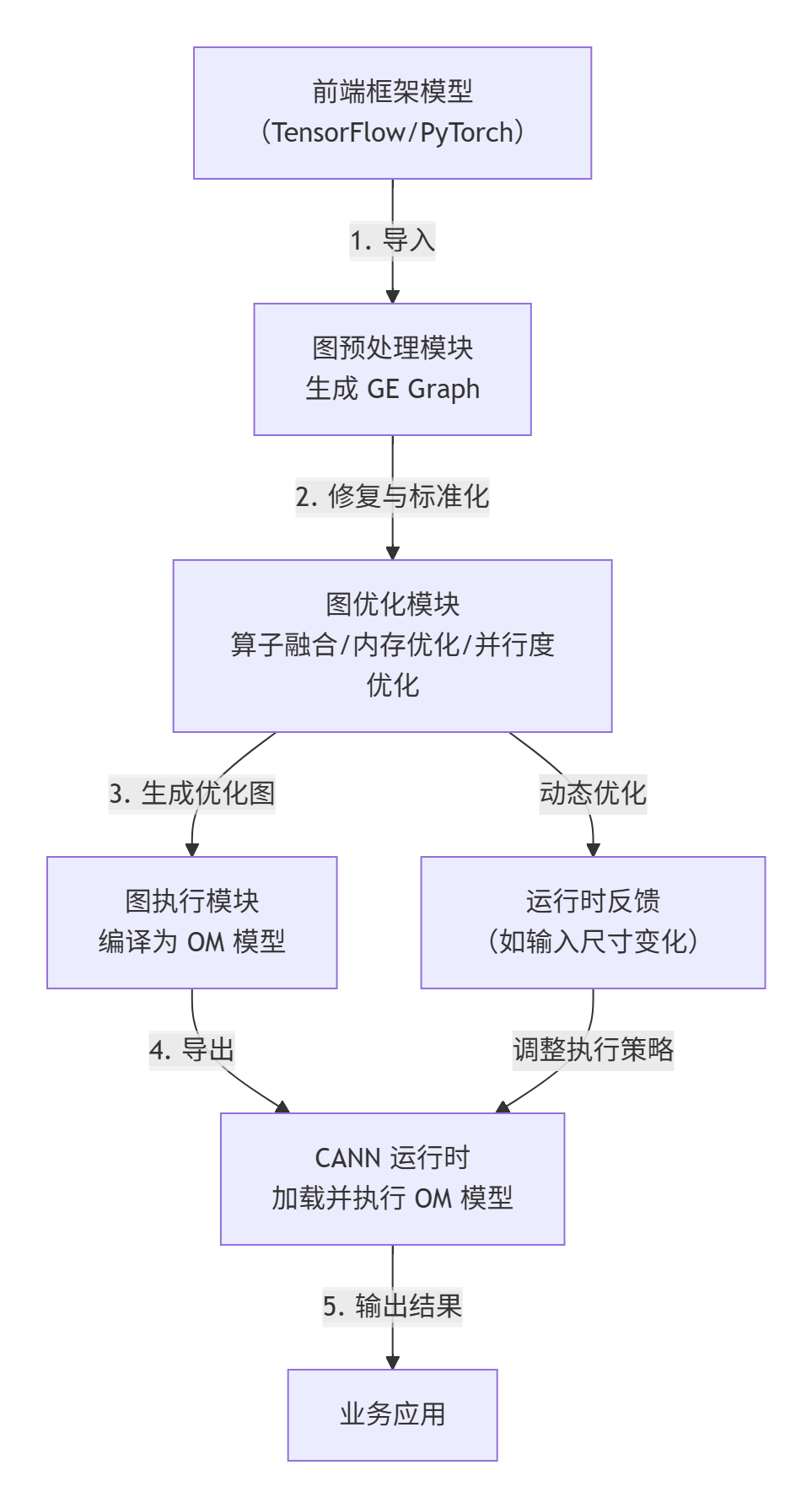
五、GE 库的价值:为何它是 CANN 的“性能倍增器”?
GE 库的能力直接决定了模型在 CANN 硬件上的最终性能,其核心价值体现在:
1. 性能提升显著
通过算子融合与内存优化,典型模型(如 ResNet50)的推理时延可降低 40%~60%,内存占用减少 30%~50%;动态执行模式则让变输入尺寸模型的性能波动从 ±50% 缩小到 ±10% 以内。
2. 兼容性与灵活性
支持 TensorFlow、PyTorch、ONNX 等主流框架,且通过插件化设计可快速扩展对新算子的支持(如自定义激活函数)。
3. 开发透明性
开发者无需手动修改模型结构,GE 库自动完成优化,大幅降低“为硬件调优”的开发成本。
六、总结与展望
GE 库是 CANN 生态中“模型翻译”与“性能优化”的核心枢纽,它通过静态图优化与动态执行调度的结合,让深度学习模型在 CANN 硬件上实现了“既快又稳”的执行。对于开发者而言,GE 库的存在意味着:只需关注模型本身的算法逻辑,无需成为“硬件优化专家”,就能让模型在 CANN 上发挥极致性能。
未来,随着大模型(如千亿参数 LLM)与稀疏计算、量化技术的普及,GE 库将进一步强化对动态图、稀疏算子融合、低精度计算的支持,成为 AI 计算中“模型到硬件”的关键桥梁。理解并善用 GE 库,将是释放 CANN 硬件潜力的关键一步。
最后,附上相关链接供深入学习与实操:
1. CANN组织链接:https://atomgit.com/cann
2. 仓库链接:https://atomgit.com/cann/ge

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 3
3 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)