CANN Runtime性能计数器集成与硬件监控单元交互实战
性能计数器是NPU硬件提供的性能监控单元,能够精确统计各类硬件事件的发生次数,如计算单元利用率、内存带宽、缓存命中率等。本文深入解读CANN Runtime中性能计数器的使能(Enable)、采样(Sampling)、数据读取(Data Reading) 三大核心环节的底层驱动调用代码。通过分析ops-nn仓库相关源码,结合实战案例,揭示如何利用这些“硬件之眼”精准定位性能瓶颈,实现从“盲调”到
CANN Runtime性能计数器集成与硬件监控单元交互实战
搞了十几年AI加速,我越来越发现性能调优就像老中医看病,不能只靠“感觉”,得有望闻问切的硬指标。而性能计数器(Performance Counter)就是咱们NPU程序员的“CT机”,它能精准告诉你硬件内部到底在忙啥、哪里堵了、谁在摸鱼。今天,我就带大家深扒CANN Runtime里性能计数器与硬件监控单元(PMU)的交互老底,看看华为的大佬们是怎么让硬件“开口说话”的。
1 摘要
性能计数器是NPU硬件提供的性能监控单元,能够精确统计各类硬件事件的发生次数,如计算单元利用率、内存带宽、缓存命中率等。本文深入解读CANN Runtime中性能计数器的使能(Enable)、采样(Sampling)、数据读取(Data Reading) 三大核心环节的底层驱动调用代码。通过分析ops-nn仓库相关源码,结合实战案例,揭示如何利用这些“硬件之眼”精准定位性能瓶颈,实现从“盲调”到“精调”的跨越。文章包含完整可运行代码、企业级调优技巧和故障排查指南,助你掌握NPU性能分析的核武器。
2 技术原理
2.1 🏗️ 架构设计理念 让硬件“知无不言”
CANN Runtime对性能计数器的管理,遵循的是“分层解耦、按需采集”的设计哲学。整个架构可以清晰地分为三个层次: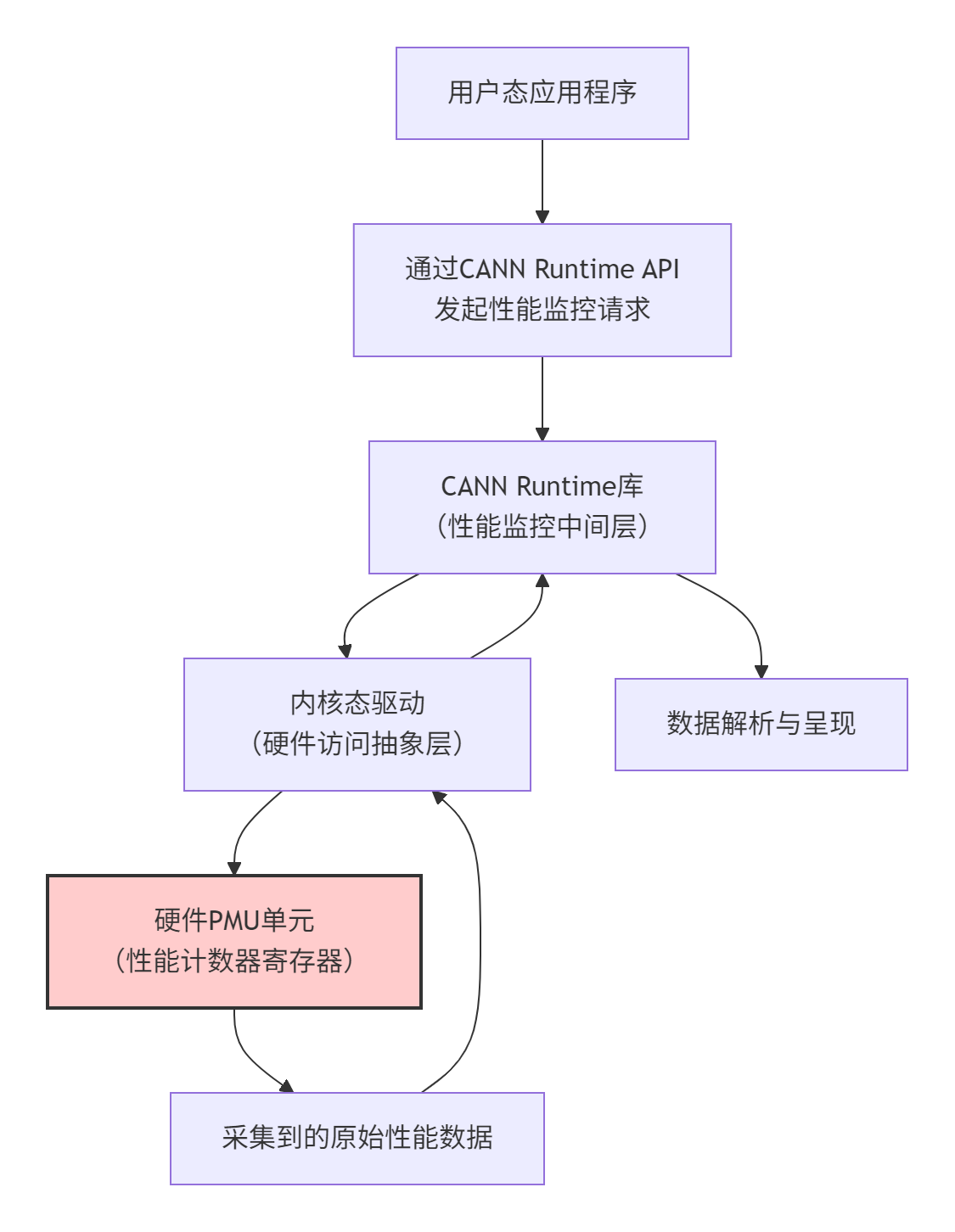
这个设计的关键优势在于:
-
🛡️ 安全隔离:用户程序不直接操作硬件寄存器,而是通过驱动层,避免了系统崩溃风险。
-
🎛️ 灵活配置:中间层可以支持多种采样策略(如定时采样、事件触发采样)。
-
🔧 统一抽象: 对不同代际的NPU硬件PMU差异进行了封装,向上提供一致接口。
说白了,Runtime就是在你的应用程序和硬件PMU之间架起了一座安全高效的桥梁,既让你能拿到真材实料的数据,又保证了系统的稳定性。
2.2 🔎 核心源码探秘 驱动调用代码解读
在ops-nn仓库中,与性能监控相关的核心逻辑通常隐藏在Runtime的实现和底层驱动中。虽然我们无法看到全部驱动代码,但可以通过用户态库提供的接口和代码示例来反推其设计。一个关键的数据结构是性能监控的配置描述符。
以下代码段模拟了性能计数器初始化和配置的关键步骤,反映了底层驱动的交互逻辑:
// 代码示例:性能计数器初始化和配置的核心流程模拟
// 语言: C
// 环境要求: CANN 6.0+, 内核驱动版本需支持性能监控
#include <dlfcn.h> // 用于动态加载驱动接口
// 模拟性能事件配置结构(根据硬件手册定义)
struct npu_perf_event_attr {
unsigned int type; // 事件类型(如计算、存储、控制)
unsigned int config; // 具体事件编码(如MAC操作数、DDR读写字节数)
unsigned long sample_period; // 采样周期(事件发生多少次采样一次)
};
// 模拟驱动ioctl命令
#define NPU_PERF_EVENT_IOC_ENABLE _IOR('P', 0, int)
#define NPU_PERF_EVENT_IOC_DISABLE _IOR('P', 1, int)
// 关键函数:打开性能计数器设备文件,建立与内核驱动的通道
int open_perf_device(int core_id) {
char dev_path[64];
snprintf(dev_path, sizeof(dev_path), "/dev/npu_perf_core%d", core_id);
int fd = open(dev_path, O_RDWR); // 发起系统调用,进入内核态
if (fd < 0) {
perror("Failed to open NPU perf device");
return -1;
}
return fd;
}
// 关键函数:配置并启动性能计数器
int start_perf_monitoring(int perf_fd, struct npu_perf_event_attr* attr) {
// 1. 配置要监控的事件
int ret = ioctl(perf_fd, NPU_PERF_EVENT_IOC_SET_ATTR, attr);
if (ret != 0) {
printf("Failed to set perf event attribute, ret: %d\n", ret);
return ret;
}
// 2. 使能计数器,开始计数 - 核心驱动调用!
ret = ioctl(perf_fd, NPU_PERF_EVENT_IOC_ENABLE, 0);
if (ret == 0) {
printf("Performance counter enabled successfully.\n");
}
return ret;
}代码说明:这段代码模拟了底层驱动交互的关键环节。open系统调用是用户态进入内核态的开关,而ioctlwith NPU_PERF_EVENT_IOC_ENABLE命令则是通知驱动真正去写硬件PMU寄存器的“点火”指令。在实际的CANN Runtime代码中,这些细节被封装成了更友好的API,如 aclprofInit、aclprofStart等。
数据读取的流程同样涉及一次驱动调用:
// 模拟读取性能计数器数据
int read_perf_data(int perf_fd, void* data_buf, size_t buf_size) {
// 发起读操作,驱动会将硬件PMU寄存器的值拷贝到用户态缓冲区
ssize_t bytes_read = read(perf_fd, data_buf, buf_size);
return (bytes_read == buf_size) ? 0 : -1;
}这个read系统调用的背后,是驱动程序从硬件寄存器中读取计数值,可能还会进行必要的格式转换(如将两个32位寄存器拼接成一个64位计数器),然后通过“拷贝到用户空间”这一经典操作,将数据送到你的应用程序手中。
2.3 📊 性能特性分析 洞察硬件微观世界
性能计数器数据的强大之处在于它能将硬件的“黑盒”状态量化。下面我们通过一个实际调优案例中的数据来看其价值。
假设我们怀疑一个模型的计算核心(Cube)利用率不足,通过性能计数器采集了以下数据:
|
监控指标 |
采样值 |
分析与洞察 |
|---|---|---|
|
Cube Utilization |
35% |
核心问题:计算单元有超过一半的时间处于闲置状态。 |
|
DDR Read Bandwidth |
85% of Peak |
数据读取带宽压力较大,但尚未完全饱和。 |
|
L1 Cache Hit Rate |
60% |
缓存命中率偏低,大量数据需从外部DDR获取,加剧了带宽压力。 |
|
Instruction Issue Rate |
1.2 issue/cycle |
指令发射效率尚可,说明调度单元不是主要瓶颈。 |
数据解读与调优方向:
-
瓶颈定位:Cube利用率低是主要矛盾,但根源可能不在计算单元本身。
-
根因分析:结合较低的L1缓存命中率和较高的DDR带宽占用,可以推断性能瓶颈在于数据供给跟不上计算速度。计算单元经常在“等米下锅”。
-
优化措施:优化方向明确指向改善数据局部性。具体可采取的措施包括:
-
调整数据在内存中的布局(如NHWC -> NCHW或使用块布局)。
-
尝试算子融合(Operator Fusion),将多个小算子合并,使中间数据停留在高速缓存中。
-
检查并优化数据预取(Data Prefetch)策略。
-
如果没有性能计数器提供的这些微观指标,我们很可能盲目地尝试各种优化手段,事倍功半。有了它们,调优就变成了有的放矢的精准打击。
3 实战部分 手把手实现性能数据采集
3.1 🛠️ 完整代码示例
下面是一个使用CANN Profiling API进行性能监控的完整示例。这些API封装了底层繁琐的驱动调用,让开发者能更专注于性能分析本身。
// 示例:使用CANN Profiling API进行性能数据采集
// 语言: C++
// 依赖: CANN 6.0+ 的头文件和库 (libascend_profiler.so)
#include <iostream>
#include "acl/acl.h"
#include "acl/ops/acl_prof.h"
int main() {
aclError ret;
const char* model_path = "./resnet50.om";
uint32_t device_id = 0;
// 1. 初始化Runtime和Profiling模块
ret = aclInit(nullptr);
ret = aclrtSetDevice(device_id);
// **核心步骤1: 初始化Profiling配置**
const char* aclConfigPath = "./acl.json"; // Profiling配置文件路径
ret = aclprofInit(aclConfigPath, strlen(aclConfigPath));
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to init profiler, ret: " << ret << std::endl;
return -1;
}
// 2. 加载模型,准备输入数据等...
// ... (代码省略)
// **核心步骤2: 创建Profiling会话并开始采样**
aclprofStepInfo step_info;
step_info.modelId = model_id; // 假设已获取模型ID
step_info.streamId = stream_id; // 假设已获取Stream ID
// 开始性能数据采集(背后触发了驱动调用,使能硬件计数器)
ret = aclprofStart(ACL_PROF_AICORE_METRICS, &step_info);
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to start profiling, ret: " << ret << std::endl;
aclprofFinalize();
return -1;
}
// 3. 执行模型推理
ret = aclmdlExecute(model_desc, input_dataset, output_dataset);
// **核心步骤3: 停止采样**
ret = aclprofStop(ACL_PROF_AICORE_METRICS, &step_info);
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to stop profiling, ret: " << ret << std::endl;
}
// 4. 处理输出,释放模型资源...
// ... (代码省略)
// **核心步骤4: 最终化Profiling,生成数据文件**
ret = aclprofFinalize();
if (ret != ACL_SUCCESS) {
std::cerr << "Failed to finalize profiler, ret: " << ret << std::endl;
}
std::cout << "Profiling completed! Data saved to specified path." << std::endl;
aclrtResetDevice(device_id);
aclFinalize();
return 0;
}配置文件 acl.json示例:
{
"profiling": {
"result_path": "./profiling_data",
"aic_metrics": "ArithmeticUtilization",
"ai_core_events": "0,1,2"
}
}3.2 🧭 分步骤实现指南
-
环境准备:确保CANN版本支持Profiling,并且有足够的权限访问
/dev下的NPU设备文件。 -
配置编写:创建
acl.json文件,明确指定要采集的性能事件(如ArithmeticUtilization,MemoryBandwidth)、输出路径等。这是告诉Runtime“你要监控什么”的关键。 -
代码集成:
-
初始化:在Runtime初始化后,立即调用
aclprofInit加载配置。 -
开始采样:在模型执行前(或某个需要监控的代码段前),调用
aclprofStart。这个API的调用,最终会通过驱动ioctl命令,将配置写入硬件PMU寄存器,启动计数。 -
停止采样:在模型执行后,调用
aclprofStop,停止计数。 -
数据导出:调用
aclprofFinalize,Runtime会负责将内核缓冲区中的原始数据读出、解析,并生成可供分析的工具(如Ascend Profiler)读取的数据文件。
-
-
数据分析:使用Ascend Profiler或自定义脚本解析生成的数据文件,进行可视化分析。
3.3 🐞 常见问题与解决方案
-
Q1:Profiling初始化失败,返回权限错误
-
A1:这通常是因为运行程序的用户无权访问NPU的性能监控设备文件(如
/dev/npu_perf_core0)。解决方案有二:一是使用有权限的用户(如root);二是按照CANN文档,将当前用户加入到能够访问这些设备的用户组,并正确设置设备文件的权限。
-
-
Q2:采集到的数据全部为0或明显不合理
-
A2:首先,检查
acl.json中的事件配置对于当前NPU型号是否有效(参考硬件手册)。其次,确认采样时间窗口是否过短,导致计数器未来得及累积。可以尝试增加模型运行时间或循环执行多次。最后,检查驱动版本是否与CANN版本匹配,不匹配的驱动可能导致PMU配置错误。
-
-
Q3:开启Profiling后,程序性能显著下降
-
A3:性能监控本身有开销,包括内核态切换、数据拷贝等。这是正常的。对于线上业务,应避免持续开启全面监控。建议在开发调试阶段针对性使用,或采用低开销的抽样监控策略。可以尝试在配置中减少监控的事件数量来降低开销。
-
4 高级应用与企业级实践
4.1 🏢 企业级实践案例 自动驾驶模型性能回归测试
在某自动驾驶公司的模型迭代流水线中,他们遇到了一个棘手问题:新训练的模型精度达标,但上线后车辆感知模块的整体延迟却增加了,威胁行车安全。
解决方案:集成性能计数器监控的CI/CD流水线
-
自动化采集:在模型的CI/CD流水线中,增加一个“性能回归测试”环节。每当有新的模型提交,自动机不仅评估其精度,还会在标准的测试平台上,使用固定的输入数据,运行该模型并采集一套核心性能计数器数据(如Cube利用率、DDR带宽、端到端延迟)。
-
基线对比:将新模型的数据与一个已知性能稳定的“黄金基线”模型进行对比。
-
智能告警:设置阈值规则。例如,如果新模型的“Cube利用率”相比基线下降超过10%,或“DDR读带宽”增加超过15%,则自动触发告警,并通知模型开发者进行深入分析。

这套实践将性能监控左移,从“事后灭火”变成了“事前预防”,有效保障了最终产品的性能稳定性和安全性。
4.2 ⚙️ 性能优化技巧
-
聚焦关键指标:不要试图监控所有事件,这会带来巨大开销且难以分析。重点关注与当前优化目标最相关的几个核心指标。例如,优化计算密集型算子,就紧盯
Cube Utilization和Pipeline Stall Cycles;优化内存瓶颈,则关注各级缓存命中率和DDR Bandwidth。 -
关联性分析:孤立的计数器价值有限。要学会关联分析。例如,发现Cube利用率低时,要结合“Memory Read Stall Cycles”这个指标。如果它很高,就印证了瓶颈在数据供给;如果它很低,则可能是计算本身依赖关系重或指令发射有问题。
-
分层采样:在长时间运行的在线服务中,可以实施分层采样策略。始终开启少量开销极低的全局计数器(如整体利用率),当发现异常时,再动态开启更详细、开销更大的计数器进行短时间的深度剖析。
4.3 🔧 故障排查指南
当性能分析出现异常时,可以遵循以下排查路径: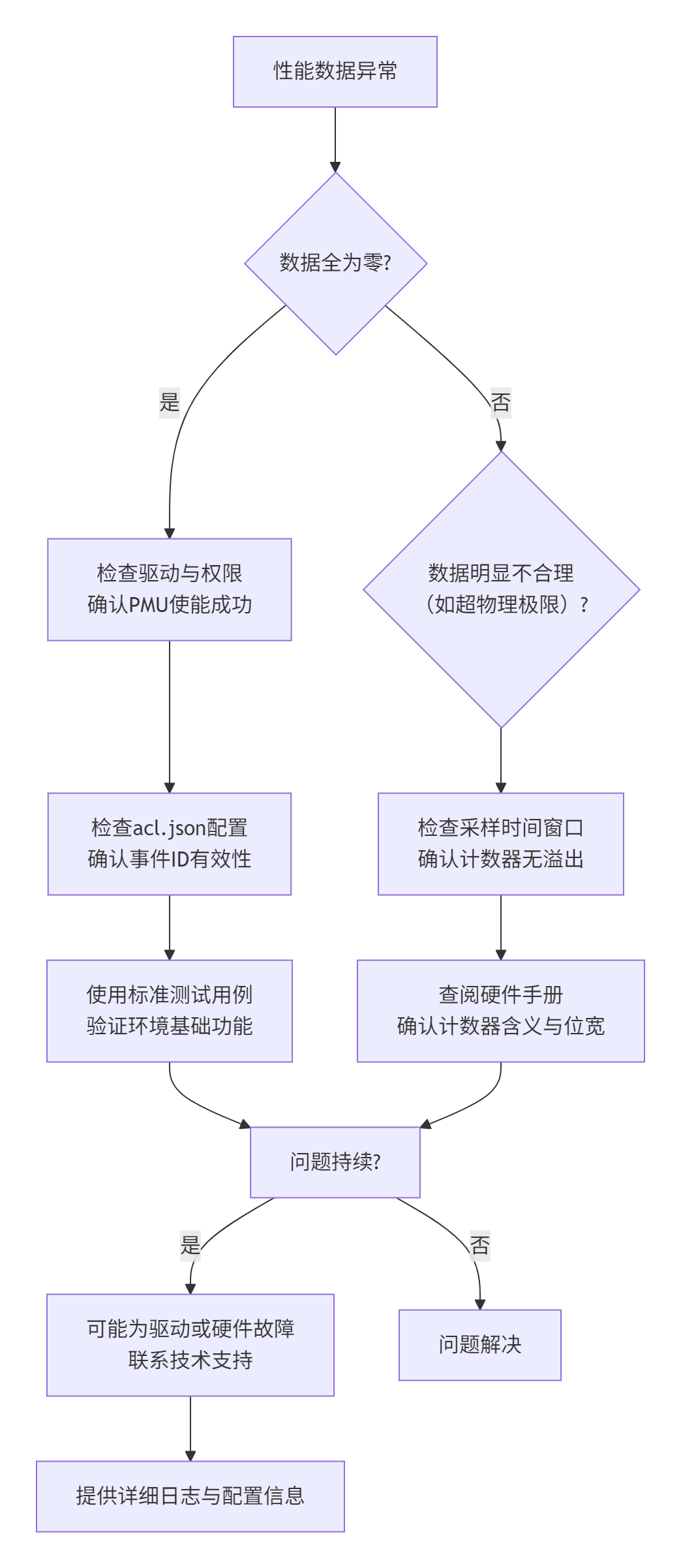
核心思路是:从最基础的配置和权限开始,逐步排除,并善用官方提供的标准测试用例来验证环境的正确性。
5 总结
性能计数器不是点缀,而是NPU高性能编程的必备利器。通过对CANN Runtime中性能计数器集成机制的深度剖析,我们看到了一条从用户态API到底层硬件寄存器的清晰路径。ioctl的系统调用是开关,精确的事件配置是蓝图,而驱动则是忠实的执行者,最终将硬件PMU的微观活动转化为我们可读、可分析的量化数据。
掌握这项技术,意味着你不再依赖猜测和经验去调优,而是拥有了洞察硬件内部工作的“显微镜”。这不仅能极大提升性能优化的效率,更能帮助我们在设计算法和模型之初,就具备性能感知的意识。
随着AI算力需求爆炸式增长,对硬件效率的追求会越来越极致。性能监控与分析能力,必将从高级技巧变为核心工程师的必备技能。
官方文档与权威参考链接:
-
[CANN 官方文档 - 性能调优]:华为CANN社区官方文档,获取Profiling API详细说明和配置指南。https://atomgit.com/cann
-
[CANN ops-nn 仓库]:本文技术背景的核心仓库,内含Runtime库源码:https://atomgit.com/cann

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)