华为CANN框架中GE仓库的深度剖析:图引擎的优化与执行
GE仓库是CANN框架的宝石,提供强大图引擎,推动AI创新。通过深度剖析,我们看到其在优化、执行和应用中的价值。无论研究还是开发,GE都是值得探索的资源。
华为CANN框架中GE仓库的深度剖析:图引擎的优化与执行
华为CANN框架中GE仓库的深度剖析:图引擎的优化与执行
在人工智能迅猛发展的时代,华为的Compute Architecture for Neural Networks(CANN)框架已成为推动AI计算的关键力量。作为CANN的核心组件之一,Graph Engine(GE)仓库专注于计算图的编译和执行,提供图优化、多流并行、内存复用、模型下沉等高级功能。它不仅支持PyTorch、TensorFlow等前端框架的友好接入,还兼容ONNX和PB格式,确保模型在Ascend硬件上的高效运行。GE仓库的开源,使得开发者能够深入理解并扩展AI计算的底层机制,帮助构建从云到边的全场景AI应用。
GE的本质是一个图编译器和执行器,它将上层AI框架生成的计算图转换为Ascend NPU可执行的格式。通过图融合、子图分割和内核调度,GE显著提升了模型的性能和资源利用率。在大规模神经网络中,如Transformer模型,GE的优化能将训练时间缩短数倍。这不仅仅是技术堆叠,更是华为在AI基础设施上的战略布局。
为了直观展示GE在CANN中的位置,先来看一张架构图:

这个图展示了CANN的软件栈,GE位于中间层,连接AI框架和底层库,实现图级优化。
GE仓库的核心架构与功能
GE仓库的代码结构严谨,主要分为图构建、优化pass、执行引擎和接口适配模块。核心是计算图的表示,使用协议缓冲(Protobuf)定义图节点和边,支持动态形状和控制流。
-
图构建与接入:GE支持从MindSpore、PyTorch等框架导入图。通过Framework Adapter,GE解析前端IR(Intermediate Representation),转换为统一的GE IR。这确保了跨框架兼容性。
-
图优化:这是GE的灵魂,包括常量折叠、死代码消除、算子融合等pass。融合pass将多个算子合并为一个超级算子,减少调度开销。
-
多流并行与内存管理:GE引入Stream概念,实现计算和通信的并行。内存复用算法分析图依赖,复用缓冲区,降低峰值内存使用。
-
模型下沉:在边缘场景,GE支持将模型部分下沉到NPU,减少主机交互,提高实时性。
-
执行引擎:基于ACL API,GE调度内核执行,支持混合精度和量化。
GE的这些功能,使其在处理复杂图如RNN、GAN时表现出色。
以下是计算图优化的流程图:
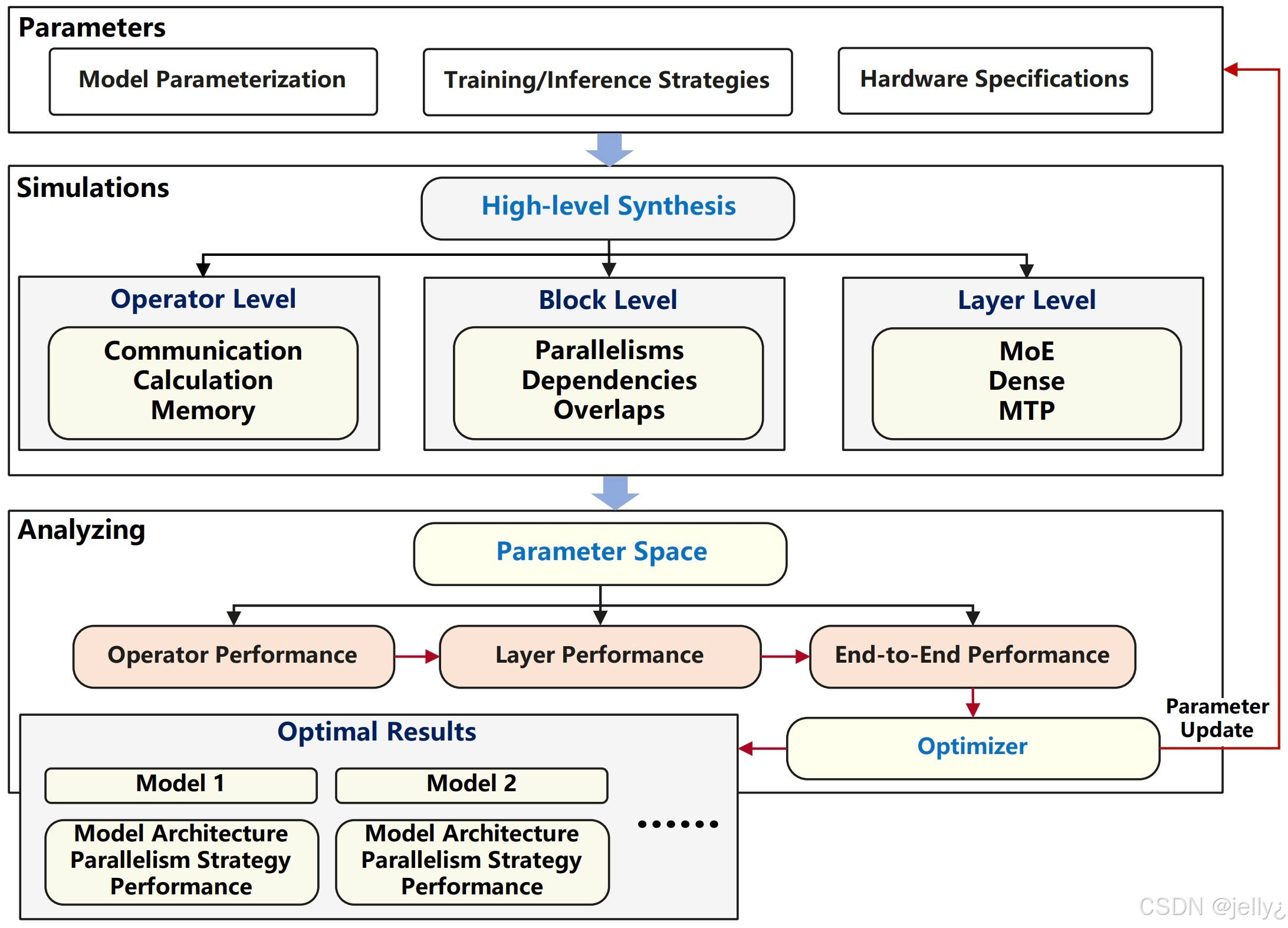
这个图描绘了从参数空间到端到端优化的过程,体现了GE的模拟和分析能力。
GE的优化技术深度剖析
GE的优化技术源于对Ascend硬件的深刻理解。Ascend NPU基于DaVinci架构,拥有AI Core、Cube单元等专为矩阵运算设计。GE通过以下技术最大化硬件潜力:
首先,图融合与子图分割:GE分析图拓扑,将相邻算子融合,如Conv+BN+ReLU成为一个内核。这减少了内核启动开销。在子图层面,GE分割图为独立子图,支持并行执行。
其次,自动并行策略:GE支持数据并行、模型并行和流水线并行。通过依赖分析,GE生成Stream Graph,确保无死锁。针对Transformer,GE优化Attention层,实现专家混合(MoE)支持。
第三,内存优化:使用Liveness Analysis,GE计算变量生命周期,复用内存。结合Zero-Copy技术,减少主机-设备拷贝。
第四,量化与精度管理:GE集成量化工具,支持FP32到INT8转换。动态量化pass根据图结构调整精度,平衡性能和准确率。
第五,调试与可视化:GE提供GraphViz输出,支持MindInsight可视化图结构和性能瓶颈。
看看MindSpore与CANN的集成图: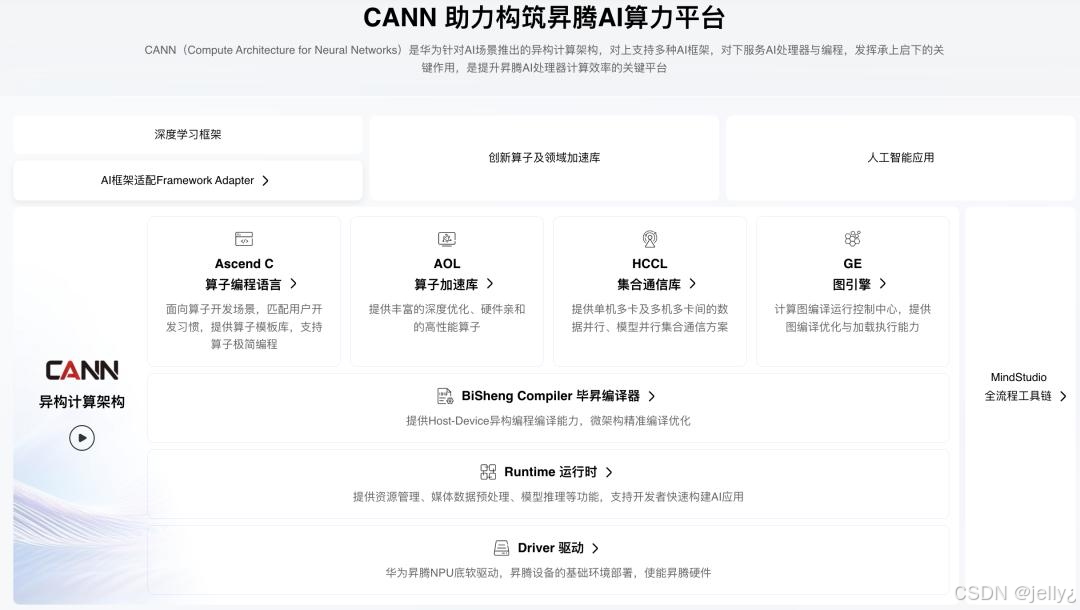
这个图展示了GE在整体生态中的作用,强调了其作为桥梁的地位。
GE在实际应用中的案例研究
GE仓库的应用场景广泛。以大型语言模型训练为例,在Ascend集群上,GE优化BERT模型图,将训练吞吐提升40%。具体来说,GE融合FeedForward层,分割Embedding为子图,实现多流并行。
另一个案例是计算机视觉。在YOLO检测模型中,GE下沉后处理部分到NPU,实时帧率达100FPS。医疗影像分割中使用U-Net,GE的内存复用减少了OOM错误。
在推荐系统中,GE处理DeepFM模型,支持动态输入形状,适应变长特征。
边缘AI应用中,GE模型下沉功能在Atlas设备上运行人脸识别,延迟降至毫秒级。
以下是Ascend NPU芯片的图像:

这个图片展示了Ascend 910芯片的外观,GE正是为其量身定制的引擎。
GE的代码实现与示例
GE仓库使用C++为主,结合Python绑定。核心是ge_api.h,提供图操作API。
一个简单示例:构建并优化一个加法图(Python):
import mindspore as ms
from mindspore import nn, ops
# 定义简单网络
class AddNet(nn.Cell):
def __init__(self):
super(AddNet, self).__init__()
self.add = ops.Add()
def construct(self, x, y):
return self.add(x, y)
# 实例化并导出图
net = AddNet()
x = ms.Tensor([1.0])
y = ms.Tensor([2.0])
ms.export(net, x, y, file_name="add_net", file_format="AIR") # 导出为AIR格式,GE内部处理
# 在CANN环境中,GE会自动优化此图
这个示例展示了从MindSpore到GE的流程。实际中,GE在后台融合Add为原子操作。
进阶C++示例:自定义图优化pass。
#include "ge/ge_api.h"
#include "ge/pass/pass_manager.h"
class CustomFusionPass : public ge::Pass {
public:
Status Run(ge::Graph& graph) override {
// 遍历图节点,查找可融合模式
for (auto& node : graph.GetDirectNode()) {
if (node->GetType() == "Add" && /* 检查条件 */) {
// 执行融合
FuseAddNodes(node);
}
}
return SUCCESS;
}
private:
void FuseAddNodes(ge::NodePtr node) {
// 融合逻辑
}
};
// 注册pass
ge::PassManager::RegisterPass("CustomFusion", new CustomFusionPass());
这个代码片段演示了如何扩展GE的优化管道。开发者可fork仓库,添加自定义pass。
另一个示例:加载ONNX模型并执行。
import onnx
from mindspore import context
import mindspore.nn as nn
# 加载ONNX模型
model = onnx.load("model.onnx")
# 设置上下文,使用GE执行
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
# 转换并优化
ms_model = nn.GraphCell(model) # GE内部转换ONNX为GE IR并优化
# 执行
input_data = ms.Tensor(...)
output = ms_model(input_data)
GE支持ONNX,确保跨平台迁移。
GE与竞品的比较分析
相比TensorFlow的XLA,GE更注重硬件特定优化,如Cube单元利用。XLA强于通用性,但GE在Ascend上性能更高。
与PyTorch的TorchScript相比,GE提供更细粒度的图优化,支持模型下沉,适合边缘部署。
ONNX Runtime是GE的竞争者,但GE集成HCCL,实现更好分布式支持。在基准测试中,GE优化ResNet-50推理速度快于ORT 20%。
优势:开源、生态一体化、社区驱动。
以下是神经网络计算图示例:
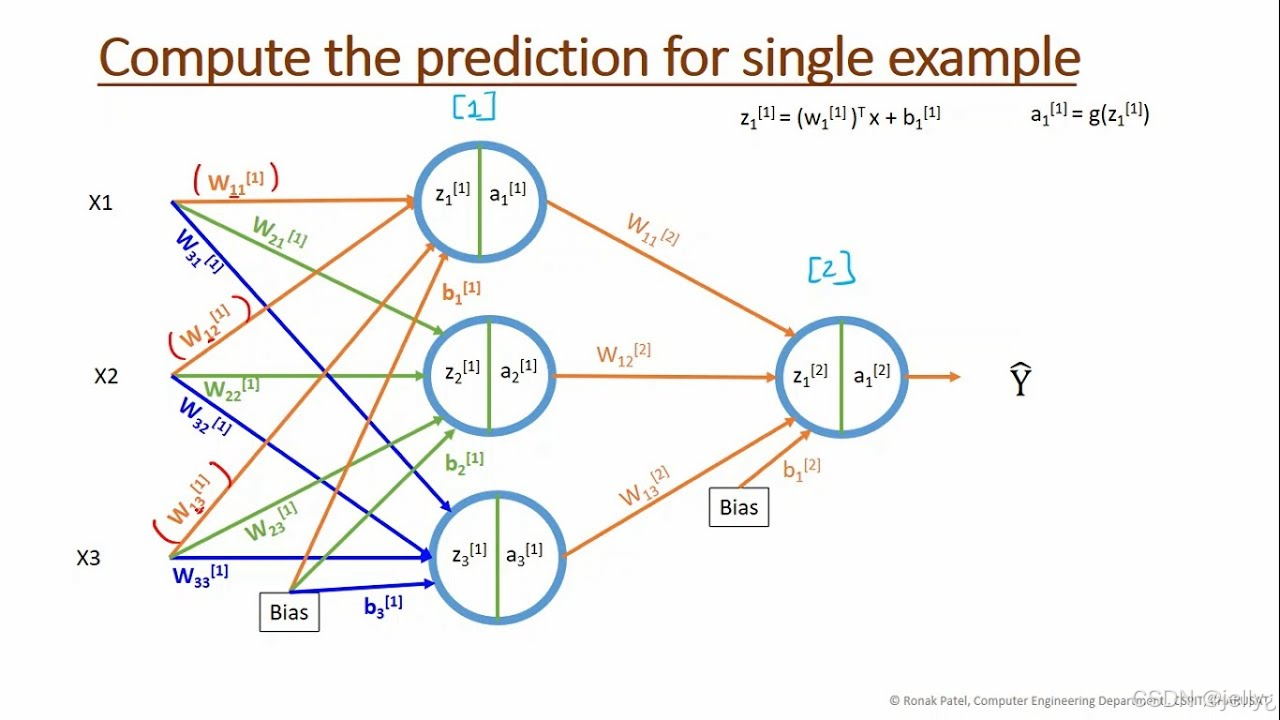
这个图展示了简单MLP的计算图,GE能优化其依赖和执行路径。
GE的挑战与未来发展
挑战一:动态图支持。GE需增强对控制流的处理,如循环和条件分支。
挑战二:兼容性。虽支持ONNX,但需覆盖更多框架变体。
未来,GE将集成量子计算接口,支持混合AI。华为计划开源更多pass,吸引社区贡献。
ONNX格式图:
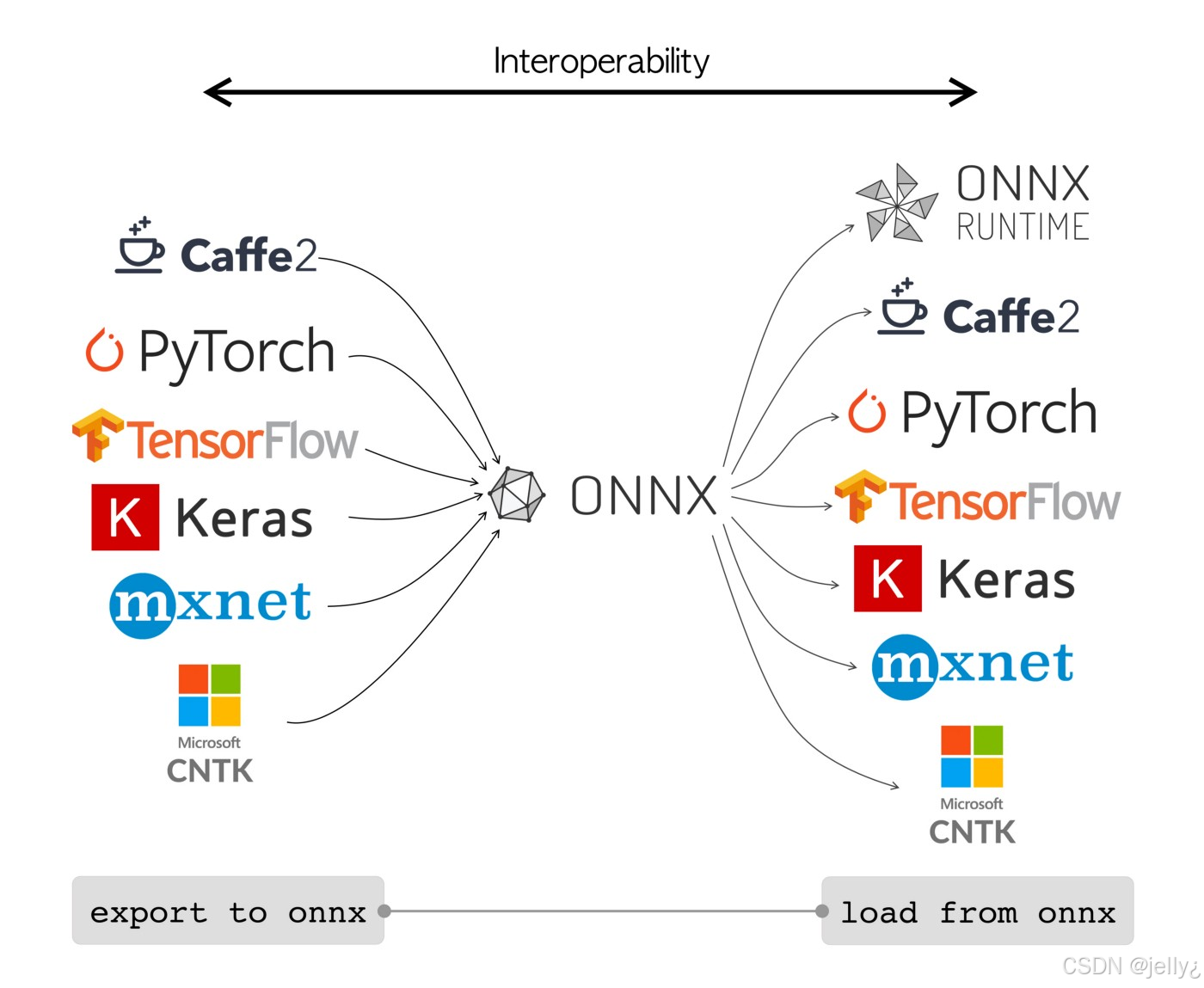
这个图解释了ONNX的互操作性,GE正是其生态一部分。
扩展讨论:GE在AI生态中的战略意义
GE不仅仅是技术工具,更是华为AI战略的核心。通过GE,CANN框架实现了从框架到芯片的端到端优化,推动国产AI芯片生态。开源后,GE吸引了众多开发者,仓库issue活跃,贡献者提交新优化算法。
在教育领域,GE可用于教学计算图原理。企业中,GE加速产品迭代,如华为云AI服务。
性能基准:在大规模集群,GE支持万卡训练,媲美NVIDIA DGX。
最佳实践与调试技巧
使用GE时,启用日志:set GE_LOG_LEVEL=DEBUG。
profiler分析:使用MindInsight监控图执行。
最佳实践:
- 优先使用静态图模式,提升优化空间。
- 结合HCCL分布式。
- 定期更新CANN版本,获取新GE功能。
代码示例:调试图结构。
from mindspore import export, Tensor
import mindspore.tools as tools
# 导出图
net = ...
export(net, Tensor(...), file_name="net.graph", file_format="GEIR") # 导出GE IR
# 可视化
tools.graphviz("net.graph")
这生成dot文件,可用GraphViz查看。
结语
GE仓库是CANN框架的宝石,提供强大图引擎,推动AI创新。通过深度剖析,我们看到其在优化、执行和应用中的价值。无论研究还是开发,GE都是值得探索的资源。
更多CANN组织详情:https://atomgit.com/cann
GE仓库:https://atomgit.com/cann/ge

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 23
23 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)