昇腾atlas 300I duo部署Qwen3-8B完整实战:从选型到成功运行
一、硬件环境准备
1.1 服务器配置
# 系统信息
OS: Ubuntu 20.04 LTS
CPU: Intel Xeon Gold 6530 (128核心)
Memory: 503GB RAM
# NPU信息
设备:昇腾310P3 × 2
Device ID: 5384
显存:88GB(44GB × 2芯片)
驱动版本:24.1.0.1
1.2 驱动安装
使用之前需要先安装固件和驱动
选择合适的版本型号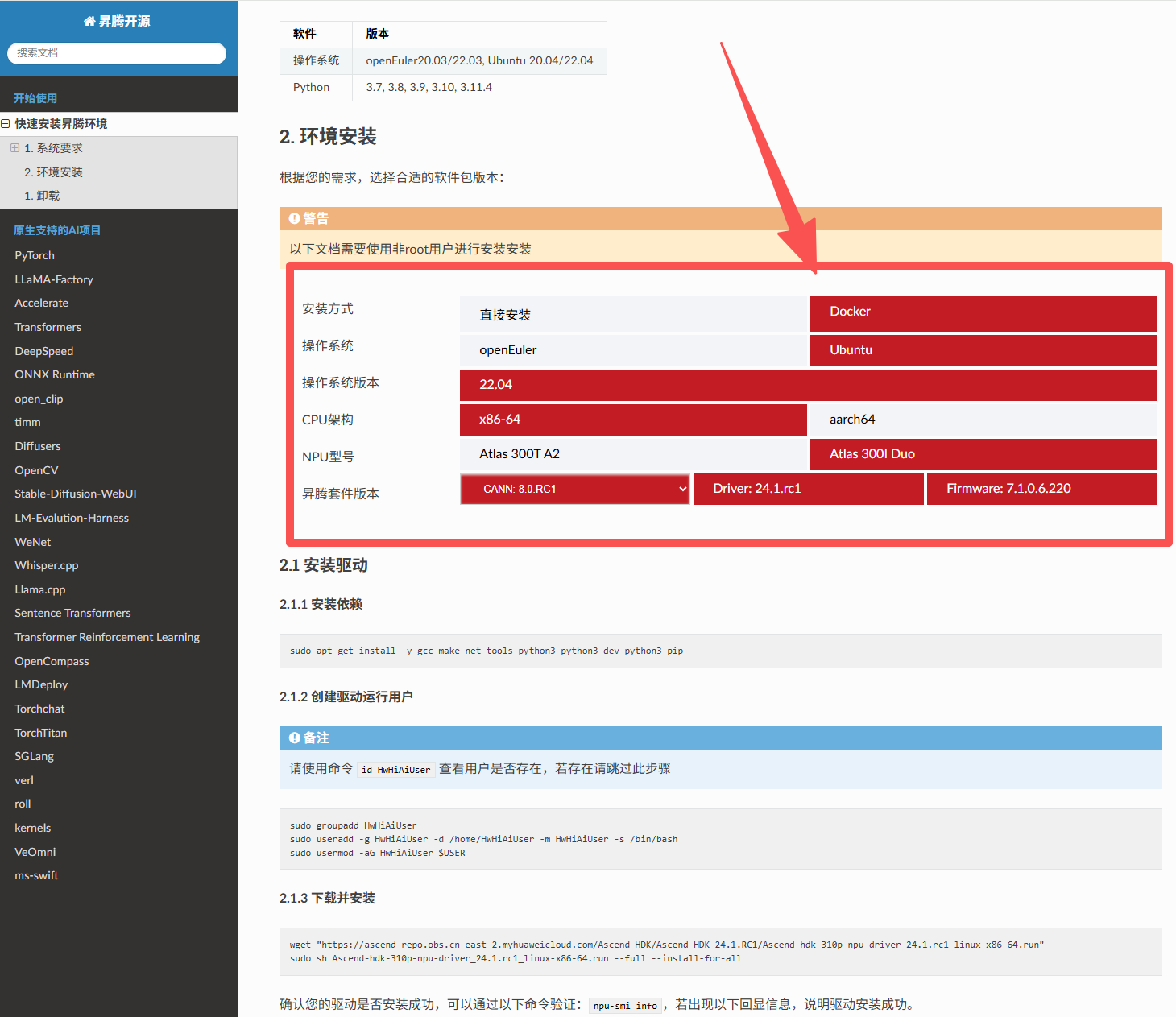
一直跟着执行,在安装驱动时候,上面的创建驱动文件不知道是过时了,一直没成功,换到官网手动下载了驱动。另外在执行命令时是使用sudo bash 而不是sudo sh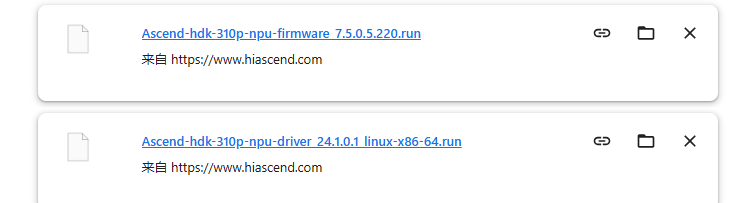
关键步骤:
# 1. 下载驱动(官网手动下载)
# https://www.hiascend.com/hardware/firmware-drivers/community
# 文件:Ascend-hdk-310p-npu-driver_24.1.0.1_linux-x86-64.run
# 2. 安装驱动和固件(注意:用bash而非sh)
sudo bash Ascend-hdk-310p-npu-driver_24.1.0.1_linux-x86-64.run --full --install-for-all
sudo bash Ascend-hdk-310p-npu-firmware_7.5.0.5.220.run --full
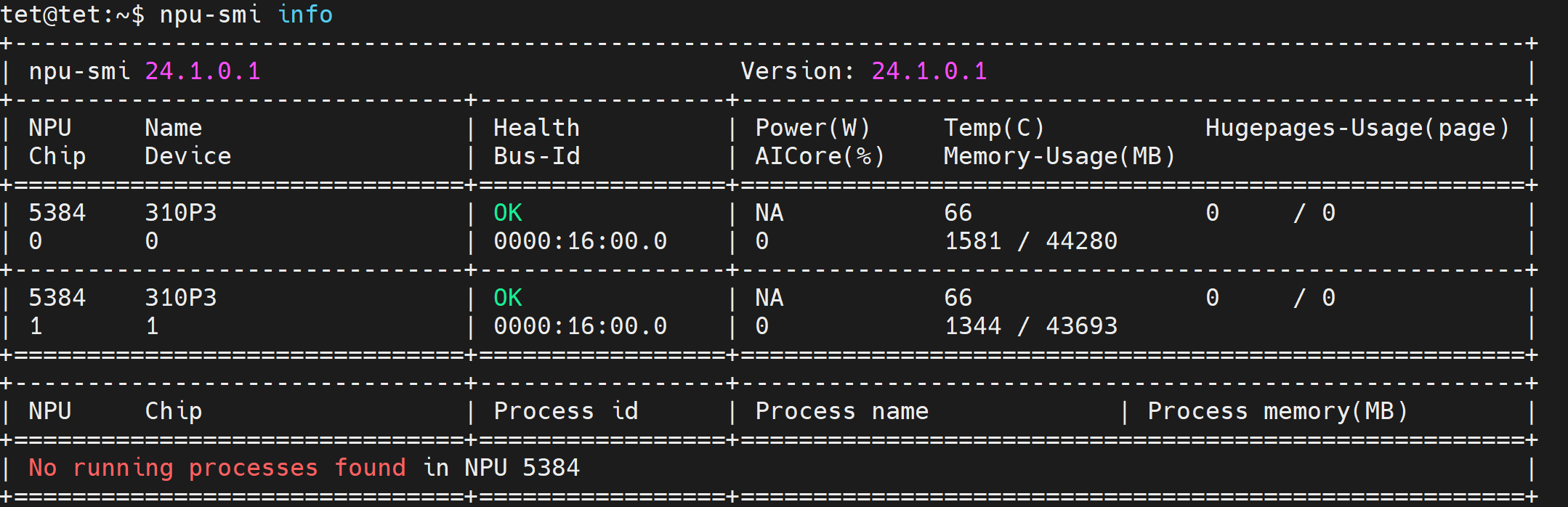
# 3. 验证安装
npu-smi info
二、推理框架选型实战
在开始部署前,我们测试了三种主流框架,以下是详细的对比结果。
2.1 Xinference(❌ 不推荐)
测试结论:
- ❌ 免费版:不支持昇腾NPU加速
- ⚠️ 企业版:需付费 8万元/台机器
- ✅ 优势:平台管理友好,支持模型统一管理
说明:Xinference 企业版底层使用 MindIE/vllm/sglang 引擎,本质是在 MindIE 基础上做了平台优化和稳定性增强。如果预算充足且需要统一管理多种模型,可以考虑企业版。
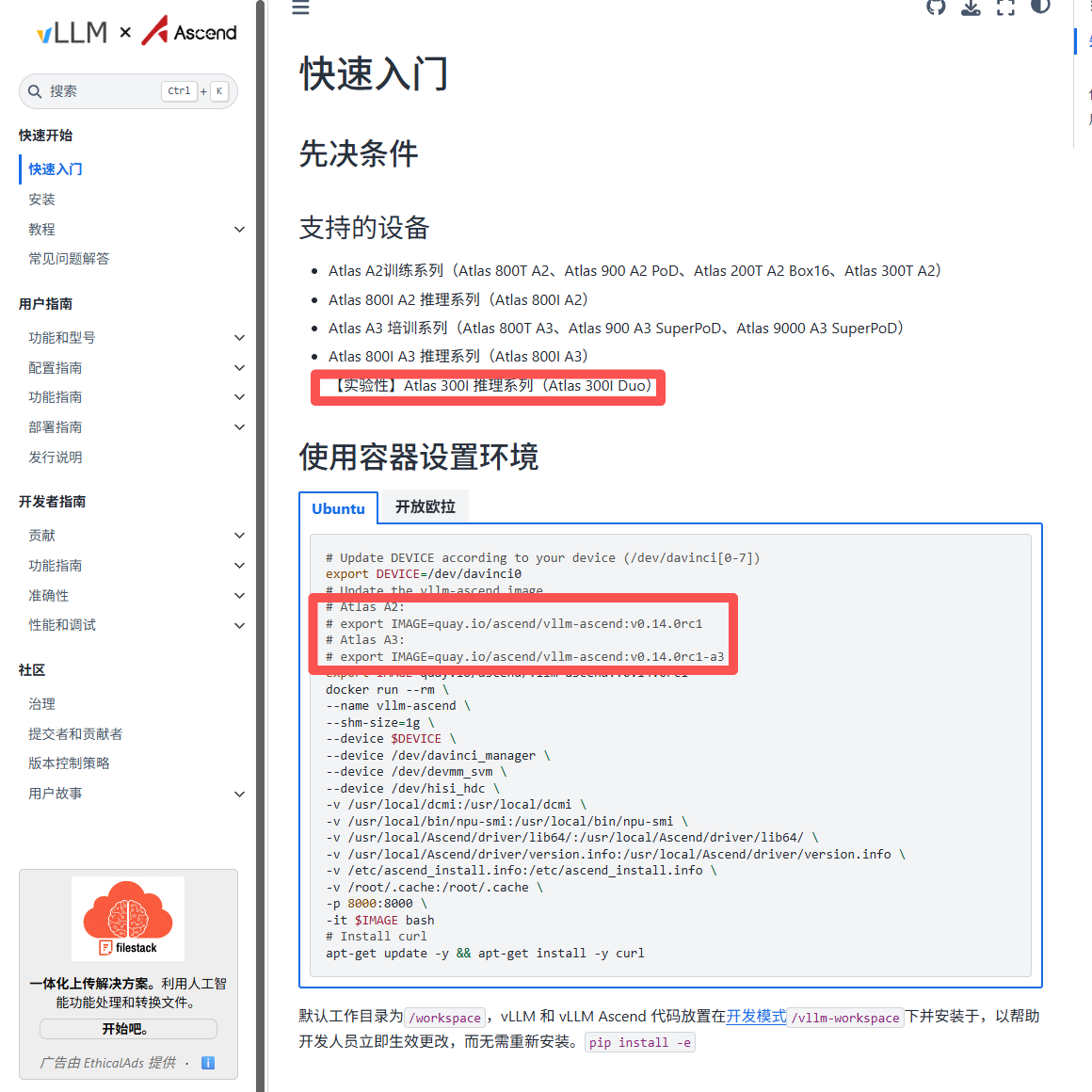
2.2 vLLM-Ascend(❌ 失败)
vLLM 是业界知名的GPU推理框架,其核心技术 PagedAttention 通过操作系统虚拟内存思想管理 KV cache,可将吞吐量提升 2-4× 。但在昇腾 300I duo上测试失败。
为了排除是模型太大影响,我也尝试了切换到qwen3-0.5b,为了排除是显卡只支持FP16或只支持BFP16,我两种都尝试了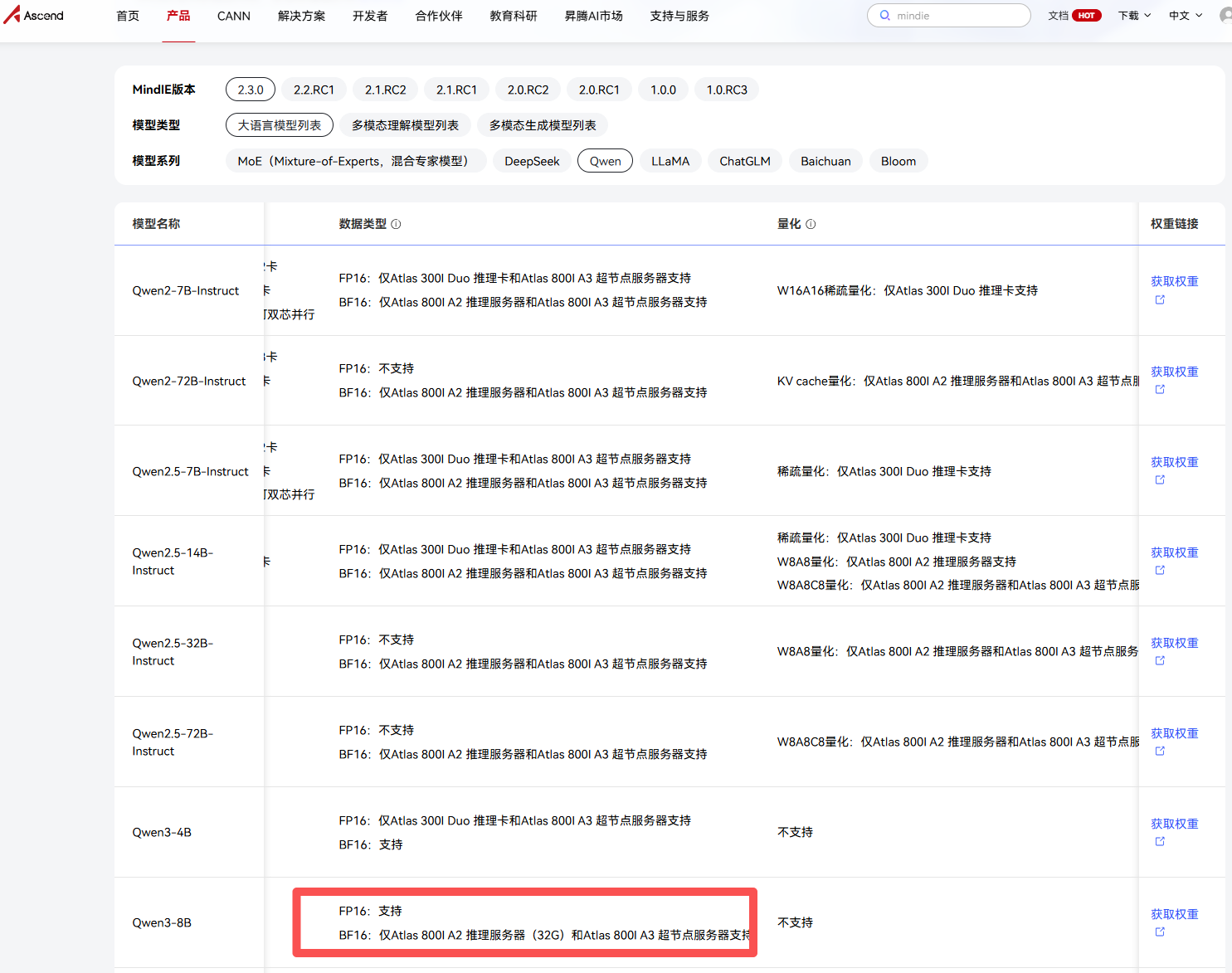
测试过程:
# 1. 拉取官方镜像
docker pull m.daocloud.io/quay.io/ascend/vllm-ascend:v0.14.0rc1-310p
# 2. 启动容器
sudo docker run --rm --name vllm-ascend \
--shm-size=1g \
--device /dev/davinci0 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home/tet:/workspace/models \
-p 8000:8000 \
-it m.daocloud.io/quay.io/ascend/vllm-ascend:v0.14.0rc1-310p bash
# 3. 测试推理
python test_vllm.py
失败原因:
# 错误日志
torch._dynamo.exc.Unsupported: Operator does not support running with fake tensors
Developer debug context: unsupported operator: _C.rotary_embedding.default
# 根本原因:
# vLLM-Ascend v0.14.0rc1-310p 的 rotary_embedding 算子在310P上不支持
# 官方文档也明确说明310P为"实验性支持"
技术分析:
vLLM 使用自定义 CUDA kernel 实现 rotary position embedding,这些算子需要在昇腾NPU上重新实现。虽然 vLLM-Ascend 项目在积极适配,但 不完善。
结论:❌ vLLM-Ascend 目前不适合在 310P 上部署 Qwen3-8B
2.3 MindIE(✅ 成功)
MindIE 是华为官方推理引擎,是华为显卡最靠谱的引擎了!如果它都不行,那我们即别测试了
三、MindIE 部署实战
不是所有模型都支持本显卡的部署。通过搜索官方文档可以知道mindie支不支持所需要部署的模型。本文将会安装qwen3 8b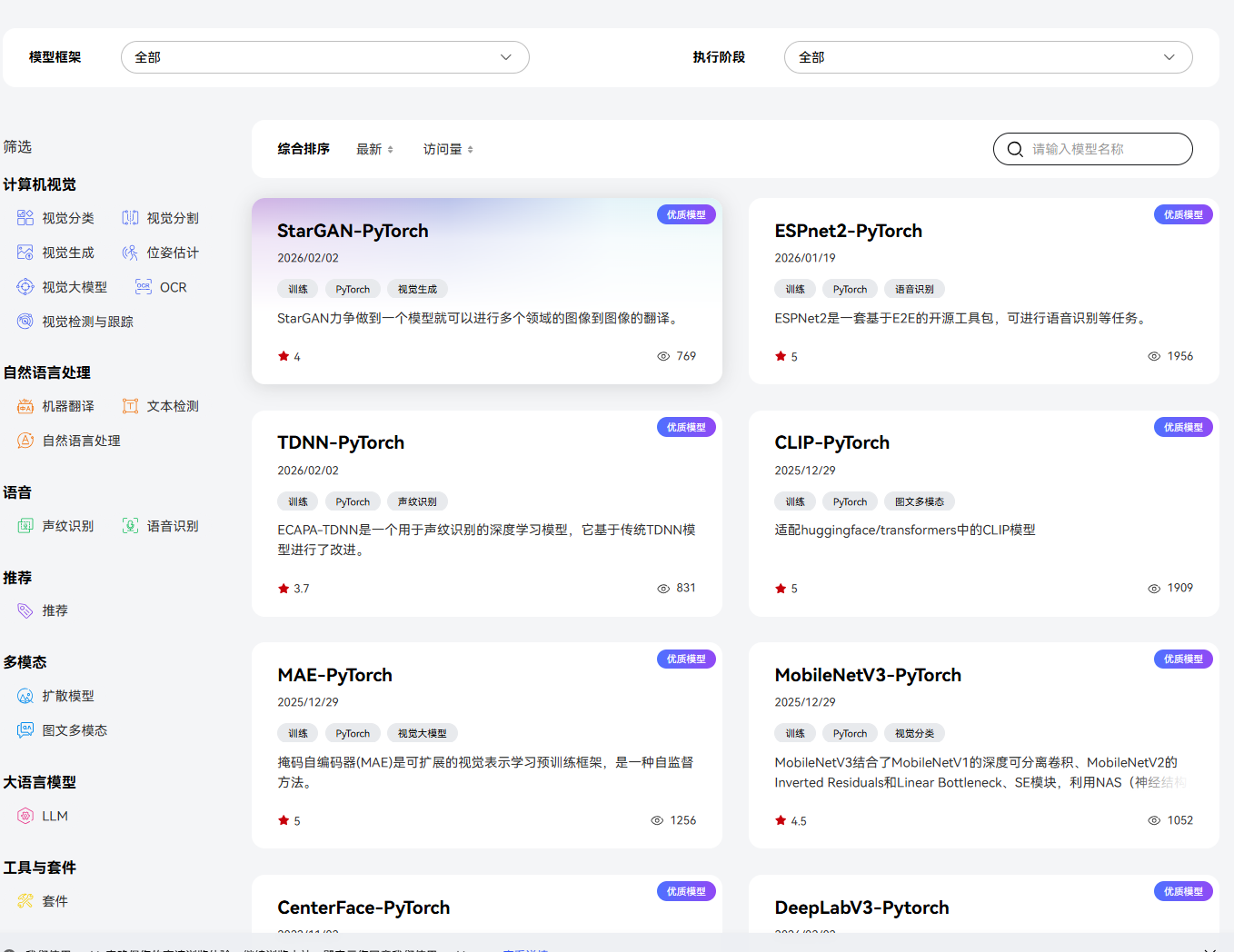
qwen3搜索后发现只有mindie2版本的支持,如果下成mindie1.X肯定是部署不上的;
如果出现没有的新的模型怎么部署,这个时候可以通过修改模型的config.json中model_type等操作,,但是一般都是不行的,本来就很难用还搞创新;那肯定没戏;我最开始就是下了mindie1.X一顿修改也没成;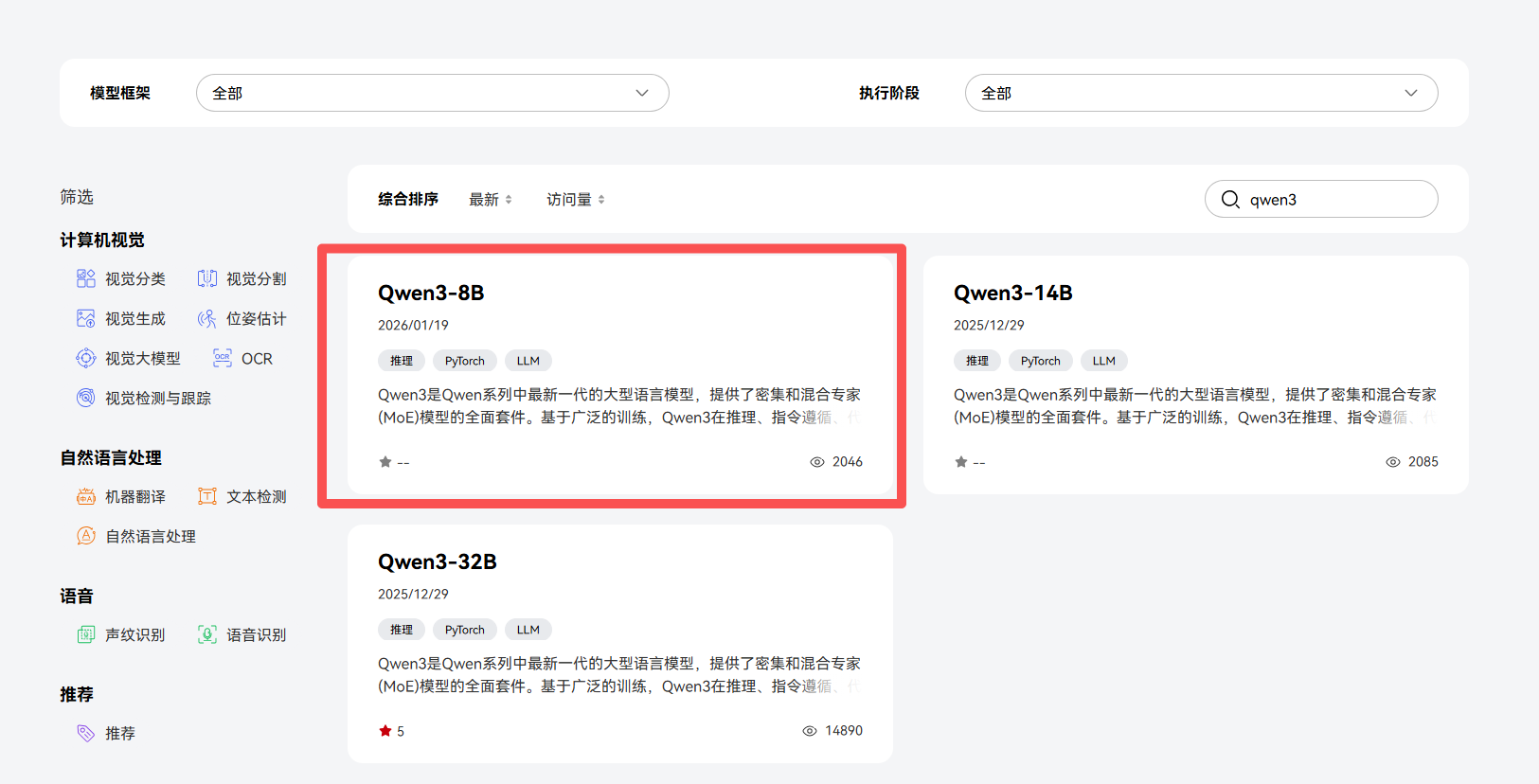
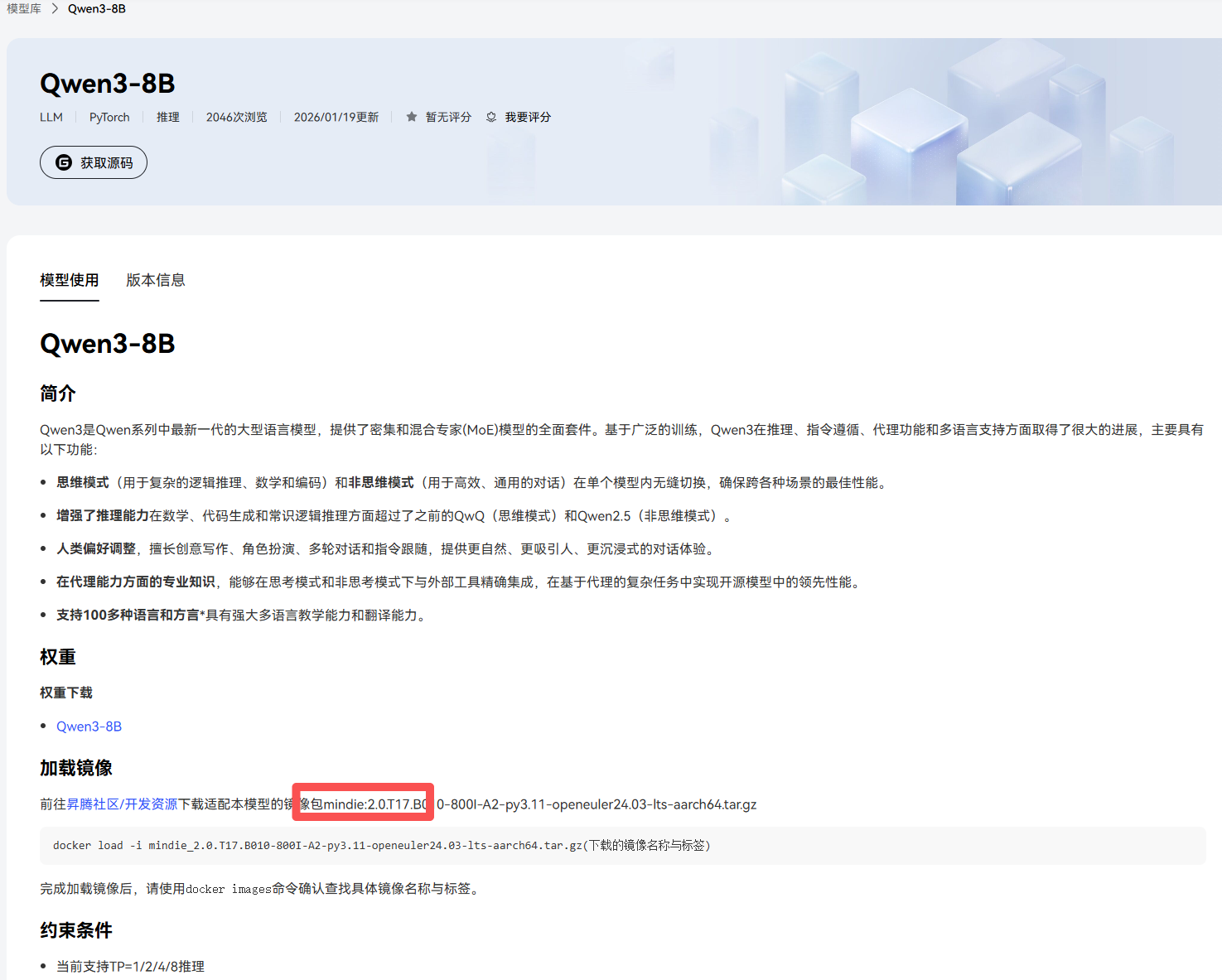
3.1 Docker 镜像选择
关键点:必须选择支持 300I 的mindie镜像
查看可用镜像(官网)根据我们的操作系统复制适合的镜像名,记得切换到这个tab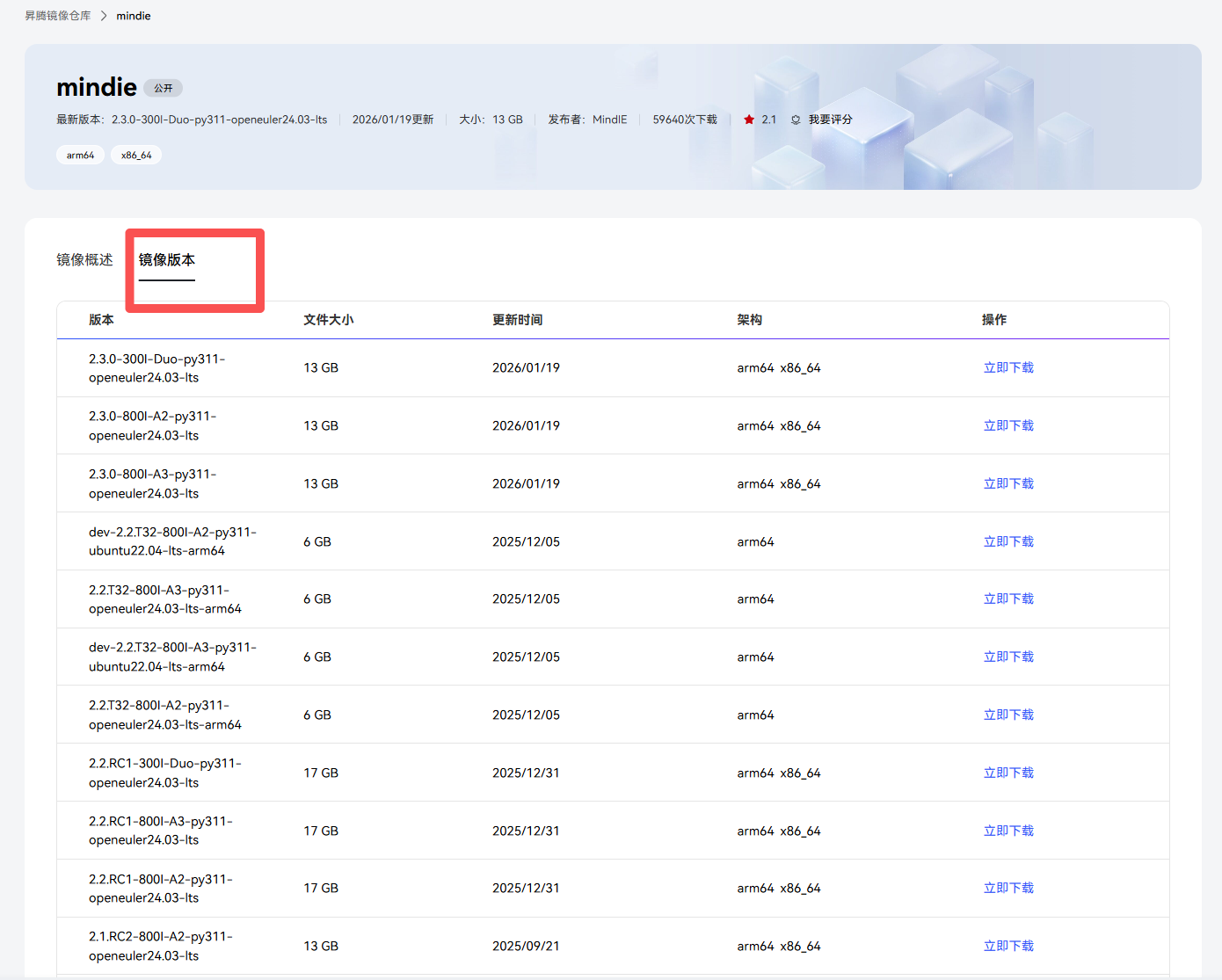
# 我们选择的版本(支持Qwen3)
MindIE 2.3.0-300I-Duo-py311-openeuler24.03-lts
# 拉取镜像
sudo docker pull --platform=amd64 swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.3.0-300I-Duo-py311-openeuler24.03-lts```
3.2 启动容器
使用镜像:
这里我先将服务器预先下好的qwen3通过命令挂载过去 -v /home/tet:/workspace/models
同时我们服务器是两张卡 所以我设置的device是/dev/davinci0和/dev/davinci1:
# 启动容器(后台运行)
sudo docker run -it -d --net=host --shm-size=1g \
--name mindie2 \
--device=/dev/davinci_manager:rwm \
--device=/dev/hisi_hdc:rwm \
--device=/dev/devmm_svm:rwm \
--device=/dev/davinci0:rwm \
--device=/dev/davinci1:rwm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/Ascend/firmware/:/usr/local/Ascend/firmware:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /path-to-weights:/path-to-weights:ro \
-v /home/tet:/workspace/models \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.3.0-300I-Duo-py311-openeuler24.03-lts bash
# 进入容器
sudo docker exec -it mindie2 bash
# 验证NPU可见
npu-smi info
关键配置说明:
--device=/dev/davinci0和davinci1:挂载双芯NPU-v /home/tet:/workspace/models:挂载模型目录--shm-size=1g:共享内存大小(重要!)
3.3 MindIE 服务配置
编辑配置文件:
vim /usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
关键配置:
{
"ServerConfig": {
"port": 1025,
"managementPort": 1026,
"metricsPort": 1027,
"httpsEnabled": false // 建议改为false
},
"BackendConfig": {
"npuDeviceIds": [[0, 1]], // 依情况修改:双芯配置
"ModelDeployConfig": {
"truncation": false,
"ModelConfig": [
{
"modelName": "qwen3",// 依情况修改
"modelWeightPath": "/workspace/models/Qwen3-8b",// 依情况修改
"worldSize": 2 // 必须与 npuDeviceIds 数量一致
}
]
}
}
}
⚠️ 重要:
worldSize必须等于 NPU 数量httpsEnabled设为false(避免证书问题)- 模型路径使用容器内路径
3.5 设置环境变量
# 查找并执行环境设置脚本
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# # 添加动态库路径(如果报了动态链接库错误,可能不需要)
# export LD_LIBRARY_PATH=/usr/local/Ascend/mindie/1.0.RC3/mindie-service/lib:$LD_LIBRARY_PATH
# export LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:$LD_LIBRARY_PATH
# 保证模型所在的目录是750,不能是777因为mindie要求
chmod -R 750 /workspace/models/Qwen3-8b
# 报错可能会很多,先开启详细日志
export MINDIE_LOG_LEVEL=INFO
export MINDIE_LOG_TO_STDOUT=1
3.6 启动服务
cd /usr/local/Ascend/mindie/latest/mindie-service/bin
# 启动服务
./mindieservice_daemon
预期输出:
Daemon start success!
四、测试验证
4.1 API 测试(容器外执行)
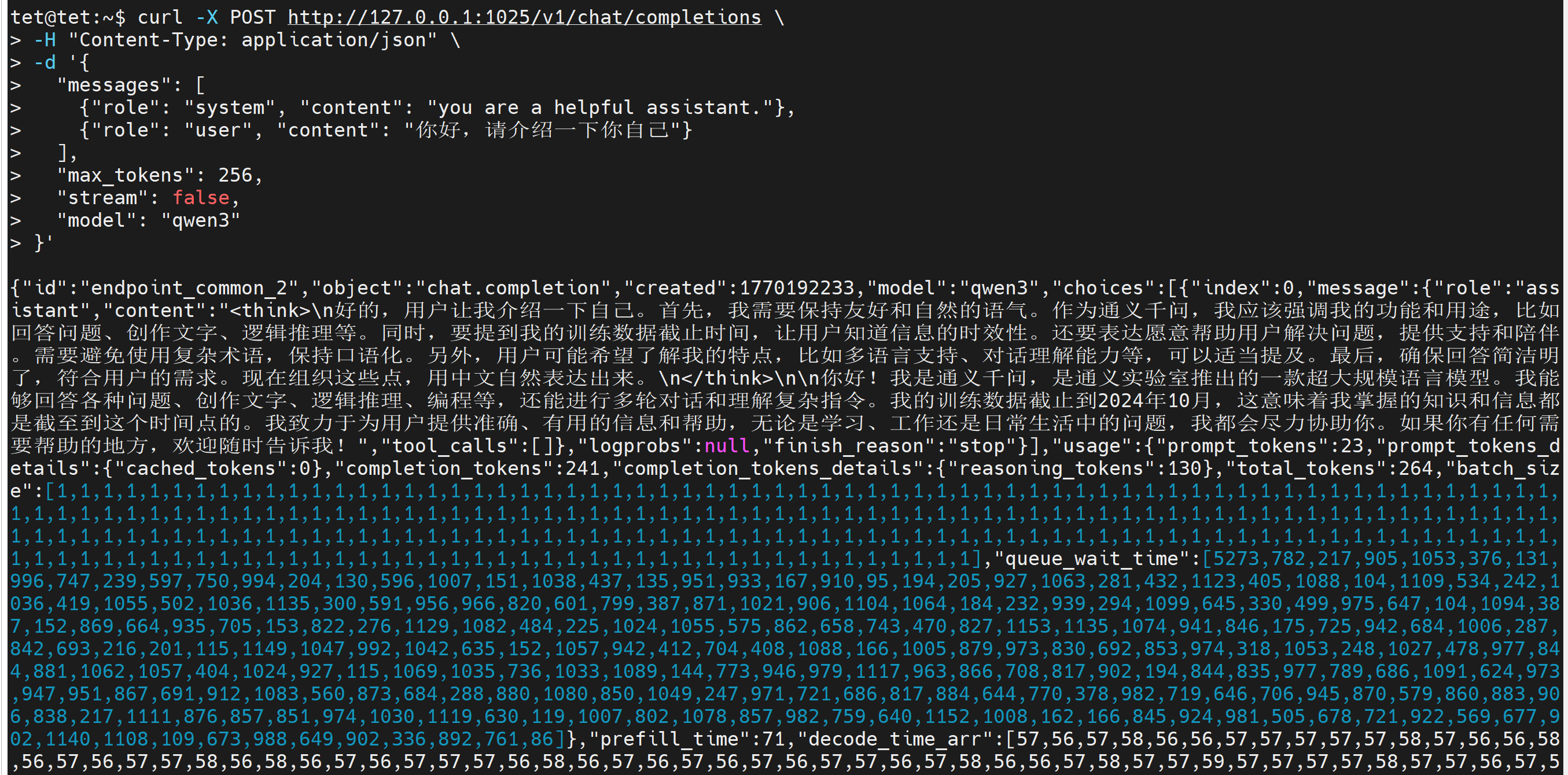
curl -X POST http://127.0.0.1:1025/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "you are a helpful assistant."},
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"max_tokens": 256,
"stream": false,
"model": "qwen3"
}'

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 27
27 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)