GLM-4.7-Flash模型部署踩坑记
基于vllm部署GLM-4.7-Flash模型
2026-01-21日,魔搭社区上出现了智谱AI最新开源的GLM-4.7-Flash模型。作为智谱AI最新开源的轻量化大模型,GLM-4.7-Flash凭借30B总参数量+3B活跃参数量的MoE架构,为轻量级部署提供了在性能与效率之间取得平衡的新选择。尤其适合消费级硬件本地部署。相信不少开发者和我一样,都想实际验证这款最新模型的使用体验。近期本人基于 vLLM 推理框架尝试部署该模型,屡屡碰壁,多次遇到模型加载失败等问题,相信还有不少人现在也没琢磨出来。因此整理了这份实操总结,希望能帮助各位 AI 技术探索者少走弯路。
一、直接用模型首页介绍的方法无法加载模型(避雷)
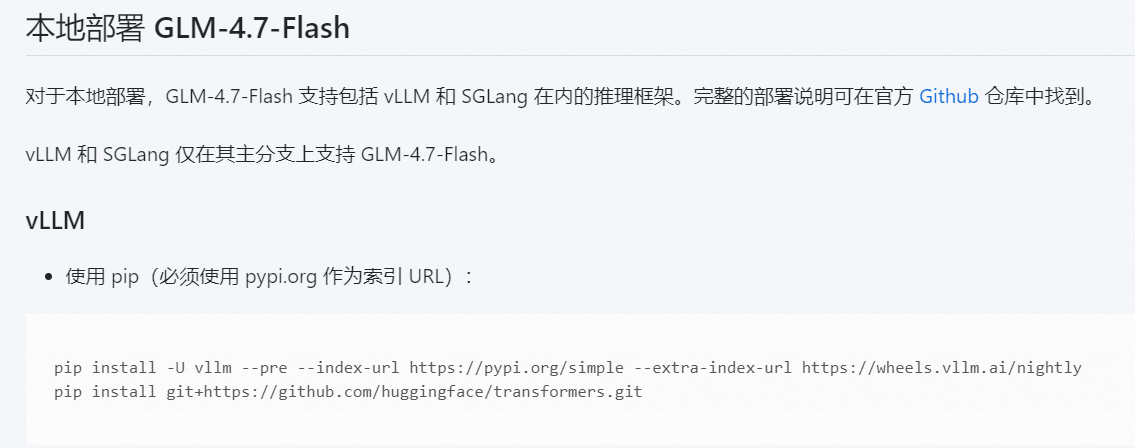
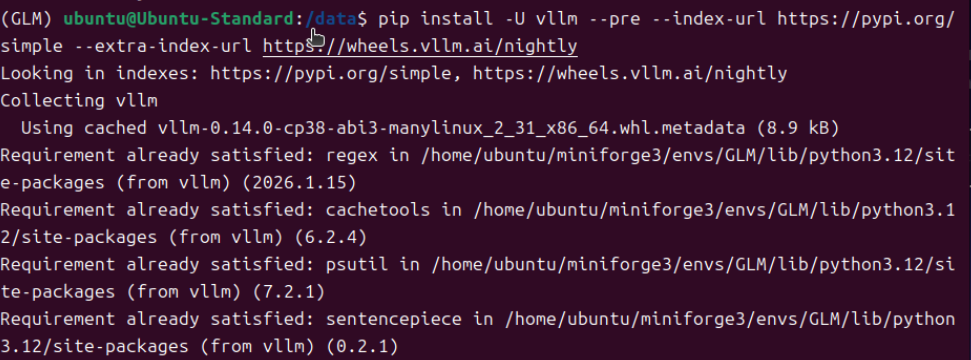
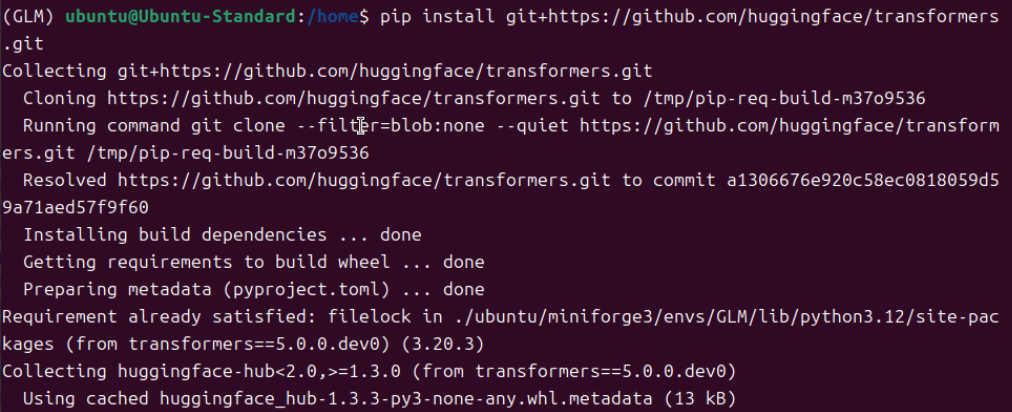
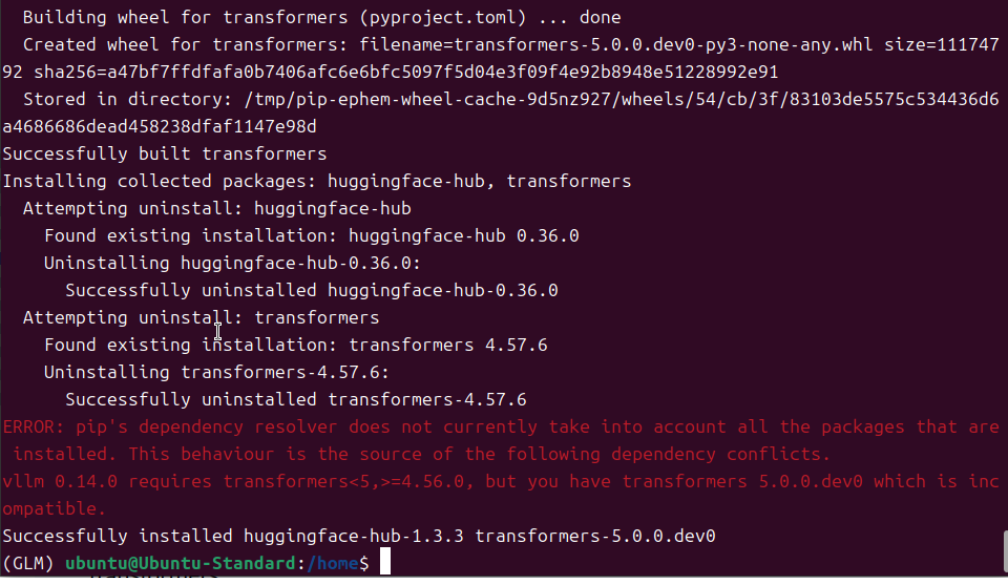
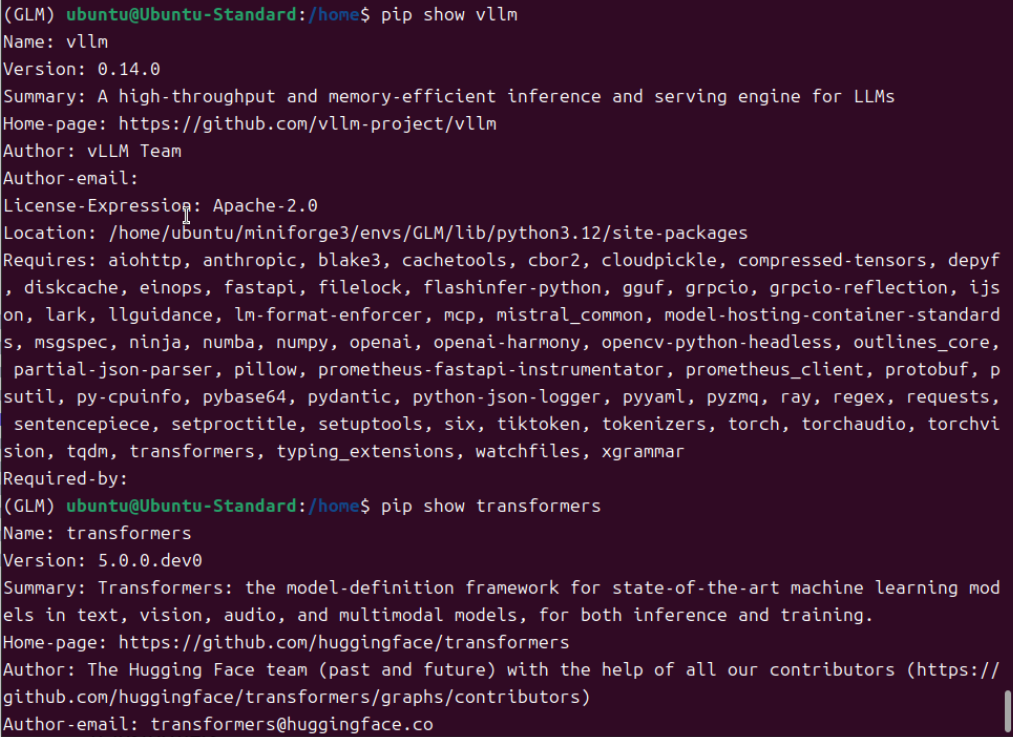
根据https://modelscope.cn/models/ZhipuAI/GLM-4.7-Flash模型介绍的安装方法就到此结束了。很多AI探索者可能觉得可以加载模型了。我开始也这样认为,实际情况是模型加载各种错误,调vllm加载模型的各种参数,依然无法另模型成功启动。官方的提供的命令安装方式只会安装到稳定版的vllm=0.14.0,甚至最新的vllm=0.14.1。
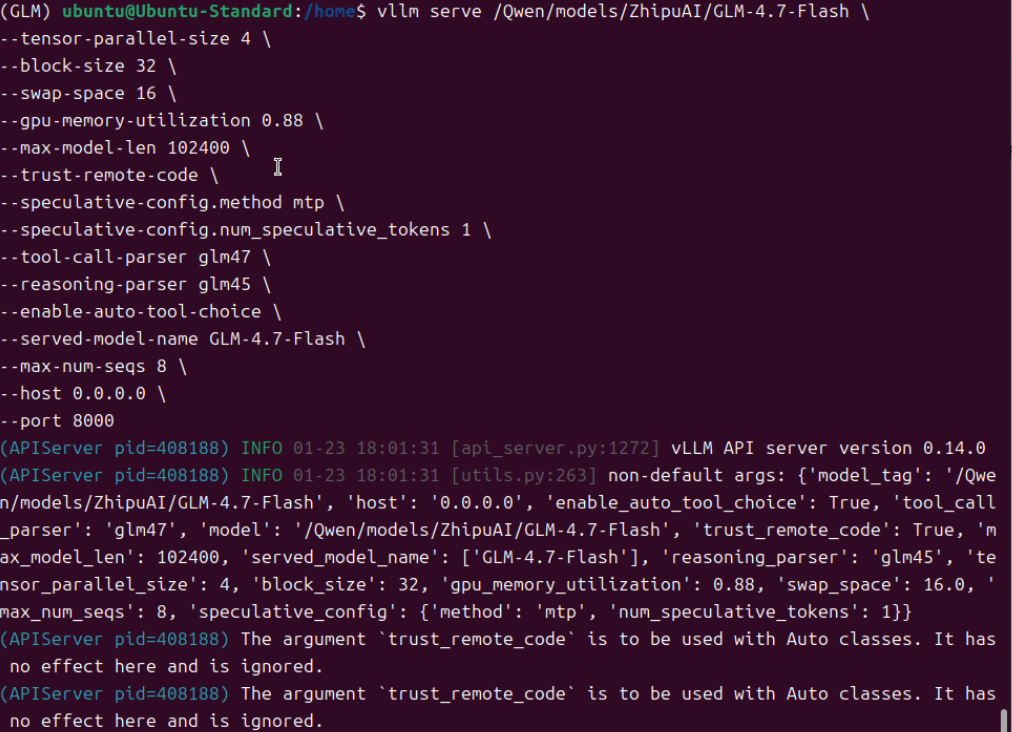
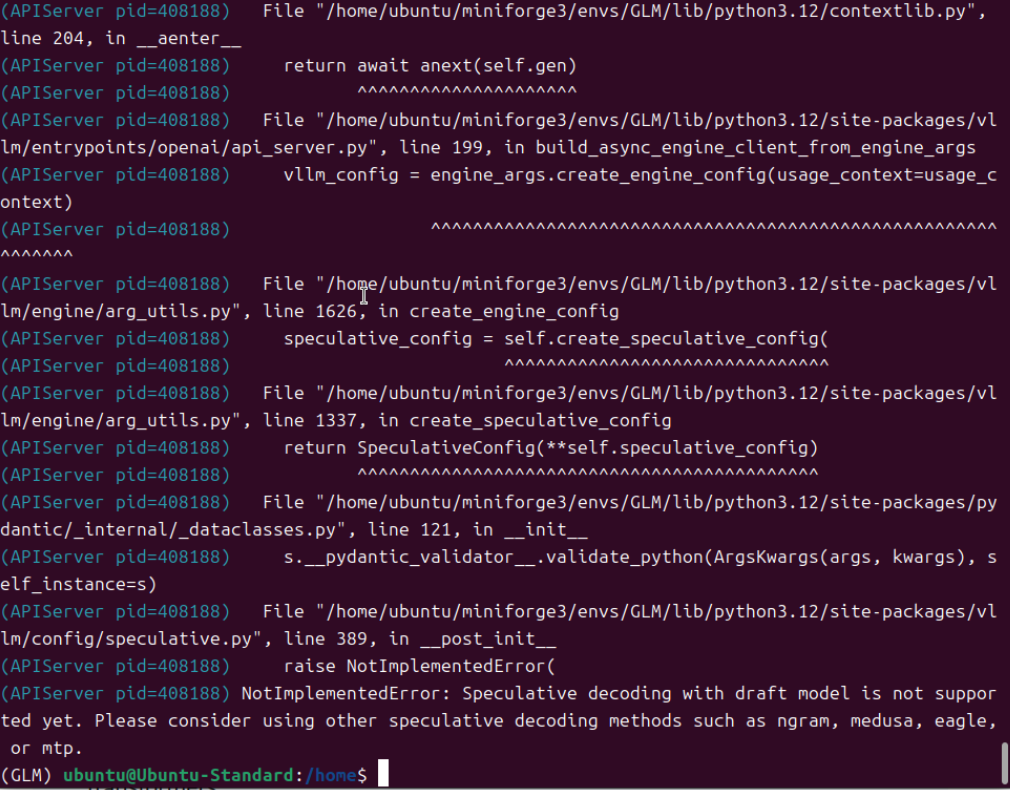
根据上述的错误,我尝试去掉“--speculative-config.method mtp \ 和 --speculative-config.num_speculative_tokens 1 \”,但模型依然无法正常加载。
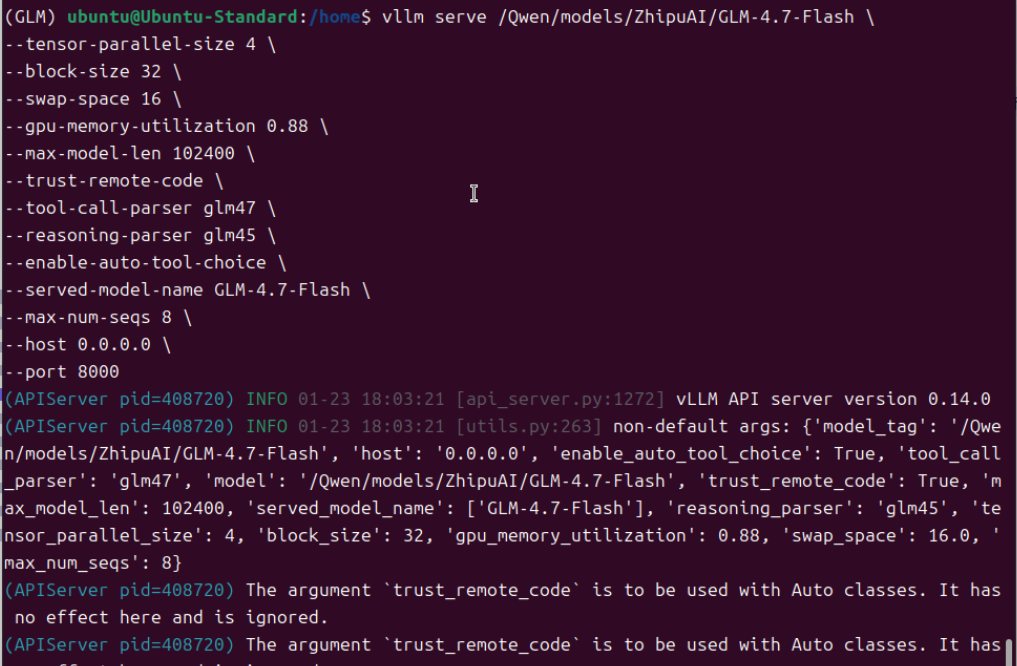
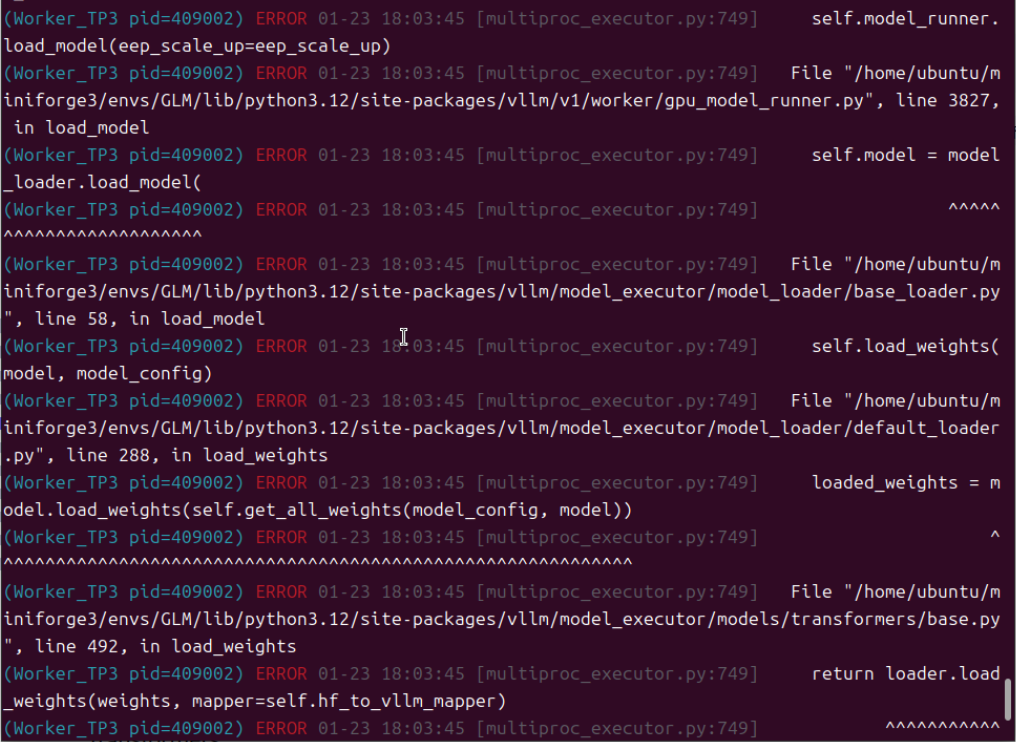
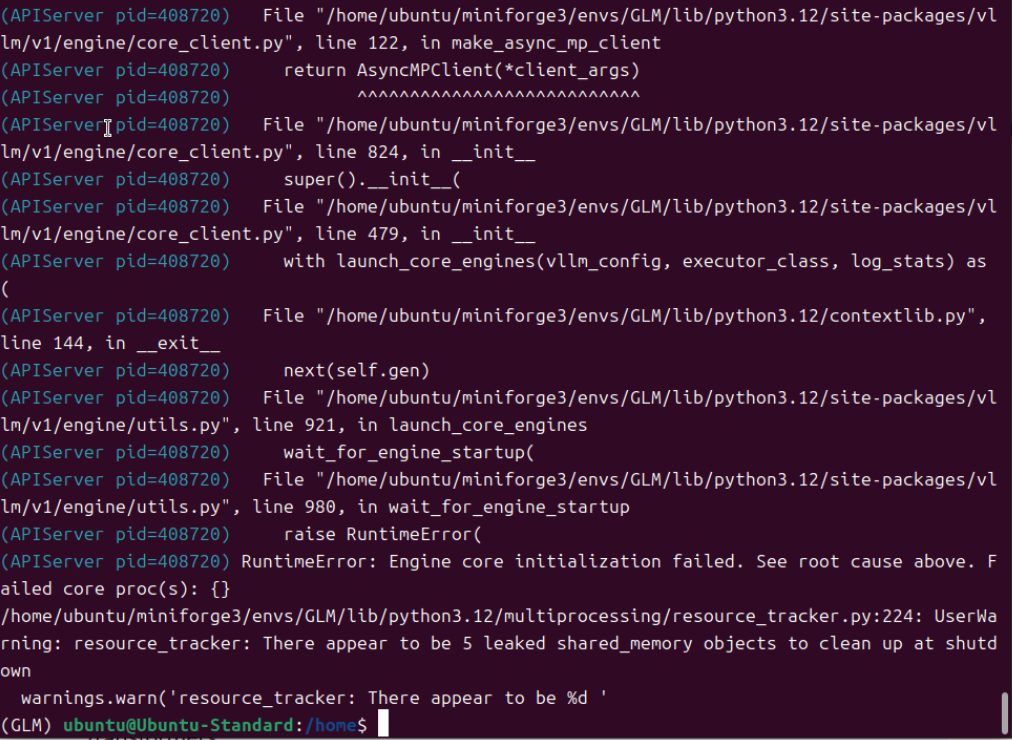
由此推测,官方的安装方法,是无法加载模型的,需要用另外的方法安装开发版/非稳定版。
二、如何安装开发版/非稳定版的vllm和transformers
安装vllm和transformers是有顺序的,必须先安装vllm,然后再安装transformers。如果先安装transformers后安装vllm,transformers会被vllm默认的transformers版本4.57.6覆盖,模型依然是无法加载启动的。
1.安装开发版/非稳定版vllm
这个版本的版本号会不断更新及变化,查找出来了就赶快安装,如果无法安装,就再次用命令刷新最新的版本号,再进行修改安装。
例如:
pip install vllm==0.14.0rc2.dev229+geb1629da2 --extra-index-url https://wheels.vllm.ai/nightly --force-reinstall由于最新的库里没有之前的版本号,但我们在库里找到了0.14.0rc2.dev261+gbc917cceb,把这个版本号,替换到安装的命令中,就能顺利安装了。
pip install vllm==0.14.0rc2.dev261+gbc917cceb --extra-index-url https://wheels.vllm.ai/nightly --force-reinstall注意:所有安装命令中的版本号均按实际环境刷新的最新 / 适配版本调整,不再沿用原固定版本号,后续相关部署、安装类操作会参考此方法执行。
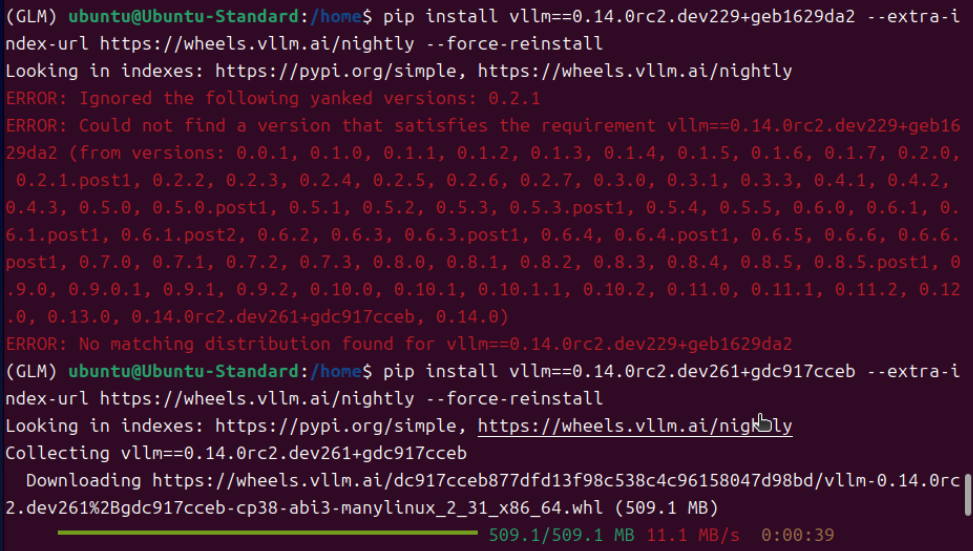
2.安装开发版/非稳定版transformers
pip install git+https://github.com/huggingface/transformers.git 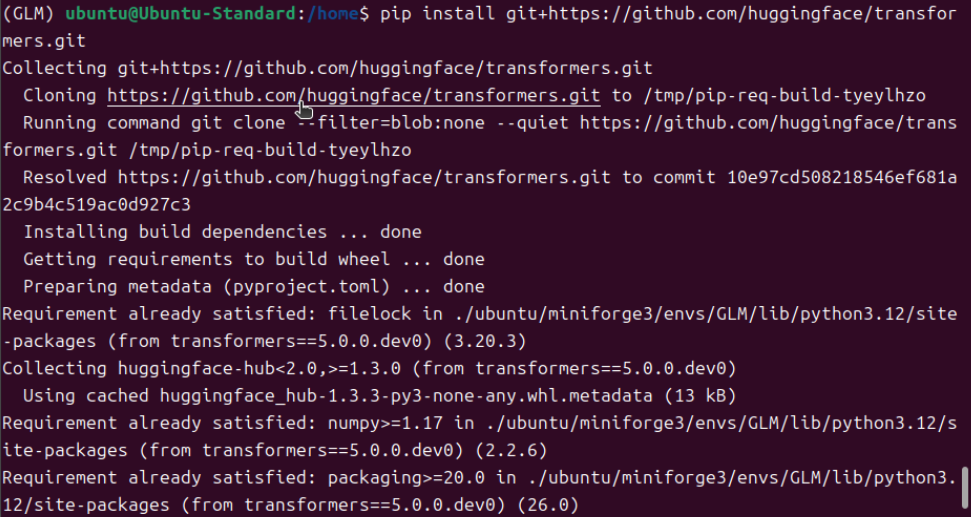
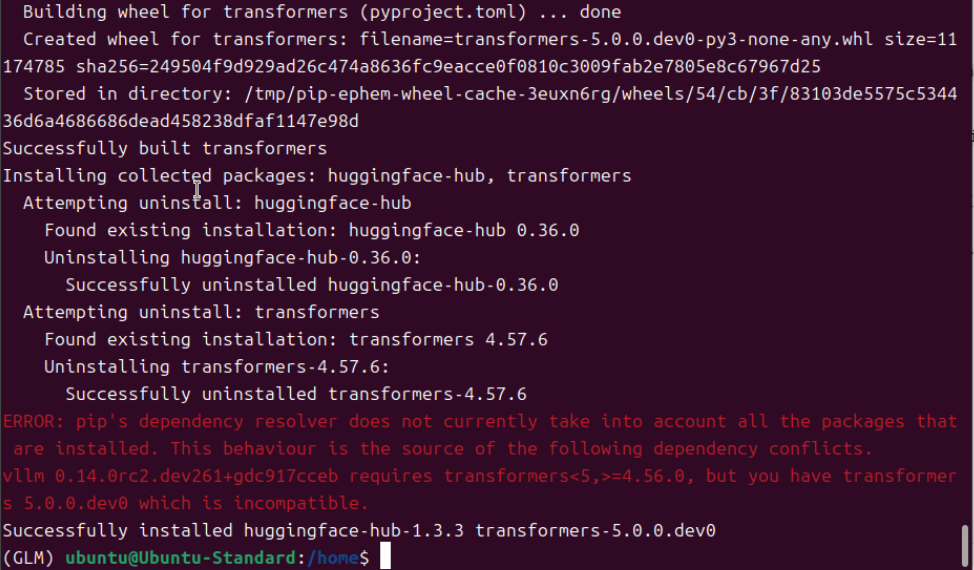
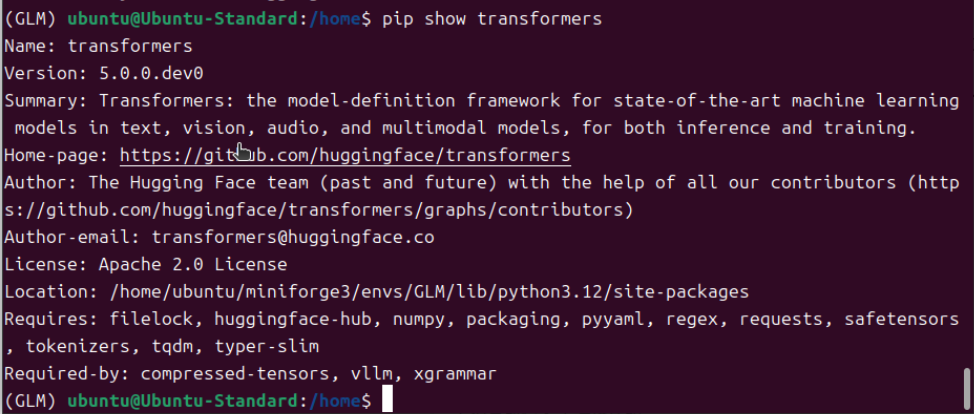
三、加载模型及测试
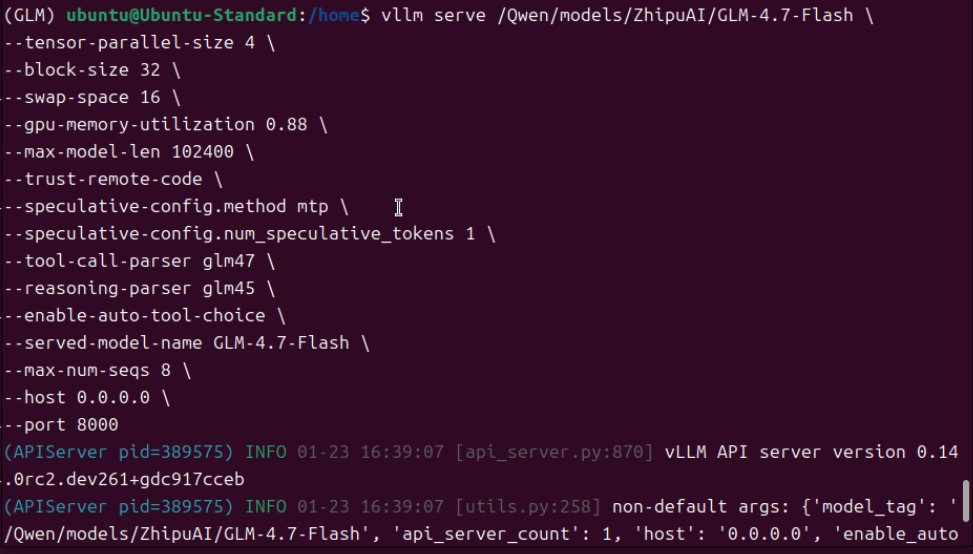
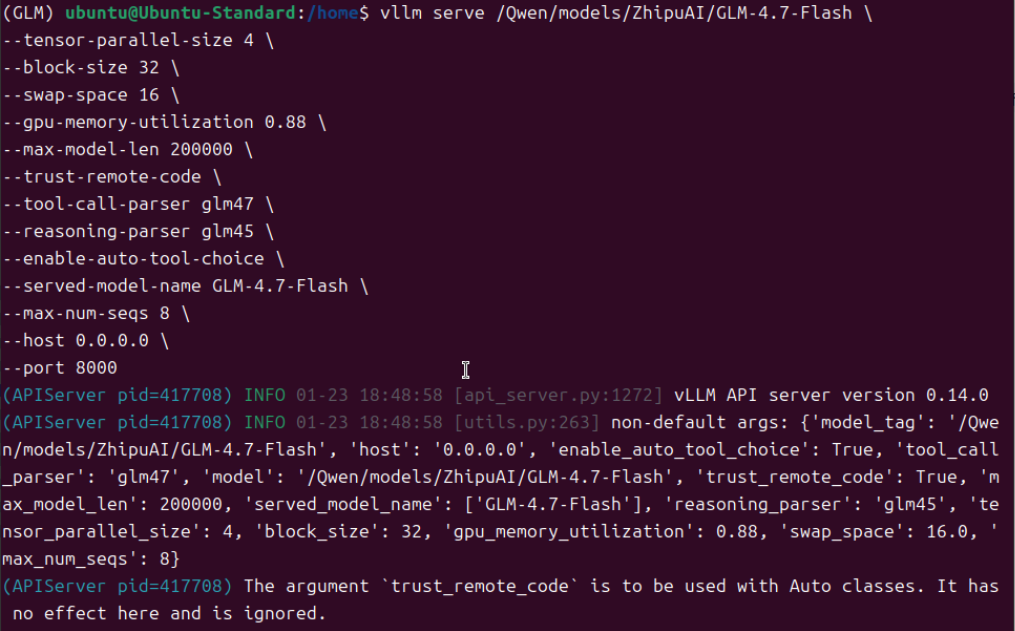
完成前述安装步骤后,即可进行模型加载测试。需注意,不同硬件环境对应的启动参数及模型运行效果存在差异,请根据自身实际环境调整参数并测试验证。
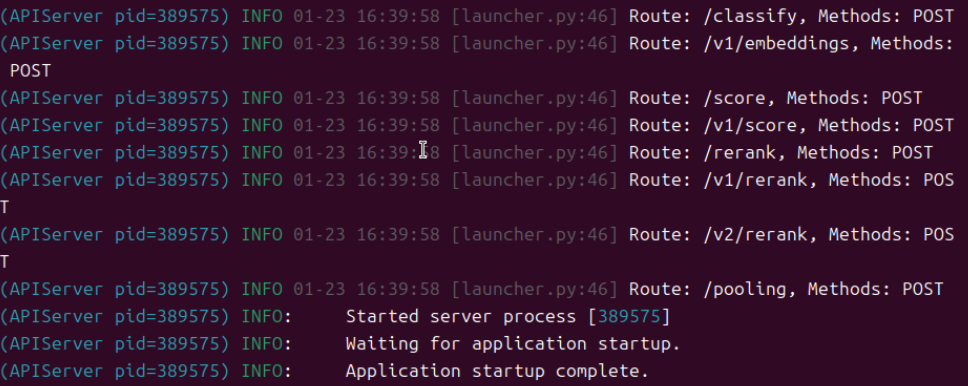
四、上下文长度测试
1.上下文长度调整到200k左右
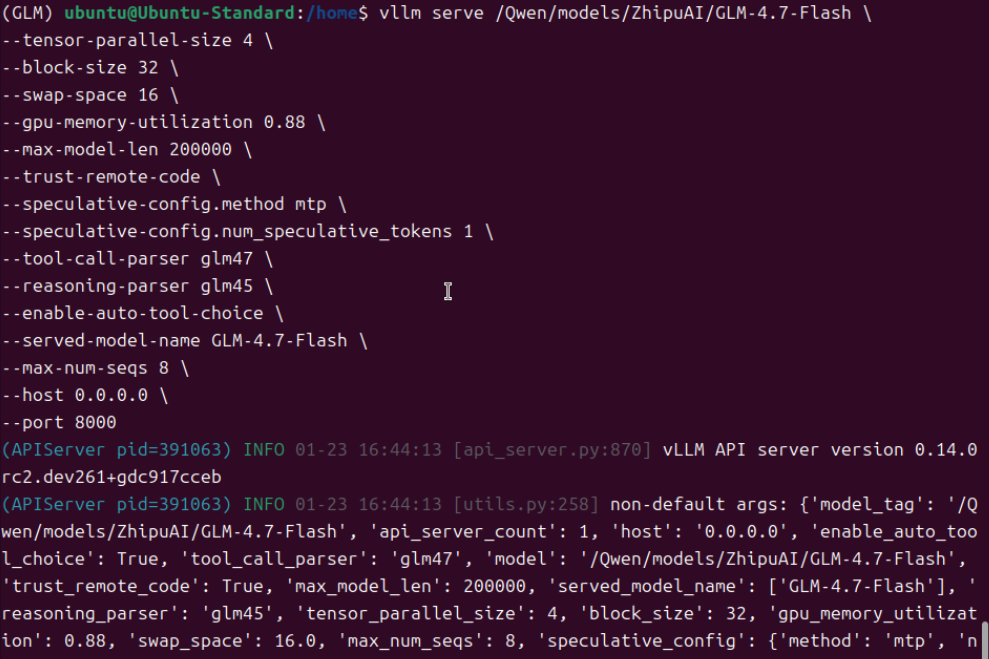
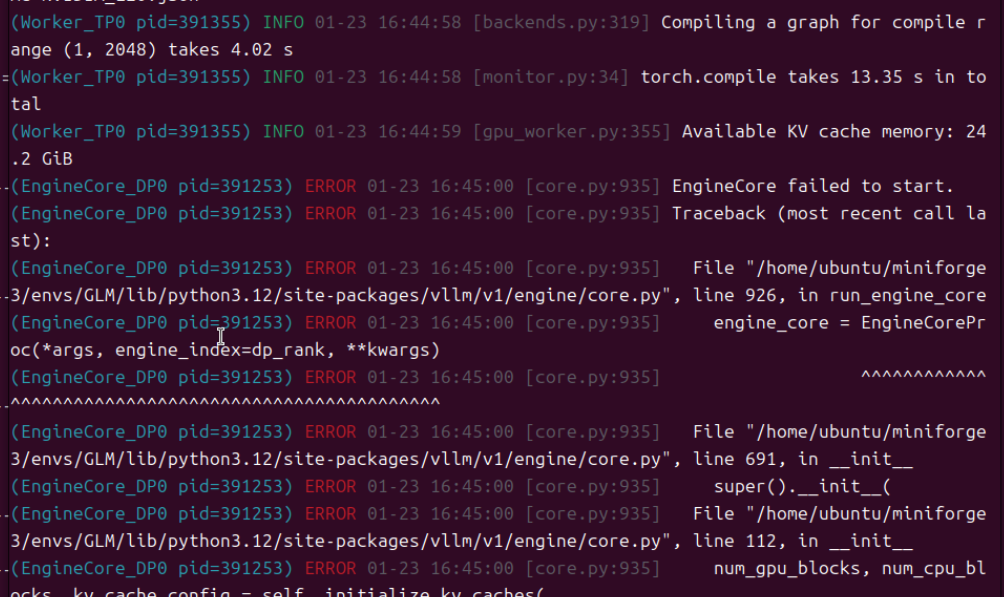
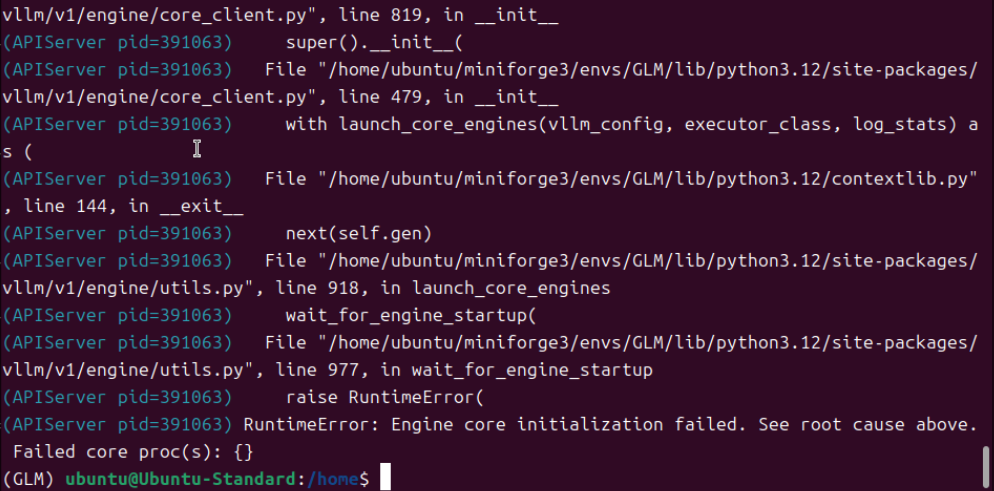
发现报错了,加载模型失败。
是参数不生效,还是算力不足?
删除参数测试
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
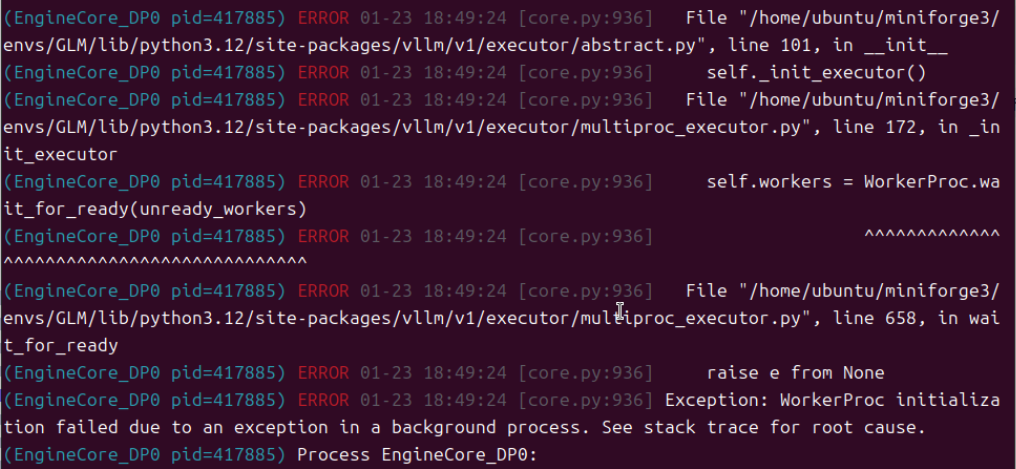
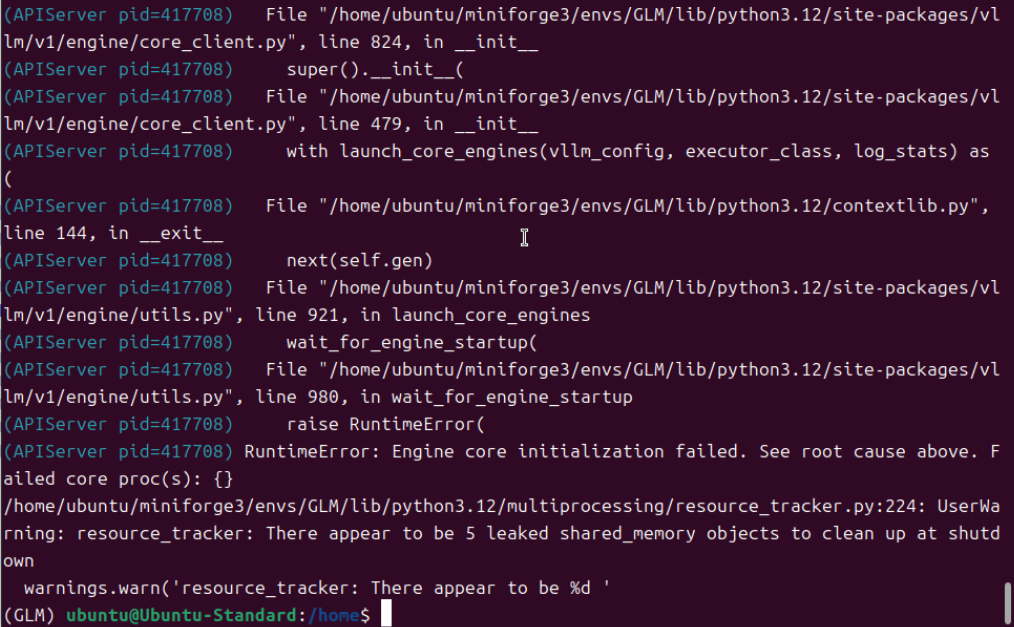
删除启动参数的方法也失败了,官方既然给出了“--speculative-config.method mtp \ 和 --speculative-config.num_speculative_tokens 1 \” 肯定有它的优势在,而且经过测试,发现这条参数命令必须配套使用,只用任意一条都会报错。
2.有没有办法在增加上下文长度?

- 可以参考网友说的这个,但应该很多人不知道“model_arch_config_convertor.py”这个文件在哪里。我尝试用命令which model_arch_config_convertor.py 没找到。后面用最笨的方法,Python隔离环境几个关键目录下找,功夫不怕有心人,终于找到了。路径如下:
- 注意:因所使用的 Python 环境隔离工具不同,其安装路径及存放位置也会存在差异,本文档中的相关路径仅作参考。

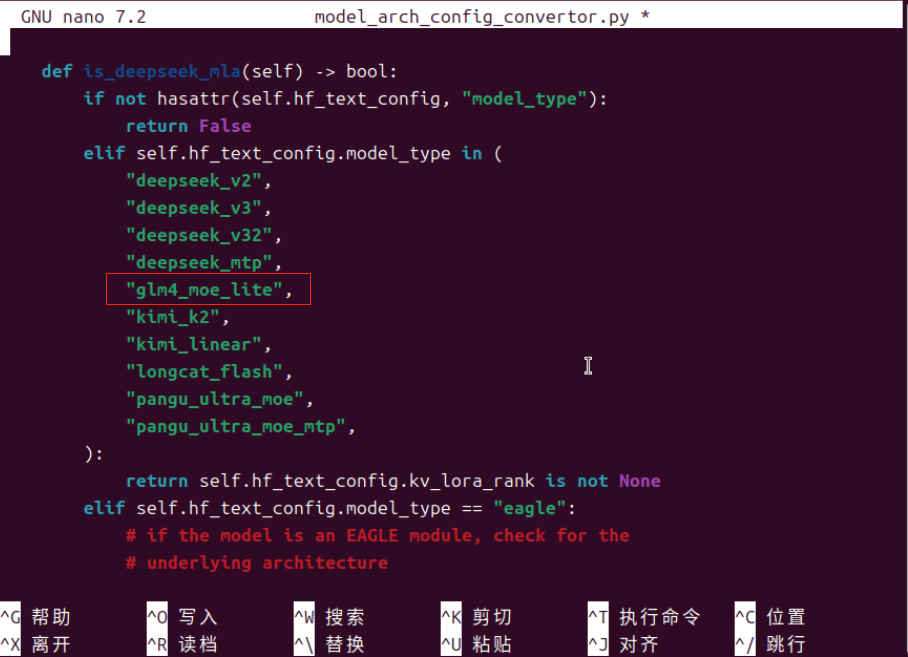
在“model_arch_config_convertor.py”中增加“glm_moe_lite”,如上图所示。
3.再次启动模型测试 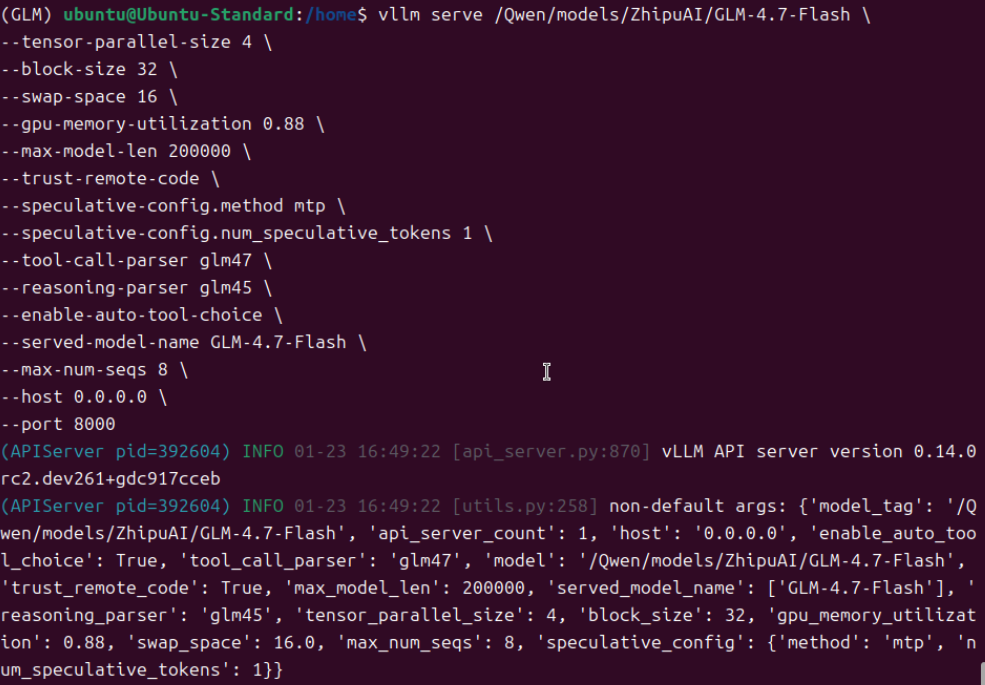
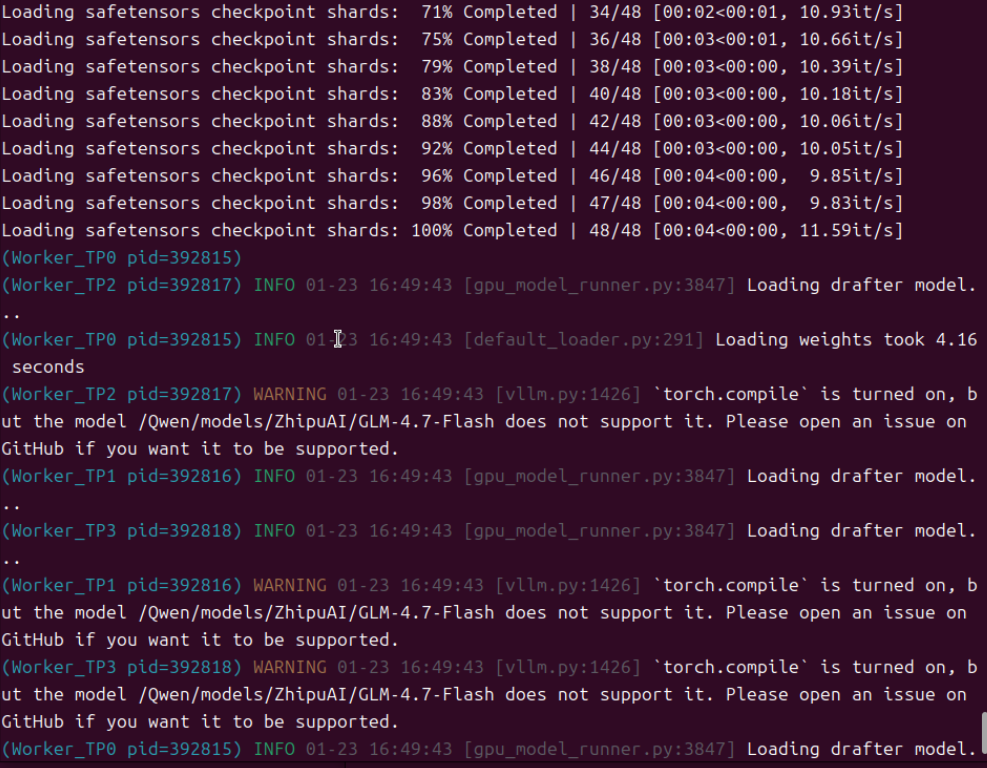
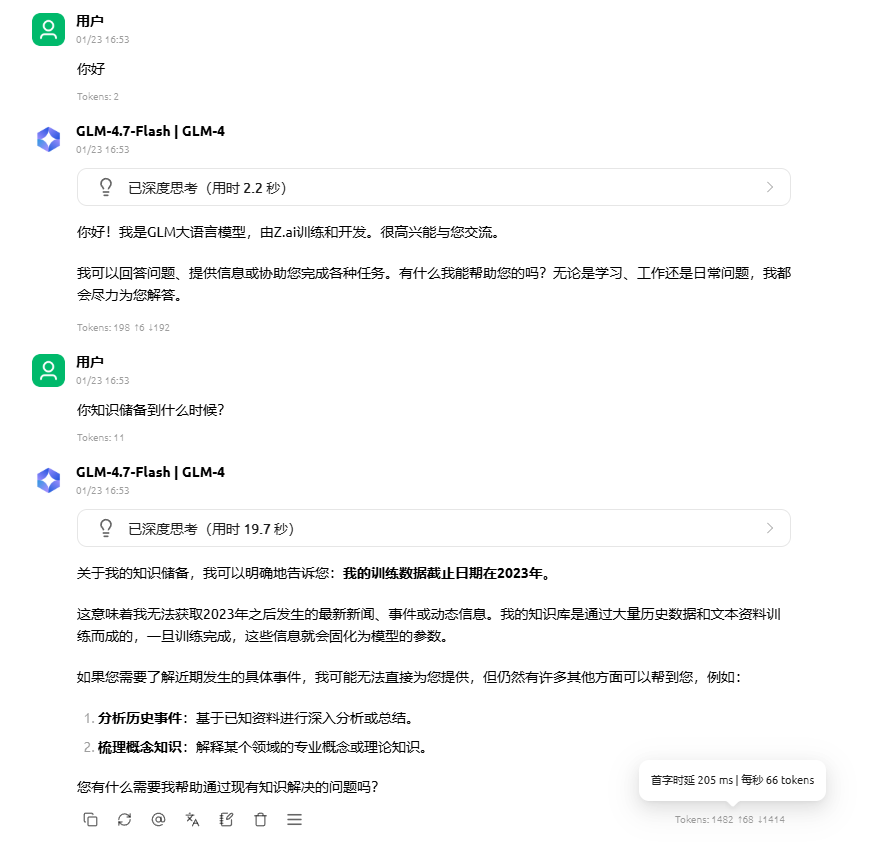 用200K上下文长度测试,发现模型能正常加载了,说明修改是有效的。但测试发现模型反应速度变慢了,约66tokens/s。
用200K上下文长度测试,发现模型能正常加载了,说明修改是有效的。但测试发现模型反应速度变慢了,约66tokens/s。
4.降低上下文长度再测试
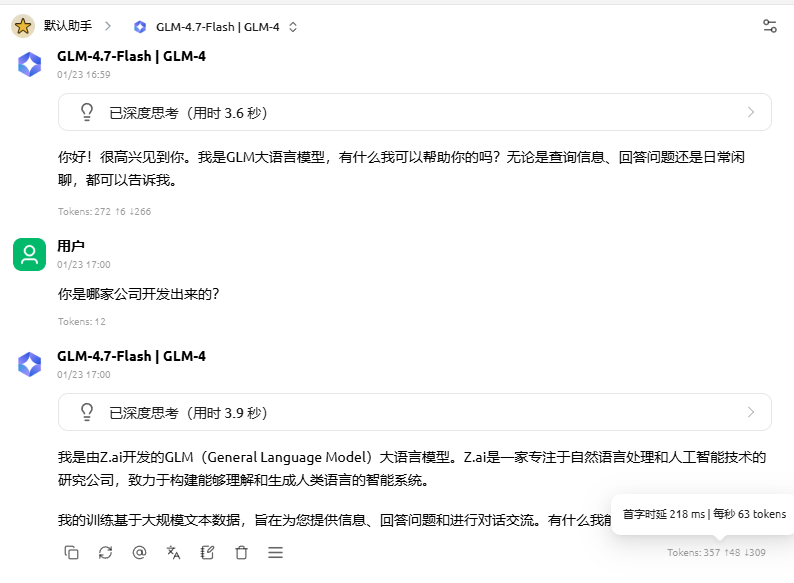
降低了上下文长度,但速度依然没改善,说明启用mtp,模型响应速度会下降。
结论:
若上下文长度较短,或硬件资源充足,建议暂不修改model_arch_config_convertor.py文件 —— 该文件修改后会导致模型的响应速度下降。仅当硬件资源受限,但需支持更长上下文时,修改此文件才具备实际意义。不过,修改后模型能否真正发挥 200K 上下文的能力,需结合实际环境自行测试验证。
这是我第一次在 CSDN 发文章,内容难免有疏漏,还请大家多多包涵~ 如果这篇内容能帮到你,不妨点个赞;有任何问题,可以评论区留言或者私信我。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)