从零开始构建 Mini vLLM:深入理解大模型推理优化
来分享下如何从零开始mini版本的vLLM,当运行 vLLM 这类大模型推理引擎时,背后究竟发生了什么?这个问题驱使开发者构建了——一个极简的、面向教学的高性能 LLM 推理引擎实现。可以把它理解为"傻瓜版 vLLM",专门用来揭开推理优化的神秘面纱。这篇文章将带你深入了解大模型推理的各项优化技术,看看它们究竟是如何工作的。
最近看到一些mini版本的vLLM实现,比如:
- https://github.com/ovshake/nano-vllm/
- https://github.com/Wenyueh/MinivLLM/tree/main
- https://github.com/ubermenchh/mini-vllm
- https://github.com/skyzh/tiny-llm
- https://github.com/GeeeekExplorer/nano-vllm
下面本文结合:
- https://github.com/ovshake/nano-vllm/blob/main/BLOG.md
来分享下如何从零开始mini版本的vLLM,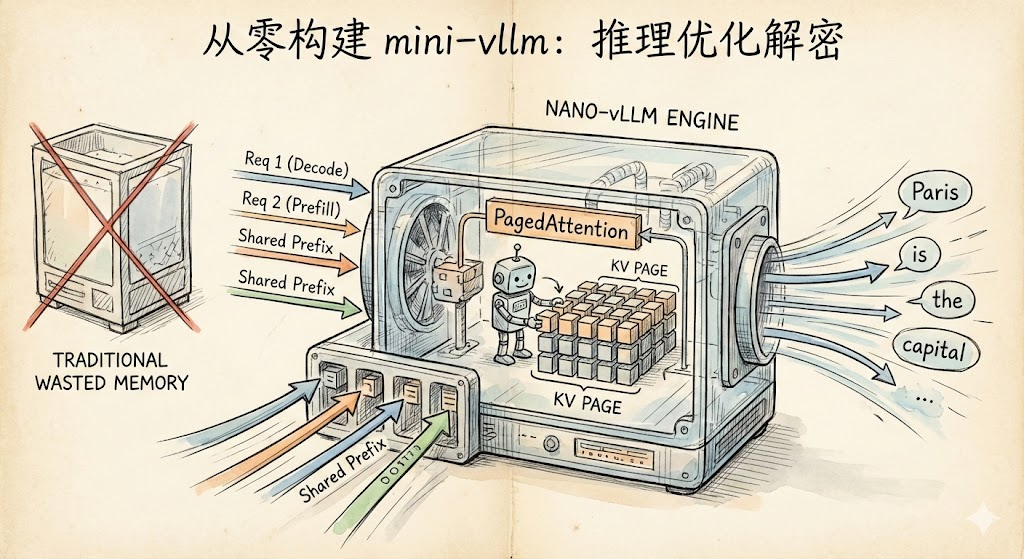
当运行 vLLM 这类大模型推理引擎时,背后究竟发生了什么?这个问题驱使开发者构建了 nano-vllm——一个极简的、面向教学的高性能 LLM 推理引擎实现。可以把它理解为"傻瓜版 vLLM",专门用来揭开推理优化的神秘面纱。
这篇文章将带你深入了解大模型推理的各项优化技术,看看它们究竟是如何工作的。
为什么 LLM 推理这么难搞
运行大模型推理,远不只是做几次矩阵乘法那么简单。传统的逐个请求处理方式会造成惊人的 GPU 显存和算力浪费。
大模型生成文本时分为两个阶段:
Prefill 阶段:一次性处理整个 prompt(计算密集型)
Decode 阶段:逐个生成 token(显存密集型)
Decode 阶段尤其值得关注。生成每个新 token 时,模型都需要通过注意力机制回看所有之前的 token。如果不做缓存,就得反复计算相同的内容。这就是 KV cache 存在的意义。
但问题来了:如果按照最大可能序列长度预分配 KV cache 显存,会造成极大的浪费。假设最大长度是 2048 tokens,但实际序列只有 100 tokens,那就浪费了 95% 的显存!
这正是 vLLM 通过 PagedAttention 解决的核心问题,也是 nano-vllm 要实现的关键技术。
整体架构设计
nano-vllm 的代码组织结构如下:
nano_vllm/
├── engine.py # 主推理引擎
├── config.py # 模型配置
├── cache.py # KV cache 实现
├── sampler.py # Token 采样
├── core/
│ ├── sequence.py # 请求跟踪
│ ├── scheduler.py # 带优先级的批调度
│ ├── block.py # PagedAttention 的内存块
│ └── block_manager.py # 内存块分配器(类似 OS 内存管理)
├── attention/
│ ├── paged_attention.py # PagedAttention 核心实现
│ └── flash_attention.py # FlashAttention 集成
├── speculative/
│ └── speculative_decoding.py # 推测解码
├── educational/ # 可视化学习模式
│ ├── narrator.py # 白话解释
│ ├── xray.py # 张量可视化
│ └── dashboard.py # 实时终端界面
└── model/
├── loader.py # HuggingFace 模型加载
└── llama.py # Llama 实现(RMSNorm、RoPE、GQA、SwiGLU)
接下来逐个剖析核心优化技术。
PagedAttention:vLLM 的灵魂
传统方案的问题
传统的 KV cache 分配方式,就像为一个人预订整个电影院,"以防"他带来 1999 个朋友。这种做法显然很浪费。
传统方案会根据最大可能长度,为每个序列预分配一大块连续显存,导致:
- 内存碎片化:不同序列在不同时间结束,留下空洞
- 显存浪费:大多数序列永远达不到最大长度
- 批处理受限:GPU 显存装不下太多请求
PagedAttention 的解决方案
PagedAttention 借鉴了操作系统虚拟内存的思想。它不再连续分配,而是把 KV cache 切分成固定大小的内存块(类似内存页):
# 来自 core/block.py
@dataclass
class Block:
"""固定大小的 KV cache 内存块
每个块存储 block_size 个 token 的 KV 状态
"""
block_id: int
block_size: int = 16 # 每块 16 个 token
ref_count: int = 1 # 用于共享(前缀缓存)
prefix_hash: Optional[int] = None
每个序列获得一个 BlockTable——从逻辑位置到物理块的映射表:
# 来自 core/block.py
@dataclass
class BlockTable:
"""将逻辑位置映射到物理块
类似虚拟内存中的页表:
- 位置 p 的 token 在逻辑块:p // block_size
- 块内槽位:p % block_size
- 物理块:block_ids[p // block_size]
示例(block_size=16,序列有 35 个 token):
block_table.block_ids = [5, 12, 3] # 3 个物理块
Token 0-15 -> 块 5
Token 16-31 -> 块 12
Token 32-34 -> 块 3(槽位 0-2)
"""
block_ids: List[int]
block_size: int = 16
BlockManager 负责分配管理,就像 OS 管理内存一样:
# 来自 core/block_manager.py
class BlockManager:
"""管理 KV cache 块的分配
使用简单的空闲列表(栈)实现 O(1) 分配/释放
"""
def allocate_block(self) -> int:
if not self.free_blocks:
raise RuntimeError("KV cache 块用尽!")
return self.free_blocks.pop()
def free_block(self, block_id: int) -> None:
block = self.blocks[block_id]
if block.decrement_ref() <= 0:
self.free_blocks.append(block_id)
Paged Attention 的计算过程
计算注意力时,需要从不连续的块中收集 K 和 V:
# 来自 attention/paged_attention.py
def paged_attention(
query: torch.Tensor,
key_cache: torch.Tensor, # [num_blocks, block_size, num_kv_heads, head_dim]
value_cache: torch.Tensor,
block_tables: List[BlockTable],
context_lens: List[int],
block_size: int,
num_kv_heads: int,
) -> torch.Tensor:
# 为每个序列从块中收集数据
for batch_idx in range(batch_size):
block_table = block_tables[batch_idx]
for pos in range(context_len):
logical_block = pos // block_size
slot_in_block = pos % block_size
physical_block = block_table.block_ids[logical_block]
# 从缓存中复制
gathered_keys[batch_idx, :, pos, :] = key_cache[physical_block, slot_in_block]
gathered_values[batch_idx, :, pos, :] = value_cache[physical_block, slot_in_block]
# 标准注意力计算
attn_weights = torch.matmul(query, gathered_keys.transpose(-2, -1)) * scale
# ... 应用 mask、softmax 并计算输出
为什么 PagedAttention 如此重要
PagedAttention 带来的好处:
- 接近零显存浪费:只分配实际需要的空间
- 内存共享:相同前缀可以共享块(前缀缓存)
- 更高吞吐量:显存能容纳更多请求,实现更高并行度
连续批处理:告别空闲等待
传统批处理的问题
传统批处理要等待批次中所有序列都完成才能开始新请求。假设有:
- 请求 A:需要生成 50 个 token
- 请求 B:只需生成 5 个 token
请求 B 很快完成,但必须等待请求 A。GPU 只能闲置!
连续批处理的解决方案
nano-vllm 以迭代粒度进行调度:
- 新请求可以中途加入批次
- 完成的请求立即离开
- GPU 保持忙碌状态
调度器的实际运行过程:
# 来自 core/scheduler.py
class Scheduler:
"""管理序列的生命周期:
- WAITING:排队中
- RUNNING:处理中
- SWAPPED:被抢占
- FINISHED:已完成
"""
def schedule(self) -> SchedulerOutputs:
outputs = SchedulerOutputs()
# 1. 如果有高优先级请求等待,处理抢占
if self.enable_preemption and self.block_manager:
self._handle_preemption(outputs)
# 2. 继续运行中的序列(decode)
for seq in self.running:
if seq.is_chunked_prefill():
outputs.chunked_prefill_sequences.append(seq)
else:
outputs.decode_sequences.append(seq)
# 3. 从等待队列接纳新序列
while can_admit_more():
seq = self._pop_waiting()
seq.status = SequenceStatus.RUNNING
outputs.prefill_sequences.append(seq)
return outputs
引擎在一次迭代中处理这些序列:
# 来自 engine.py
def step(self) -> List[GenerationOutput]:
"""连续批处理的一次迭代"""
scheduler_outputs = self.scheduler.schedule()
# 处理分块 prefill
for seq, num_tokens in zip(chunked_prefill_seqs, chunked_prefill_tokens):
self._run_chunked_prefill(seq, num_tokens)
# 处理完整 prefill(新序列)
for seq in prefill_sequences:
self._run_prefill(seq)
# 处理 decode(批量一起处理!)
if decode_sequences:
self._run_decode(decode_sequences)
# 返回完成的序列
return newly_finished
优先级调度与抢占机制
有时某些请求需要 VIP 待遇。nano-vllm 支持以下特性:
基于优先级的调度
请求带有优先级属性,优先级高的先处理:
# 来自 core/scheduler.py
def _get_priority_key(self, seq: Sequence) -> Tuple[int, float, int]:
"""堆排序的优先级键。元组值越小,优先级越高"""
# 取反优先级,让高值排在前面
return (-seq.priority, seq.arrival_time, seq.seq_id)
# 使用堆实现 O(log n) 调度
heapq.heappush(self._waiting_heap, (priority_key, sequence))
抢占:踢出低优先级请求
当高优先级请求到来但显存不足时,可以抢占低优先级的运行中请求:
# 来自 core/scheduler.py
def _handle_preemption(self, outputs):
"""为高优先级等待序列抢占低优先级序列"""
highest_waiting = self._peek_waiting()
while not self.block_manager.can_allocate(blocks_needed) and self.running:
# 找到优先级最低的运行序列
lowest_running = min(self.running, key=lambda s: s.priority)
if highest_waiting.priority > lowest_running.priority:
# 抢占!释放块并重置以便重新计算
self.running.remove(lowest_running)
self.block_manager.free_sequence_blocks(lowest_running.block_table)
lowest_running.reset_for_recompute()
self._push_waiting(lowest_running)
被抢占的序列回到等待队列,稍后会重新进行 prefill。这是基于重计算的抢占(相比交换到 CPU 内存),实现更简单,实践中效果也不错。
前缀缓存:共享通用前缀
许多请求的开头都是相同的系统提示词。为什么要重复计算相同的 KV cache?
工作原理
块根据 token 内容和在序列中的位置进行哈希:
# 来自 core/block.py
def hash_token_block(token_ids: Tuple[int, ...], parent_hash: Optional[int] = None) -> int:
"""包含整个前缀链的累积哈希
这确保只有在整个前缀匹配时才共享块
"""
if parent_hash is None:
return hash(token_ids)
return hash((parent_hash, token_ids))
新序列到来时,检查其前缀块是否已存在:
# 来自 core/block_manager.py
def allocate_blocks_with_prefix_caching(self, token_ids: List[int]):
"""分配块,尽可能复用缓存的前缀块"""
parent_hash = None
for block_idx in range(num_full_blocks):
block_tokens = tuple(token_ids[start:end])
cache_key = (parent_hash, block_tokens)
if cache_key in self.prefix_cache:
# 缓存命中!复用现有块
cached_block_id = self.prefix_cache[cache_key]
self.blocks[cached_block_id].increment_ref() # 引用计数
block_table.append_block(cached_block_id)
else:
# 缓存未命中 - 分配新块
block_id = self.allocate_block()
self.prefix_cache[cache_key] = block_id
block_table.append_block(block_id)
parent_hash = self.blocks[block_id].prefix_hash
return block_table, shared_prefix_len
引用计数确保块在仍被其他序列使用时不会被释放。
分块 Prefill:避免长 Prompt 阻塞
一个很长的 prompt(比如 4000 tokens)在 prefill 时会阻塞整个批次。分块 prefill 将其拆分成更小的片段:
# 来自 engine.py
def _run_chunked_prefill_paged(self, seq: Sequence, num_tokens: int):
"""处理一块 prompt tokens"""
start_pos = seq.num_prefilled_tokens
end_pos = start_pos + num_tokens
chunk_tokens = seq.prompt_token_ids[start_pos:end_pos]
# 为这一块分配块
# ...
# 只对这一块进行前向传播
logits = self.model(input_ids, block_kv_cache=..., start_positions=[start_pos])
# 更新进度
seq.num_prefilled_tokens = end_pos
# 只有在所有 prompt tokens 都处理完后才采样
if seq.num_prefilled_tokens >= len(seq.prompt_token_ids):
next_token = self.sampler.sample(logits)
seq.append_token(next_token.item())
调度器控制每次迭代 prefill 多少 token:
# max_prefill_tokens 限制每次迭代的计算量
if prompt_len <= prefill_budget:
outputs.prefill_sequences.append(seq) # 完整 prefill
else:
outputs.chunked_prefill_sequences.append(seq) # 部分 prefill
outputs.chunked_prefill_tokens.append(prefill_budget)
FlashAttention:高效的注意力计算
标准注意力会具化完整的 N×N 注意力矩阵。对于 2048 token 的序列,那就是 400 万个元素!FlashAttention 使用分块技术避免这个问题。
在 nano-vllm 中的集成
# 来自 attention/flash_attention.py
def flash_attention(query, key, value, causal=True):
"""使用 FlashAttention,显存复杂度 O(N) 而非 O(N^2)"""
# FlashAttention 期望:[batch, seq_len, num_heads, head_dim]
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
output = flash_attn_func(query, key, value, causal=causal)
return output.transpose(1, 2)
# 统一接口,带降级方案
def attention(query, key, value, use_flash_attn=True, causal=True):
if use_flash_attn and FLASH_ATTN_AVAILABLE:
return flash_attention(query, key, value, causal)
# 降级到 PyTorch SDPA(也是优化过的!)
return F.scaled_dot_product_attention(query, key, value, is_causal=causal)
FlashAttention 在模型的注意力层中使用:
# 来自 model/llama.py
class LlamaAttention(nn.Module):
def __init__(self, config, layer_idx, use_flash_attn=True):
self.use_flash_attn = use_flash_attn and is_flash_attn_available()
def forward(self, hidden_states, ...):
# ... 计算 Q、K、V 并应用 RoPE ...
# 使用统一注意力接口(如可用则用 FlashAttention)
attn_output = unified_attention(
query=query_states,
key=key_states,
value=value_states,
use_flash_attn=self.use_flash_attn,
causal=True,
)
推测解码:草稿与验证
Decode 很慢,因为一次只生成一个 token。如果能在大模型的一次前向传播中生成多个 token 呢?
核心思路
- 使用小而快的草稿模型生成 K 个候选 token
- 大模型验证所有 K+1 个位置,只需一次前向传播
- 接受匹配的 token,拒绝不匹配的并重新采样
# 来自 speculative/speculative_decoding.py
def _speculative_step(self, current_ids, target_kv_cache, draft_kv_cache, remaining_tokens):
"""一次推测解码步骤"""
K = self.config.num_speculative_tokens
# 步骤 1:生成 K 个草稿 token(快速!)
draft_tokens, draft_probs = self._generate_draft_tokens(current_ids, draft_kv_cache, K)
# 步骤 2:用目标模型验证(一次前向传播处理 K+1 个 token!)
verify_ids = [[current_ids[-1]] + draft_tokens]
target_logits = self.target_model(verify_ids, kv_cache=target_kv_cache)
target_probs = F.softmax(target_logits, dim=-1)
# 步骤 3:使用拒绝采样接受/拒绝
accepted_tokens = []
for i, draft_token in enumerate(draft_tokens):
target_prob = target_probs[0, i, draft_token].item()
draft_prob = draft_probs[i]
# 如果目标概率 >= 草稿概率则接受(保持目标分布!)
acceptance_prob = min(1.0, target_prob / draft_prob)
if random() < acceptance_prob:
accepted_tokens.append(draft_token)
else:
# 从调整后的分布重新采样
resampled = sample_from_adjusted(target_probs[0, i], draft_prob, draft_token)
accepted_tokens.append(resampled)
break # 第一次拒绝后停止
# 如果全部接受,再采样一个额外 token!
if len(accepted_tokens) == len(draft_tokens):
bonus_token = sample(target_probs[0, -1])
accepted_tokens.append(bonus_token)
return accepted_tokens
神奇之处:无质量损失
这是拒绝采样——数学上保证输出分布与目标模型完全相同。没有任何近似!
加速效果取决于:
- 草稿模型速度(应该比目标模型快约 10 倍)
- 接受率(越高表示每次目标前向传播获得更多 token)
- K 值(更多推测 = 更大潜在收益)
Llama 模型的完整实现
nano-vllm 包含从头编写的 Llama 实现,具备所有现代特性:
RMSNorm(替代 LayerNorm)
# 来自 model/llama.py
class RMSNorm(nn.Module):
"""均方根归一化 - 比 LayerNorm 更简单"""
def forward(self, x):
rms = torch.sqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
return x / rms * self.weight
旋转位置编码(RoPE)
# 来自 model/llama.py
def apply_rotary_pos_emb(q, k, cos, sin):
"""通过旋转 Q 和 K 向量来编码位置
旋转公式:q_rotated = q * cos + rotate_half(q) * sin
这让模型能通过点积学习相对位置
"""
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
分组查询注意力(GQA)
# 来自 model/llama.py
class LlamaAttention(nn.Module):
"""GQA:KV head 数量少于 Q head,节省显存"""
def __init__(self, config):
self.num_heads = config.num_attention_heads # 例如 32
self.num_kv_heads = config.num_key_value_heads # 例如 8
self.num_kv_groups = self.num_heads // self.num_kv_heads # = 4
# Q 投影比 K、V 投影更大
self.q_proj = nn.Linear(hidden, num_heads * head_dim)
self.k_proj = nn.Linear(hidden, num_kv_heads * head_dim) # 更小!
self.v_proj = nn.Linear(hidden, num_kv_heads * head_dim)
SwiGLU MLP
# 来自 model/llama.py
class LlamaMLP(nn.Module):
"""SwiGLU:output = down(silu(gate(x)) * up(x))"""
def forward(self, x):
gate = F.silu(self.gate_proj(x)) # Swish 激活
up = self.up_proj(x)
return self.down_proj(gate * up) # 门控线性单元
教学模式:边看边学
这是最有意思的特性之一!nano-vllm 包含多种教学模式,解释推理过程中发生的事情:
解说模式
提供白话解说,就像专家带着观看手术:
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "The capital of France is" --narrate
输出示例:
═══════════════════════════════════════════════════════════════════
推理剖析 - 教学模式
═══════════════════════════════════════════════════════════════════
Prompt: "The capital of France is"
Model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
═════ 第一幕:分词 ═════
将 prompt 转换为模型能理解的数字...
"The capital of France is"
↓ 分词器(BPE 算法)
[The] [capital] [of] [France] [is] → [450, 7483, 310, 3444, 338]
═════ 第二幕:PREFILL 阶段 ═════
模型一次性读取整个 prompt...
通过 22 层处理 5 个 token
✓ 并行计算(所有 token 一起处理)
✓ 构建 KV cache
═════ 第三幕:DECODE 阶段 ═════
现在逐个生成 token...
步骤 1:预测第 6 个 token
│ 前 5 个预测:
│ Paris ████████████████████ 82.3%
│ the ███ 7.1%
│ located ██ 4.2%
└── 采样:「Paris」(82.3%)
X-Ray 模式
显示张量形状和数学运算:
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "Hello" --xray
仪表盘模式
实时终端界面显示进度(需要 rich 库):
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "Hello" --dashboard
交互式教程
逐步学习体验:
python -m nano_vllm.cli --tutorial
快速上手
安装
pip install -e .
# 可选:FlashAttention(加速推理)
pip install flash-attn --no-build-isolation
基本使用
# 单条 prompt
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "Hello, world"
# 多条 prompt(连续批处理)
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "The capital of France is" \
--prompt "The largest planet is" \
--prompt "Python is a"
# 优先级调度
python -m nano_vllm.cli --model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "Low priority task" --priority 1 \
--prompt "High priority task" --priority 10
# 推测解码
python -m nano_vllm.speculative.cli \
--target-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--draft-model TinyLlama/TinyLlama-1.1B-Chat-v1.0 \
--prompt "The future of AI is" \
--num-speculative-tokens 5
Python API
from nano_vllm.engine import LLMEngine
engine = LLMEngine(
model_path="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
use_paged_attention=True,
enable_prefix_caching=True,
use_flash_attn=True,
)
# 单条生成
output = engine.generate("What is machine learning?", max_tokens=100)
# 带优先级的批量生成
engine.add_request("Prompt 1", max_tokens=50, priority=1)
engine.add_request("Prompt 2", max_tokens=50, priority=10) # 更高优先级
outputs = engine.run_to_completion()
核心收获
构建 nano-vllm 带来的几点领悟:
显存是瓶颈:大多数 LLM 推理优化都在解决显存问题,而非计算问题。
OS 概念的应用:PagedAttention 本质上就是 KV cache 的虚拟内存。
批处理的复杂性:连续批处理远比简单地"把东西放进批次"复杂得多。
推测的威力:在昂贵的前向传播中获得多个 token 带来巨大收益。
细节决定成败:因果掩码、位置 ID、引用计数……无穷无尽的边界情况。
参考资料

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)