后段面试速成八股文
硬件加速:TLB(Translation Lookaside Buffer)由于页表查询(尤其是多级页表)需要多次访问内存,会降低效率,CPU 通过 “TLB”(页表缓存)存储近期使用的虚拟地址→物理地址映射。硬件层面,CPU 中的 “内存管理单元(MMU)” 负责实时将虚拟地址转换为物理地址,转换时会查询当前进程的页表(进程切换时,操作系统会更新 MMU 使用的页表指针)。进程的虚拟地址到物理地
文章目录
-
-
- 程序的内存分区
- 尤其区分好堆栈
- b和b+树
- 聚集索引和非聚集索引
- 为什么MySQL索引使用B+树而不用hash表和B树
- TCP和UDP的使用场景
- 滑动窗口
- tcp是如何保证可靠的
- 流量控制
- 三次握手
- 四次挥手
- inodb和myisam
- b和b+树
- 握手的时候可以传输数据吗
- 操作系统中如何实现进程的内存空间独立的
- 虚拟地址和物理地址是如何进行映射的
- 是怎么进行进程的调度
- 进程如何进行通信
- 了解http的格式吗
- get和post在参数上有啥区别
- atps和atpp
- 输入一个网址,会发生什么事情?
- new和malloc的区别
- c++中如何避免内存泄漏
- 智能指针
- 多线程中c++中的锁
- 多进程和多线程
- 线程和进程的区别
-
程序的内存分区
内存分区,分别是堆、栈、自由存储区、全局/静态存储区、常量存储区和代码区
CPU 指令里有专门负责栈内存分配的指令,硬件直接支持,效率高

尤其区分好堆栈
b和b+树
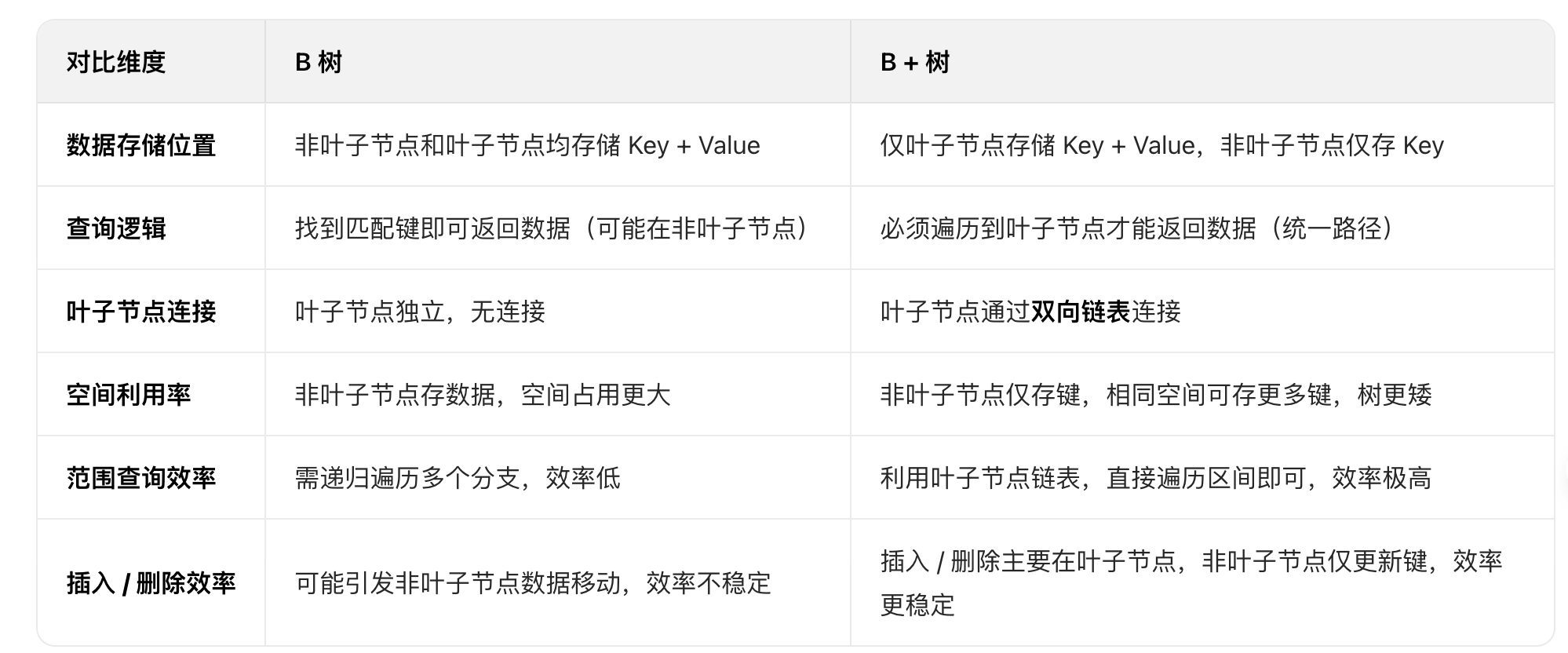
聚集索引和非聚集索引

为什么MySQL索引使用B+树而不用hash表和B树
(内存 --> hash 表)
(范围查找

TCP和UDP的使用场景
tcp是全双工
TCP协议可靠性较高,适用于数据传输的可靠性要求较高的场景,例如传输大文件或需要确保所有数据都能到达接收端的应用,如FTP、HTTP等应用程序。
而UDP协议则适用于对实时性要求较高的场景,例如音视频流媒体、在线游戏等

滑动窗口

tcp是如何保证可靠的

流量控制
三次握手
四次挥手
inodb和myisam

b和b+树
B-tree(B树)
结构特点
所有节点都可以存储数据:每个节点可以包含多个键值对,并且每个键值对对应一个子节点。
每个节点的子节点数量与其键的数量相关:一个节点如果有 n 个键,则有 n+1 个子节点。
叶子节点位于同一层:所有叶子节点都在同一层,确保了树的高度平衡。
搜索、插入和删除操作的时间复杂度为 O(log n) :由于树的高度较低,这些操作非常高效。
使用场景
数据库索引:B树适用于需要频繁进行范围查询和顺序访问的场景,如关系型数据库中的索引。
文件系统:B树在文件系统中用于管理文件和目录的索引,确保快速访问。
B+tree(B+树)
结构特点
只有叶子节点存储数据:内部节点只存储键,不存储数据,所有数据都存储在叶子节点中。
叶子节点之间通过指针相连:形成一个链表,便于范围查询和顺序访问。
每个节点的子节点数量与其键的数量相同:一个节点如果有 n 个键,则有 n 个子节点。
搜索、插入和删除操作的时间复杂度为 O(log n) :与B树相同,但由于数据集中在叶子节点,某些操作可能更高效。
使用场景
数据库索引:B+树特别适合用于需要频繁进行范围查询和顺序访问的场景,如关系型数据库中的索引。
文件系统:B+树在文件系统中用于管理文件和目录的索引,确保快速访问和顺序遍历。
作者:Echo8713
链接:https://juejin.cn/post/7466051143169687571
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
握手的时候可以传输数据吗
操作系统中如何实现进程的内存空间独立的
通过 “虚拟内存” 技术实现进程内存隔离,核心是让每个进程拥有独立的 “虚拟地址空间”,与物理内存地址解耦
进程的虚拟地址到物理地址的映射关系,通过 “页表”(Page Table)维护,每个进程有独立的页表(由操作系统内核管理)。
硬件层面,CPU 中的 “内存管理单元(MMU)” 负责实时将虚拟地址转换为物理地址,转换时会查询当前进程的页表(进程切换时,操作系统会更新 MMU 使用的页表指针)。
虚拟地址和物理地址是如何进行映射的
普遍使用多级页表(而非单级页表),以减少内存开销(单级页表在 64 位系统中会占用大量内存)。
虚拟地址被拆分为多个段,每段对应一级页表的索引。例如,64 位系统的虚拟地址可能拆分为:
[PML4索引][PDPT索引][PD索引][PT索引][页内偏移]
通过不断的查询,加载,最后得到即虚拟页对应的物理页的基地址。将 “物理页框号” 与虚拟地址的 “页内偏移” 拼接,得到最终的物理地址
还有硬件加速:
硬件加速:TLB(Translation Lookaside Buffer)由于页表查询(尤其是多级页表)需要多次访问内存,会降低效率,CPU 通过 “TLB”(页表缓存)存储近期使用的虚拟地址→物理地址映射。
当 MMU 转换地址时,先查 TLB:若命中(缓存中有映射),直接返回物理地址;若未命中,再执行完整的页表查询,并将结果存入 TLB。
是怎么进行进程的调度
进程状态:调度围绕进程状态转换展开,关键状态包括:
就绪态(Ready):进程已就绪,等待 CPU 分配;
运行态(Running):进程正在占用 CPU 执行;
阻塞态(Blocked):进程因等待资源(如 IO、锁)暂停,不参与调度。
调度策略
- 先来先服务(FCFS):
原理:按进程到达就绪队列的顺序调度,非抢占式(一旦占用 CPU 则运行至结束或阻塞)。
特点:实现简单,但对短进程不友好(长进程会阻塞短进程)。
适用场景:早期批处理系统,或对公平性要求高的场景。 - 短作业优先(SJF):
原理:优先调度估计运行时间最短的进程,分抢占式(有更短进程到达时抢占 CPU)和非抢占式。
特点:理论上平均等待时间最短,但需预估运行时间(实际中难精确),可能导致长进程 “饥饿”。
适用场景:可预估运行时间的批处理任务(如计算型任务)。 - 时间片轮转(RR):
原理:为每个进程分配固定时间片(如 10ms),时间片用完后切换到下一个进程(抢占式)。
特点:响应快,公平性好,时间片大小影响性能(太小导致切换频繁,太大退化为 FCFS)。
适用场景:交互式系统(如桌面、服务器),是分时系统的核心策略。 - 优先级调度:
原理:为进程分配优先级,高优先级进程优先调度,支持抢占(高优先级进程到达时抢占低优先级进程)。
特点:灵活,可按任务重要性调整(如内核进程优先级高于用户进程),但需避免低优先级进程 “饥饿”(可动态提升长期等待进程的优先级)。
适用场景:实时系统、多任务服务器(如区分核心服务和普通任务)
进程如何进行通信

了解http的格式吗

get和post在参数上有啥区别
请求体和响应体
atps和atpp
输入一个网址,会发生什么事情?

new和malloc的区别
malloc仅分配内存,不会调用构造函数(对自定义类型而言,分配的内存中对象未初始化)。
new在分配内存后,会自动调用对应类型的构造函数(如new MyClass(10)会调用MyClass的带参构造函数)。
对应地,释放内存时:free仅释放内存,不调用析构函数;delete会先调用对象的析构函数,再释放内存。
malloc需要显式指定分配的字节数(如malloc(100)分配 100 字节),返回void*,使用时需强制类型转换。
new根据目标类型自动计算所需内存大小(如new int分配 4 字节,new MyClass分配sizeof(MyClass)字节),返回类型指针(如int*、MyClass*),无需转换。
c++中如何避免内存泄漏
智能指针

unique_ptr:独占所有权的智能指针
同一时间只能有一个unique_ptr管理某块内存(独占所有权),不支持拷贝(防止多个指针释放同一块内存),但支持移动(转移所有权)。
shared_ptr:共享所有权的智能指针
多个shared_ptr可同时管理同一块内存(共享所有权),通过引用计数跟踪引用该内存的指针数量。当最后一个shared_ptr销毁时,才释放内存。
weak_ptr:弱引用智能指针
不拥有内存所有权,仅作为shared_ptr的 “观察者”,不增加引用计数。用于解决shared_ptr的循环引用问题(两个shared_ptr互相引用导致引用计数无法归零,内存泄漏)

多线程中c++中的锁
互斥锁(Mutex):最基础的排他锁
互斥锁确保同一时间只有一个线程能访问共享资源,是最常用的同步手段
lock_guard自动管理锁的生命周期
简单的锁包装器,构造时自动lock(),析构时自动unlock(),生命周期与作用域绑定
条件变量。 用于线程间的 “等待 - 通知” 协作,让线程在满足特定条件前阻塞等待,避免无效的轮询消耗 CPU 资源,通常与互斥锁配合使用。
自旋锁是一种特殊的锁机制:当线程获取锁失败时,不会阻塞睡眠,而是循环重试(“自旋”),直到成功获取锁。
多进程和多线程

线程和进程的区别


昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)