《Nature Electronics》重磅:北大团队首创存算一体新架构,颠覆传统AI排序
北京大学研究团队在《Nature Electronics》发表了一项基于忆阻器的存算一体排序架构创新成果。该研究突破了传统排序算法在CPU/GPU上的性能瓶颈,提出"就地排序"理念,通过三项核心技术实现突破:1) 数字读取技术消除物理比较器依赖;2) 树节点跳过技术实现智能剪枝优化;3) 跨阵列并行策略增强可扩展性。实验显示,该架构在速度、面积效率和能源效率上分别提升7.7倍、
导语
在人工智能驱动的时代,信息密度进一步增加,排序算法在信息相关研究中依然具有重要地位。从自动驾驶汽车判断行人优先级,到大语言模型在库中筛选相关token,AI算法依旧离不开排序操作。不同于AI算法的日新月异,排序算法却逐渐成为制约AI系统性能进一步飞跃的瓶颈。今天我们将要解读的是来自北京大学的一项成果,研究人员设计了一种基于忆阻器的存算一体高效排序硬件架构,绕开了排序算法被简单打入CPU的性能壁垒,为AI硬件加速领域开辟了新方向。该成果发表于国际顶尖期刊 《Nature Electronics》。
一、排序:AI时代为何绕不开的性能瓶瓶颈
排序本质上是为信息建立“优先级”的过程。排序算法决定了购物网站或短视频App上推流的内容,也使得路径规划算法可以考虑不同路径的成本,以找出最优路线。在目前神经网络中常见的剪枝操作中,需要排序网络权重并剔除“贡献最小”的连接,以此压缩模型体积,并提高处理效率。而排序算法的效率直接影响剪枝,也会关联到AI应用的响应速度与最终效果。
深入排序算法的内核,其逻辑可以归结为两个算子:对比(Comparison)与重排(Data Reordering)。当数据量达到数十亿甚至数万亿级别时,反复的对比与重排会大大超出硬件的处理能力。在传统架构下数据存储在Memory中,对比操作在CPU/GPU的比较单元(Comparison Units)中实现,执行每一次重排都需要数据在存储与计算单元之间的往返。为了提升排序速度,硬件设计者往往选择在芯片上集成多个并行的比较器电路形成庞大的比较器阵列。
存算一体技术(CIM)通过在存储单元内部执行计算,直接消除了数据搬运,解决了大部分原有的问题。然而,排序的逻辑if A > B, then swap是非线性的条件判断与选择逻辑。想要在规整、追求密度的硬件结构的CIM阵列中实现非线性逻辑仍然比较困难。以往的存内排序(Sort-in-Memory, SIM)方案,往往是依赖片上大量的比较器,或是手动构建复杂的忆阻器逻辑门网络,这在一定程度上又回到了传统架构的老路,并未从根本上解决问题。因此,如何设计一种无需比较器、且能原生于存储阵列的排序方案,成为了SIM发展的前置问题。
- 存算一体如何实现“就地排序”?
- 核心理念:让数据“就地排序”
该研究的基石,是彻底抛弃冯诺依曼架构下“存储-计算”分离的传统思路。研究团队敏锐地指出,排序任务的性能瓶颈并非来自计算本身,而是源于海量数据在物理空间上的低效往返移动。
基于这一洞察,团队提出的“第一性原理”是:计算应该发生在数据所在的地方,而非数据被搬运到计算发生的地方。 他们利用忆阻器这种新型非易失性存储器件,构建了一个计算与存储高度融合的阵列。忆阻器不仅能存储数据,其物理特性还天然具备执行计算的潜力。通过在忆阻器阵列内部直接嵌入逻辑判断与筛选能力,数据在整个排序过程中无需离开存储介质,实现了真正意义上的“就地排序”。这种设计从根本上消除了数据总线的拥堵,规避了因数据搬运产生的延迟和功耗,为实现性能的指数级提升奠定了坚实的理论基础。
- 实现性能飞跃的技术三连跳
第一跳:颠覆性的“数字读取”(Digital Read)—— 告别比较器
传统排序算法的灵魂在于“比较与交换”。为此,硬件系统需要集成成千上万个专门的比较器电路,这些电路不仅是芯片面积的“消耗大户”,也是主要的功耗来源。该研究的第一项颠覆性创新,就是设计了一种无需物理比较器的排序机制,即“数字读取”(Digit Read, DR)。
其工作原理精巧而高效:首先,所有待排序的数据以二进制形式(高阻态为'0',低阻态为'1')写入“单晶体管-单忆阻器”(1T1R)阵列中。在排序时,系统并非像传统方法那样,取出两个完整的数字(例如A和B)进行比较,而是利用忆阻器阵列的并行特性,在一个时钟周期内,同时对所有待排序数字的同一个数据位施加读取电压。例如,系统可以一次性读取阵列中所有数字的最高有效位(Most Significant Bit, MSB)。
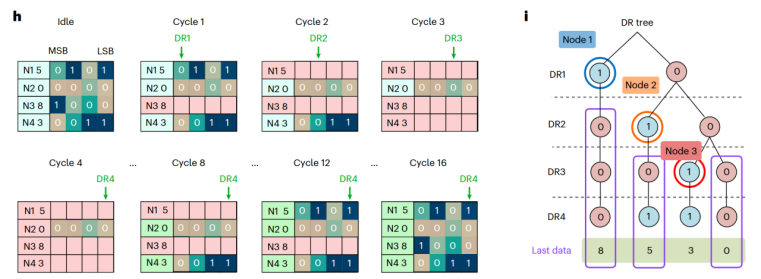
图1无符号4bit数的排序
通过分析这次并行读取的结果,系统可以立即做出判断。如图1所示,比如,在寻找最小值时,所有MSB为'0'的数字,其数值必然小于所有MSB为'1'的数字。因此,所有MSB为'1'的数字可以在这一步被直接排除。接下来,系统仅在上一轮胜出的数字(MSB为'0'的组)中,继续读取下一位,如此迭代,直至最低有效位(Least Significant Bit, LSB)。这个过程,本质上是将排序问题转化为在一棵虚拟的“数字决策树”上进行高效的遍历搜索,彻底绕开了物理比较操作,从而根除了对比较器的依赖。
第二跳:加速的秘诀“树节点跳过”(Tree Node Skipping)—— 智能剪枝
虽然“数字读取”机制已经极具革命性,但朴素的逐位遍历(论文中称为BTS)仍然存在大量可优化的冗余步骤。想象一下,如果一个数据集中大量数字都拥有相同的前几位(例如很多数字都以一长串'0'开头),那么在寻找最小值时,对这些相同前缀位的重复读取就是一种时间的浪费。
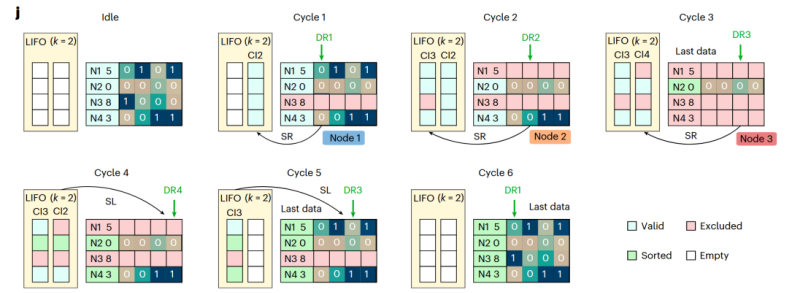
图2 使用TNS的排序
如图2所示,为了解决这一问题,团队开发了更为智能的 “树节点跳过”(Tree Node Skipping, TNS) 技术。这可以被生动地比喻为对决策树进行“智能剪枝”。TNS技术的核心是动态地识别并记录决策树中的关键“分叉节点”——即在某一位上,待选数字中同时出现了'0'和'1'的位置。系统通过一个后进先出(LIFO)的硬件模块来存储这些关键节点的状态。
当系统完成一轮最小值(或最大值)的寻找后,在开始下一轮寻找时,它无需再从树根(MSB)开始遍历。相反,它可以直接从LIFO中调出最近记录的分叉点状态,直接“跳过”所有之前已经遍历过的、不存在分叉的共同路径,从那个关键的分叉点继续搜索。这种“抄近道”的方式,极大地压缩了不必要的读取周期。
第三跳:强大的“跨阵列并行”(Cross-Array Parallelism)—— 构筑可扩展性
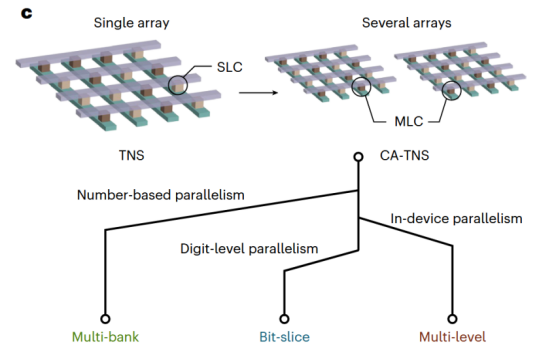
图3 从TNS到CA-TNS的演变
单一阵列的排序能力终究有限,为了让该架构能够从容应对现实世界中规模庞大、精度复杂的海量数据,团队将TNS技术进一步扩展,设计了三种互补的 “跨阵列树节点跳过”(CA-TNS) 并行策略,赋予了系统强大的可扩展能力,如图3所示。
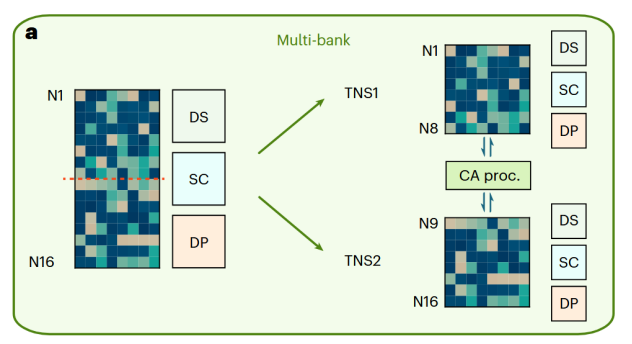
图4 多存储体并行
多存储体并行(Multi-bank, MB):如图4所示,这是一种基于数据量的横向扩展策略。它将海量数据依据数量,物理地分割到多个独立的忆阻器存储体中。每个存储体都配备独立的控制电路,作为一个子排序器并行运行,并通过一个全局的跨阵列处理器进行状态同步。这种“分而治之”的模式,有效解决了因阵列规模过大导致的寄生电阻电容效应,并使得系统能够处理几乎无限数量的数据。
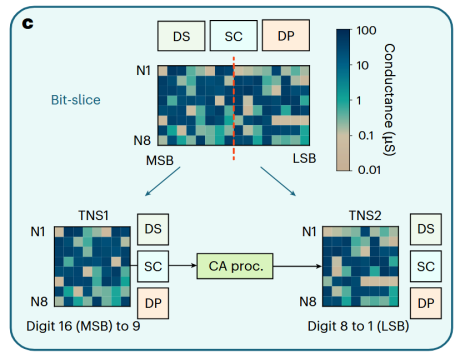
图5位切片并行
位切片并行(Bit-slice, BS):如图5所示,这是一种基于数据精度的纵向扩展策略。它将一个高精度的数据(如32位浮点数)的比特位进行切片,例如高位部分和低位部分被存储在不同的物理阵列中。在排序时,高位阵列首先进行初步筛选,其结果(例如,确定了多个拥有相同高位的候选数)将直接作为下一级低位阵列的输入,形成一种高效的流水线式并行处理。这使得系统能够高效处理任意精度的数据类型。
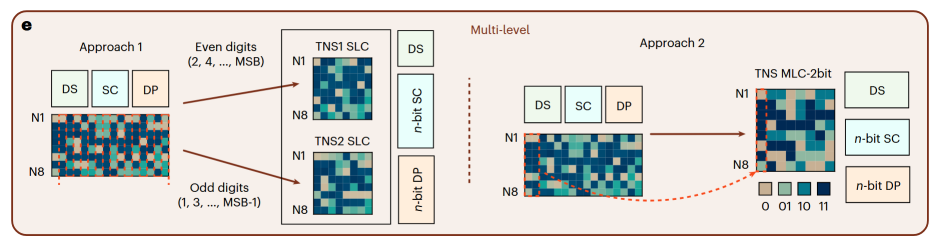
图6多能级并行
多能级并行(Multi-level, ML):如图6所示,这是一种基于器件物理特性的深度并行。它充分利用了忆阻器单个器件即可稳定存储多个比特信息(Multi-Level Cell, MLC)的独特优势。例如,一个能存储3比特(8个能级)的忆阻器,其一次读取操作获得的信息量就是传统二进制器件的三倍。这意味着,完成同样精度的排序,所需的读取周期数可以成倍减少,同时数据存储密度也大幅提升,实现了“器件内并行”。
- 实验数据
理论的先进性最终通过惊艳的实测数据得到了验证。与目前先进的、采用更先进制程的专用集成电路(ASIC)排序系统相比,该忆阻器存算一体系统在多个关键指标上实现了碾压性优势。它不仅将 速度(吞吐率) 提升了高达7.7倍,更在效率上实现了质的飞跃:其面积效率提升了32.46倍,意味着在相同的芯片面积上能集成更多的排序单元以实现更强的计算能力;而能源效率的提升更是达到了惊人的160.4倍,意味着完成相同的排序任务,该系统的功耗仅为传统ASIC的约0.6%。
- 从实验室到现实:存算一体排序的实测效果与应用蓝图
一项颠覆性技术的真正价值,最终要由其在真实世界中的表现来检验。该研究通过两个前沿应用场景的实证,清晰地展示了这套存算一体排序架构的强大威力及其广阔的应用蓝图。
实证一:为图计算“导航”,实现路径极速搜索
第一个实证场景聚焦于图计算中的核心难题——最短路径搜索。研究团队将经典的Dijkstra算法应用于一个包含16个站点的北京地铁网络模型中,如论文图7a所示。该算法的瓶颈在于,每一步都需要对所有相邻站点的距离进行快速排序,以找出当前最短路径。实验中,这些距离被编码为复杂的16位浮点数,并映射到忆阻器阵列的电导状态上,其分布如图7b所示。测试结果令人瞩目:与专门用于排序的ASIC硬件相比,该存算一体架构的能效提升了惊人的610倍,吞吐率也提高了2.43倍。这一成功验证不仅证明了该架构处理复杂浮点运算的能力,更预示着它能直接为大规模路径规划(如智能导航、物流调度)、社交网络分析以及金融风控等图计算领域的核心难题提供前所未有的算力支持。
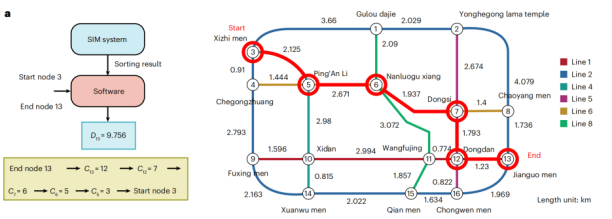
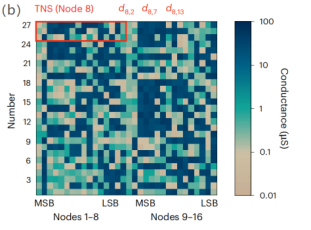
图7 (a) 用于Dijkstra算法测试的16个北京地铁站网络图 (b)存储了16个站点所有邻近距离的忆阻器电导分布图
实证二:为AI模型“瘦身”,实现神经网络实时加速
第二个实证场景则瞄准了AI推理的效率瓶颈。研究团队将该排序系统与主流的存内计算模块集成,在PointNet++神经网络中实现了运行时可调的稀疏化(In-situ Pruning)。这项技术允许AI模型在推理过程中,实时找出并“忽略”掉绝对值最小、贡献度最低的权重参数,从而为模型动态“瘦身”以实现加速。如图8所示,排序模块首先对存储在阵列中的权重(如图8的分布示例)进行快速排序,识别出最不重要的部分并将其屏蔽,随后核心计算模块再执行推理。这种“排序+计算”的协同模式效果显著,使神经网络的推理响应速度提升了70%以上,排序吞吐率更是达到了传统专用硬件的5.17倍。这项实验有力地证明了该技术与其他存内计算方案的强大兼容性,是实现高效端侧AI的关键,能让大模型在自动驾驶、AR/VR、智能机器人等对实时性要求极高的边缘设备上运行得更快、更省电。
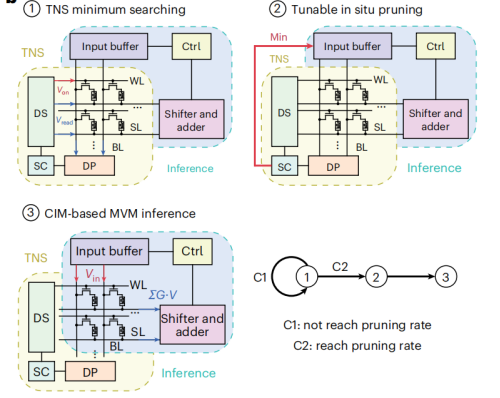
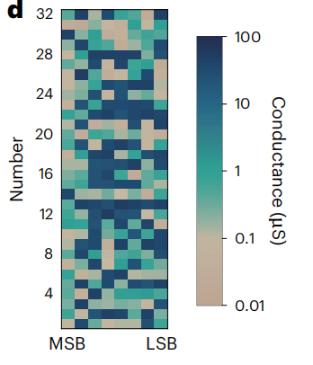
图8 存内排序(TNS)与存内计算(CIM)协同实现原位剪枝的流程图(左)
PointNet++中一个批量归一化层的8位定点权重在忆阻器阵列中的电导分布(右)
基于上述成功的实验,这套存算一体排序架构作为核心硬件引擎的未来已清晰可见。在边缘端,它将为智能物联网、可穿戴设备和自动驾驶汽车的实时决策提供强大动力,让复杂的AI算法在功耗受限的设备上高效运行。在云端,它则能为大规模数据库、搜索引擎和推荐系统提供前所未有的排序性能,在提升服务响应速度的同时,显著降低数据中心的巨大能耗。
该成果是对AI时代核心算力瓶颈的一次成功突围,它标志着存算一体技术已经从处理简单的“乘加”运算,进化到能够胜任复杂的逻辑排序任务,展现了其巨大的潜力。正如论文通讯作者陶耀宇所展望的:“根据初步测算,若该技术在智能终端、工业控制、数据中心等核心应用场景中推广,仅在边缘AI芯片市场就可形成百亿元级年产值潜力,大幅提升传统算力系统的性能。更重要的是,在社会层面,该技术有望推动新一代智慧交通、智慧医疗、智能制造、数字政府系统更加高效运行,释放数据价值,助力新质生产力形成。”

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)