linux 之dma_buf (3)- dma_buf_attach/dma_buf_map_attachment
在上一篇中,我们学习了如何使用 CPU 在 kernel 空间访问 dma-buf 物理内存,但通常这种操作方法在内核中出现的频率并不高,因为 dma-buf 设计之初就是为满足那些大内存访问需求的硬件而设计的,如GPU/DPU。在这种场景下,如果使用CPU直接去访问 memory,那么性能会大大降低。因此,dma-buf 在内核中出现频率最高的还是它的 dma_buf_attach() 和 dm
一、前言
在上一篇中,我们学习了如何使用 CPU 在 kernel 空间访问 dma-buf 物理内存,但通常这种操作方法在内核中出现的频率并不高,因为 dma-buf 设计之初就是为满足那些大内存访问需求的硬件而设计的,如GPU/DPU。在这种场景下,如果使用CPU直接去访问 memory,那么性能会大大降低。因此,dma-buf 在内核中出现频率最高的还是它的 dma_buf_attach() 和 dma_buf_map_attachment() 接口。本篇我们就一起来学习如何通过这两个 API 来实现 DMA 硬件对 dma-buf 物理内存的访问。
二、DMA Access
dma-buf 提供给 DMA 硬件访问的 API 主要就两个:
dma_buf_attach()
dma_buf_map_attachment()
这两个接口调用有严格的先后顺序,必须先 attach,再 map attachment,因为后者的参数是由前者提供的,所以通常这两个接口形影不离。
与上面两个 API 相对应的反向操作接口为: dma_buf_dettach() 和 dma_buf_unmap_attachment(),具体我就不细说了。
2.1 sg_table
由于 DMA 操作涉及到内核中 dma-mapping 诸多接口及概念,本篇为避重就轻,无意讲解。但 sg_table 的概念必须要提一下,因为它是 dma-buf 供 DMA 硬件访问的终极目标,也是 DMA 硬件访问离散 memory 的唯一途径!
sg_table 本质上是由一块块单个物理连续的 buffer 所组成的链表,但是这个链表整体上看却是离散的,因此它可以很好的描述从 高端内存 上分配出的离散 buffer。当然,它同样可以用来描述从 低端内存 上分配出的物理连续 buffer。
如下图所示:
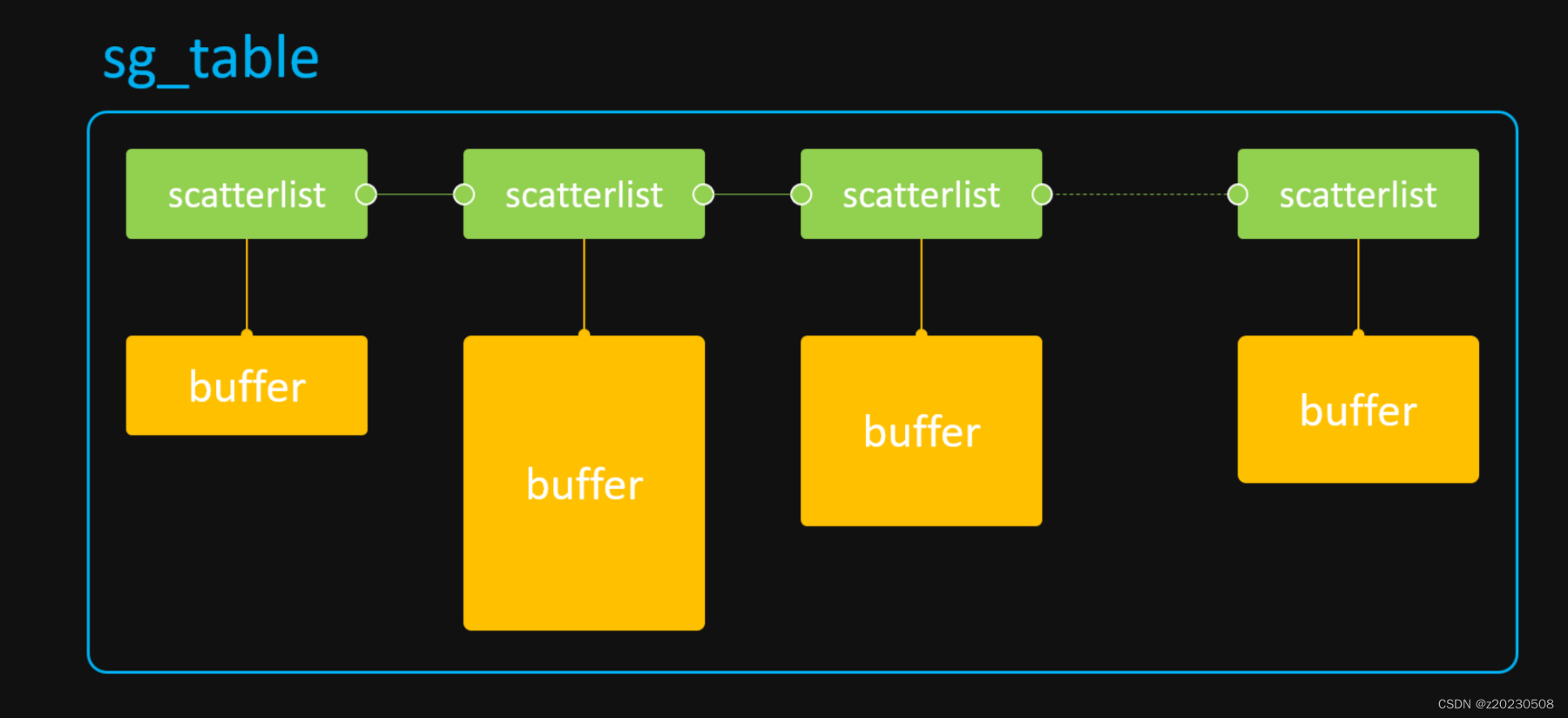
sg_table 代表着整个链表,而它的每一个链表项则由 scatterlist 来表示。因此,1个scatterlist 也就对应着一块 物理连续 的 buffer。我们可以通过如下接口来获取一个 scatterlist 对应 buffer 的物理地址和长度:
- sg_dma_address(sgl)
- sg_dma_len(sgl)
有了 buffer 的物理地址和长度,我们就可以将这两个参数配置到 DMA 硬件寄存器中,这样就可以实现 DMA 硬件对这一小块 buffer 的访问。那如何访问整块离散 buffer 呢?当然是用个 for 循环,不断的解析 scatterlist,不断的配置 DMA 硬件寄存器啦!
对于现代多媒体硬件来说,IOMMU 的出现,解决了程序员编写 for 循环的烦恼。因为在 for 循环中,每次配置完 DMA 硬件寄存器后,都需要等待本次 DMA 传输完毕,然后才能进行下一次循环,这大大降低了软件的执行效率。而 IOMMU 的功能就是用来解析 sg_table 的,它会将 sg_table 内部一个个离散的小 buffer 映射到自己内部的设备地址空间,使得这整块 buffer 在自己内部的设备地址空间上是连续的。这样,在访问离散 buffer 的时候,只需要将 IOMMU 映射后的设备地址(与 MMU 映射后的 CPU 虚拟地址不是同一概念)和整块 buffer 的 size 配置到 DMA 硬件寄存器中即可,中途无需再多次配置,便完成了 DMA 硬件对整块离散 buffer 的访问,大大的提高了软件的效率。
2.2 dma_buf_attach()
该函数实际是 “dma-buf attach device” 的缩写,用于建立一个 dma-buf 与 device 的连接关系,这个连接关系被存放在新创建的 dma_buf_attachment 对象中,供后续调用 dma_buf_map_attachment() 使用。
该函数对应 dma_buf_ops 中的 attach 回调接口,如果 device 对后续的 map attachment 操作没有什么特殊要求,可以不实现。
2.3 dma_buf_map_attachment()
该函数实际是 “dma-buf map attachment into sg_table” 的缩写,它主要完成2件事情:
生成 sg_table
同步 Cache
选择返回 sg_table 而不是物理地址,是为了兼容所有 DMA 硬件(带或不带 IOMMU),因为 sg_table 既可以表示连续物理内存,也可以表示非连续物理内存。
同步 Cache 是为了防止该 buffer 事先被 CPU 填充过,数据暂存在 Cache 中而非 DDR 上,导致 DMA 访问的不是最新的有效数据。通过将 Cache 中的数据回写到 DDR 上可以避免此类问题的发生。同样的,在 DMA 访问内存结束后,需要将 Cache 设置为无效,以便后续 CPU 直接从 DDR 上(而非 Cache 中)读取该内存数据。通常我们使用如下流式 DMA 映射接口来完成 Cache 的同步:
dma_map_single() / dma_unmap_single()
dma_map_page() / dma_unmap_page()
dma_map_sg() / dma_unmap_sg()
dma_buf_map_attachment() 对应 dma_buf_ops 中的 map_dma_buf 回调接口,如第一篇《最简单的 dma-buf 驱动程序》所述,该回调接口(包括 unmap_dma_buf 在内)被强制要求实现,否则 dma_buf_export() 将执行失败。
三、为什么需要 attach 操作 ?
同一个 dma-buf 可能会被多个 DMA 硬件访问,而每个 DMA 硬件可能会因为自身硬件能力的限制,对这块 buffer 有自己特殊的要求。比如硬件 A 的寻址能力只有0x0 ~ 0x10000000,而硬件 B 的寻址能力为 0x0 ~ 0x80000000,那么在分配 dma-buf 的物理内存时,就必须以硬件 A 的能力为标准进行分配,这样硬件 A 和 B 都可以访问这段内存。否则,如果只满足 B 的需求,那么 A 可能就无法访问超出 0x10000000 地址以外的内存空间,道理其实类似于木桶理论。
因此,attach 操作可以让 exporter 驱动根据不同的 device 硬件能力,来分配最合适的物理内存。
通过设置 device->dma_params 参数,来告知 exporter 驱动该 DMA 硬件的能力限制。
但是在上一篇的示例中,dma-buf 的物理内存都是在 dma_buf_export() 的时候就分配好了的,而 attach 操作只能在 export 之后才能执行,那我们如何确保已经分配好的内存是符合硬件能力要求的呢?这就引出了下面的话题。
四、何时分配内存?
答案是:既可以在 export 阶段分配,也可以在 map attachment 阶段分配,甚至可以在两个阶段都分配,这通常由 DMA 硬件能力来决定。
首先,驱动人员需要统计当前系统中都有哪些 DMA 硬件要访问 dma-buf;
然后,根据不同的 DMA 硬件能力,来决定在何时以及如何分配物理内存。
通常的策略如下(假设只有 A、B 两个硬件需要访问 dma-buf ):
如果硬件 A 和 B 的寻址空间有交集,则在 export 阶段进行内存分配,分配时以 A / B 的交集为准;
如果硬件 A 和 B 的寻址空间没有交集,则只能在 map attachment 阶段分配内存。
对于第二种策略,因为 A 和 B 的寻址空间没有交集(即完全独立),所以它们实际上是无法实现内存共享的。此时的解决办法是: A 和 B 在 map attachment 阶段,都分配各自的物理内存,然后通过 CPU 或 通用DMA 硬件,将 A 的 buffer 内容拷贝到 B 的 buffer 中去,以此来间接的实现 buffer “共享”。
另外还有一种策略,就是不管三七二十一,先在 export 阶段分配好内存,然后在首次 map attachment 阶段通过 dma_buf->attachments 链表,与所有 device 的能力进行一一比对,如果满足条件则直接返回 sg_table;如果不满足条件,则重新分配符合所有 device 要求的物理内存,再返回新的 sg_table。
五、示例代码
本示例基于第一篇的 export-test.c 进行修改,对 dma_buf_ops 中的 attach 和 map_dma_buf 回调接口进行实现。当然,为了方便演示,我们仍然像之前那样,在 exporter_alloc_page() 中事先分配好了 dma-buf 的物理内存。
export_test.c
#include <linux/dma-buf.h>
#include <linux/module.h>
#include <linux/slab.h>
struct dma_buf *dmabuf_export;
EXPORT_SYMBOL(dmabuf_export);
static int exporter_attach(struct dma_buf* dmabuf, struct dma_buf_attachment *attachment)
{
pr_info("dmanbuf attach device :%s \n",dev_name(attachment->dev));
return 0;
}
static void exporter_detach(struct dma_buf *dmabuf, struct dma_buf_attachment *attachment)
{
pr_info("dmabuf detach device :%s \n",dev_name(attachment->dev));
}
static struct sg_table *exporter_map_dma_buf(struct dma_buf_attachment *attachment,
enum dma_data_direction dir)
{
void *vaddr = attachment->dmabuf->priv;
struct sg_table *table;
table = kmalloc(sizeof(*table),GFP_KERNEL);
sg_alloc_table(table, 1, GFP_KERNEL);
sg_dma_len(table->sgl) = PAGE_SIZE;
sg_dma_address(table->sgl) = dma_map_single(NULL, vaddr, PAGE_SIZE,dir);
return table;
}
static void exporter_unmap_dma_buf(struct dma_buf_attachment *attachment,
struct sg_table *table,
enum dma_data_direction dir)
{
dma_unmap_single(NULL, sg_dma_address(table->sgl), PAGE_SIZE, dir);
sg_free_table(table);
kfree(table);
}
static void exporter_release(struct dma_buf *dmabuf)
{
return kfree(dmabuf->priv);
}
/*static void *exporter_kmap_atomic(struct dma_buf *dmabuf, unsigned long page_num)
{
return NULL;
}
static void *exporter_kmap(struct dma_buf *dmabuf, unsigned long page_num)
{
return NULL;
}*/
static void* exporter_vmap(struct dma_buf *dmabuf)
{
return dmabuf->priv;
}
static int exporter_mmap(struct dma_buf *dmabuf, struct vm_area_struct *vma)
{
return -ENODEV;
}
static const struct dma_buf_ops exp_dmabuf_ops = {
.attach = exporter_attach,
.detach = exporter_detach,
.map_dma_buf = exporter_map_dma_buf,
.unmap_dma_buf = exporter_unmap_dma_buf,
.release = exporter_release,
// .map_atomic = exporter_kmap_atomic,
// .map = exporter_kmap,
.vmap = exporter_vmap,
.mmap = exporter_mmap,
};
static struct dma_buf *exporter_alloc_page(void)
{
DEFINE_DMA_BUF_EXPORT_INFO(exp_info);
struct dma_buf *dmabuf;
void *vaddr;
vaddr = kzalloc(PAGE_SIZE,GFP_KERNEL);
exp_info.ops = &exp_dmabuf_ops;
exp_info.size = PAGE_SIZE;
exp_info.flags = O_CLOEXEC;
exp_info.priv = vaddr;
dmabuf= dma_buf_export(&exp_info);
if(dmabuf == NULL)
printk(KERN_INFO"DMA buf export error\n");
sprintf(vaddr, "hello world");
return dmabuf;
}
static int __init exporter_init(void)
{
dmabuf_export = exporter_alloc_page();
return 0;
}
module_init(exporter_init);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("ZWQ");
MODULE_DESCRIPTION("zwq dma used buffer");
在上面的 attach 实现中,我们仅仅只是打印了一句 log,其他什么事情也不做。在 map_dma_buf 实现中,我们构造了一个 sg_table 对象,并通过调用 dma_map_single() 来获取 dma_addr 以及实现 Cache 同步操作。
import_test.c
#include <linux/dma-buf.h>
#include <linux/module.h>
#include <linux/slab.h>
//#include <linux/dma-buf-map.h>
extern struct dma_buf *dmabuf_export;
static int importer_read(struct dma_buf *dmabuf)
{
#if 0
void * addr;
// struct dma_buf_map map;
// int ret =0;
addr = dma_buf_vmap(dmabuf);
// printk(KERN_INFO "read from dma_buf :%s \n",(char *)addr);
pr_info("read from dma_buf:%s \n",(char*)addr);
dma_buf_vunmap(dmabuf,addr);
#endif
struct dma_buf_attachment *attachment;
struct sg_table *table;
struct device *dev;
unsigned int reg_addr, reg_size;
dev = kzalloc(sizeof(*dev), GFP_KERNEL);
dev_set_name(dev,"importer");
attachment = dma_buf_attach(dmabuf, dev);
table = dma_buf_map_attachment(attachment, DMA_BIDIRECTIONAL);
reg_addr = sg_dma_address(table->sgl);
reg_size = sg_dma_len(table->sgl);
pr_info("reg_addr = 0x%08x, reg_size = 0x%08x\n" , reg_addr, reg_size);
dma_buf_unmap_attachment(attachment, table, DMA_BIDIRECTIONAL);
dma_buf_detach(dmabuf, attachment);
return 0;
}
static int __init import_init(void)
{
importer_read(dmabuf_export);
return 0;
}
module_init(import_init);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("zwq");
示例描述:
1、exporter 通过 kzalloc 分配了一个 PAGE 大小的物理连续 buffer;
2、importer 驱动通过 extern 关键字导入了 exporter 的 dma-buf,并通过 dma_buf_map_attachment() 接口获取到了该物理内存所对应的 sg_table,然后将该 sg_table 中的 address 和 size 解析到 reg_addr 和 reg_size 这两个虚拟寄存器中。
5.1 attach 如何让map_attachment更灵活?
在import_test.c 中,有一个attachment = dma_buf_attach(dmabuf, dev);可以根据 dev 的不同,获取不同的attachment,只要在 export_test.c 中.attach 函数实现中,对dma_buf_attachment 进行判断了。如果没有具体什么硬件操作,可以不实现。
下面看一下 dma_buf_attch 是如何实现的:
dma_buf_attach
struct dma_buf_attachment *dma_buf_attach(struct dma_buf *dmabuf,
struct device *dev)
{
return dma_buf_dynamic_attach(dmabuf, dev, NULL, NULL);
}
EXPORT_SYMBOL_GPL(dma_buf_attach);
dma_buf_dynamic_attach(dmabuf, dev, NULL, NULL);
struct dma_buf_attachment *
dma_buf_dynamic_attach(struct dma_buf *dmabuf, struct device *dev,
const struct dma_buf_attach_ops *importer_ops,
void *importer_priv)
{
struct dma_buf_attachment *attach;
int ret;
if (WARN_ON(!dmabuf || !dev))
return ERR_PTR(-EINVAL);
if (WARN_ON(importer_ops && !importer_ops->move_notify))
return ERR_PTR(-EINVAL);
attach = kzalloc(sizeof(*attach), GFP_KERNEL);
if (!attach)
return ERR_PTR(-ENOMEM);
attach->dev = dev; // dev 赋值
attach->dmabuf = dmabuf; //dmabuf 赋值
if (importer_ops)
attach->peer2peer = importer_ops->allow_peer2peer;
attach->importer_ops = importer_ops; //NULL
attach->importer_priv = importer_priv; //NULL
if (dmabuf->ops->attach) {
ret = dmabuf->ops->attach(dmabuf, attach); //这里就是执行export_test.c .attach 的函数
if (ret)
goto err_attach;
}
dma_resv_lock(dmabuf->resv, NULL);
list_add(&attach->node, &dmabuf->attachments); //把attachment 加入dmabuf list
dma_resv_unlock(dmabuf->resv);
/* When either the importer or the exporter can't handle dynamic
* mappings we cache the mapping here to avoid issues with the
* reservation object lock.
*/
if (dma_buf_attachment_is_dynamic(attach) !=
dma_buf_is_dynamic(dmabuf)) {
struct sg_table *sgt;
if (dma_buf_is_dynamic(attach->dmabuf)) {
dma_resv_lock(attach->dmabuf->resv, NULL);
ret = dma_buf_pin(attach);
if (ret)
goto err_unlock;
}
sgt = dmabuf->ops->map_dma_buf(attach, DMA_BIDIRECTIONAL);
if (!sgt)
sgt = ERR_PTR(-ENOMEM);
if (IS_ERR(sgt)) {
ret = PTR_ERR(sgt);
goto err_unpin;
}
if (dma_buf_is_dynamic(attach->dmabuf))
dma_resv_unlock(attach->dmabuf->resv);
attach->sgt = sgt;
attach->dir = DMA_BIDIRECTIONAL;
}
return attach; //返回 attachment
err_attach:
kfree(attach);
return ERR_PTR(ret);
err_unpin:
if (dma_buf_is_dynamic(attach->dmabuf))
dma_buf_unpin(attach);
err_unlock:
if (dma_buf_is_dynamic(attach->dmabuf))
dma_resv_unlock(attach->dmabuf->resv);
dma_buf_detach(dmabuf, attach);
return ERR_PTR(ret);
}
EXPORT_SYMBOL_GPL(dma_buf_dynamic_attach);
5.2 编译
dma_map_single(NULL, vaddr, PAGE_SIZE,dir); 因dev 赋值为NULL,所以驱动加载后,报错。
因为 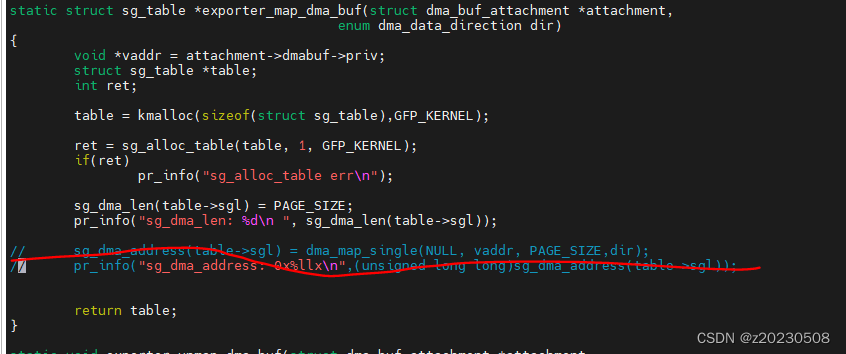
把这行代码注掉, insmod 驱动,不会触发call trace 。这里的dma_map_single 参数dev 不能指定NULL。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)