cuda 本地内存使用_CUDA编程入门(三)从矩阵加法例程上手CUDA编程
这一篇我们来使用CUDA写一个矩阵加法的小程序,实际上手一下。环境搭建笔者的测试环境是Ubuntu 16.04系统 + Titan XP显卡。CUDA Toolkit和显卡驱动的安装我就不赘述了,相信玩深度学习的各位都安装过。如果你不知道自己安装没安装过,但你用GPU跑过pytorch、tensorflow等框架的代码,那你也其实是安装过这些环境的,可以直接编译CUDA程序。CUDA代码...
这一篇我们来使用CUDA写一个矩阵加法的小程序,实际上手一下。
环境搭建
笔者的测试环境是Ubuntu 16.04系统 + Titan XP显卡。CUDA Toolkit和显卡驱动的安装我就不赘述了,相信玩深度学习的各位都安装过。如果你不知道自己安装没安装过,但你用GPU跑过pytorch、tensorflow等框架的代码,那你也其实是安装过这些环境的,可以直接编译CUDA程序。CUDA代码文件后缀名是.cu。编译单文件CUDA程序非常方便,运行下面这条指令即可。
nvcc -o test test.cu之后会生成一个可执行文件test,使用下面的命令即可运行。
./test是不是非常简单,目前这种方式已经足够我们进行CUDA编程的入门了,之后我们再学习使用其他工具进行程序的调试。
从矩阵加法入手
既然是第一个程序,我们从最经典也最适合GPU的矩阵加法入手,学习一下标准的CUDA程序会由哪些部分组成。我们会实现一个矩阵求和的程序,然后统计运行时间,看看相比于CPU串行编程,GPU到底达到了多高的加速比。先贴代码。
#include #include #include "cudastart.h"//CPU对照组,用于对比加速比void sumMatrix2DonCPU(float * MatA,float * MatB,float * MatC,int nx,int ny){ float* a = MatA; float* b = MatB; float* c = MatC; for(int j=0; j { for(int i=0; i { c[i] = a[i]+b[i]; } c += nx; b += nx; a += nx; }}//核函数,每一个线程计算矩阵中的一个元素。__global__ void sumMatrix(float * MatA,float * MatB,float * MatC,int nx,int ny){ int ix = threadIdx.x+blockDim.x*blockIdx.x; int iy = threadIdx.y+blockDim.y*blockIdx.y; int idx = ix+iy*ny; if (ix { MatC[idx] = MatA[idx]+MatB[idx]; }}//主函数int main(int argc,char** argv){ //设备初始化 printf("strating...\n"); initDevice(0); //输入二维矩阵,4096*4096,单精度浮点型。 int nx = 1<<12; int ny = 1<<12; int nBytes = nx*ny*sizeof(float); //Malloc,开辟主机内存 float* A_host = (float*)malloc(nBytes); float* B_host = (float*)malloc(nBytes); float* C_host = (float*)malloc(nBytes); float* C_from_gpu = (float*)malloc(nBytes); initialData(A_host, nx*ny); initialData(B_host, nx*ny); //cudaMalloc,开辟设备内存 float* A_dev = NULL; float* B_dev = NULL; float* C_dev = NULL; CHECK(cudaMalloc((void**)&A_dev, nBytes)); CHECK(cudaMalloc((void**)&B_dev, nBytes)); CHECK(cudaMalloc((void**)&C_dev, nBytes)); //输入数据从主机内存拷贝到设备内存 CHECK(cudaMemcpy(A_dev, A_host, nBytes, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(B_dev, B_host, nBytes, cudaMemcpyHostToDevice)); //二维线程块,32×32 dim3 block(32, 32); //二维线程网格,128×128 dim3 grid((nx-1)/block.x+1, (ny-1)/block.y+1); //测试GPU执行时间 double gpuStart = cpuSecond(); //将核函数放在线程网格中执行 sumMatrix<<>>(A_dev, B_dev, C_dev, nx, ny); CHECK(cudaDeviceSynchronize()); double gpuTime = cpuSecond() - gpuStart; printf("GPU Execution Time: %f sec\n", gpuTime); //在CPU上完成相同的任务 cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost); double cpuStart=cpuSecond(); sumMatrix2DonCPU(A_host, B_host, C_host, nx, ny); double cpuTime = cpuSecond() - cpuStart; printf("CPU Execution Time: %f sec\n", cpuTime); //检查GPU与CPU计算结果是否相同 CHECK(cudaMemcpy(C_from_gpu, C_dev, nBytes, cudaMemcpyDeviceToHost)); checkResult(C_host, C_from_gpu, nx*ny); //释放内存 cudaFree(A_dev); cudaFree(B_dev); cudaFree(C_dev); free(A_host); free(B_host); free(C_host); free(C_from_gpu); cudaDeviceReset(); return 0;}代码我传在github上,需要的同学可以clone下来跑一下。
https://github.com/ZihaoZhao/CUDA_study/tree/master/Sum_Matrix
运行结果
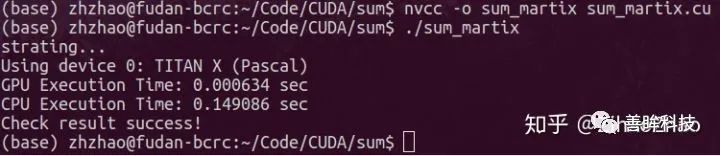
strating...Using device 0: TITAN X (Pascal)GPU Execution Time: 0.000634 secCPU Execution Time: 0.149086 secCheck result success!这样测量出的加速比为0.149086/0.000634=235倍。
在测量运行时间时,我们在cpuSecond()函数里面实际使用的是gettimeofday()函数,这样对于测量GPU时间来说其实是有一定误差的,不过也能一定程度反映GPU的加速比。学习一门语言,上手编程是必须的,建议想要深入学习CUDA的读者也亲手编写一下代码,至少run一下,会有更多收获。来源:https://zhuanlan.zhihu.com/p/97044592
 End
End
声明:部分内容来源于网络,仅供读者学习、交流之目的。文章版权归原作者所有。如有不妥,请联系删除。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)