大型语言模型中的 KV 缓存优化技术
大型语言模型 (LLM) 的卓越功能也带来了巨大的计算挑战,尤其是在 GPU 内存使用方面。这些挑战的根源之一在于所谓的键值 (KV) 缓存,这是 LLM 中采用的一项关键优化技术,用于确保高效的逐个标记生成。此缓存会消耗大量 GPU 内存,以至于它本身会限制 LLM 的性能和上下文大小。本文介绍了键值缓存优化技术。首先,本文将解释键值缓存的基本工作原理,然后深入探讨开源模型和框架实现的各种方法,
大型语言模型 (LLM) 的卓越功能也带来了巨大的计算挑战,尤其是在 GPU 内存使用方面。这些挑战的根源之一在于所谓的键值 (KV) 缓存,这是 LLM 中采用的一项关键优化技术,用于确保高效的逐个标记生成。此缓存会消耗大量 GPU 内存,以至于它本身会限制 LLM 的性能和上下文大小。
本文介绍了键值缓存优化技术。首先,本文将解释键值缓存的基本工作原理,然后深入探讨开源模型和框架实现的各种方法,以增强其可扩展性并减少其内存占用。
我会假设您对 Transformer 和自注意力机制有基本的了解,但会回顾一些最关键的概念。 《Transformer 图解》也是初学者的良好资源。
KV 缓存的动机
在推理过程中,LLM 会逐个 token 生成输出,这个过程称为自回归解码。生成的每个 token 都依赖于所有先前的 token,包括提示中的 token 以及所有先前生成的输出 token。当这个 token 列表由于较长的提示或输出而变得庞大时,自注意力阶段的计算可能会成为瓶颈。
KV 缓存解决了这个瓶颈,无论令牌数量多少,都能为每个解码步骤保持较小且一致的性能。
要了解其必要性,请回想一下,在最初提出并用于 Llama-7B 等模型的标准自注意力机制中,每个标记都会计算三个向量,分别称为键向量、查询向量和值向量。这些向量是通过标记的嵌入与WK、WQ和WV矩阵(它们是模型学习参数的一部分)之间的简单矩阵乘法计算得出的。下图展示了包含六个标记的提示的键向量的计算过程:
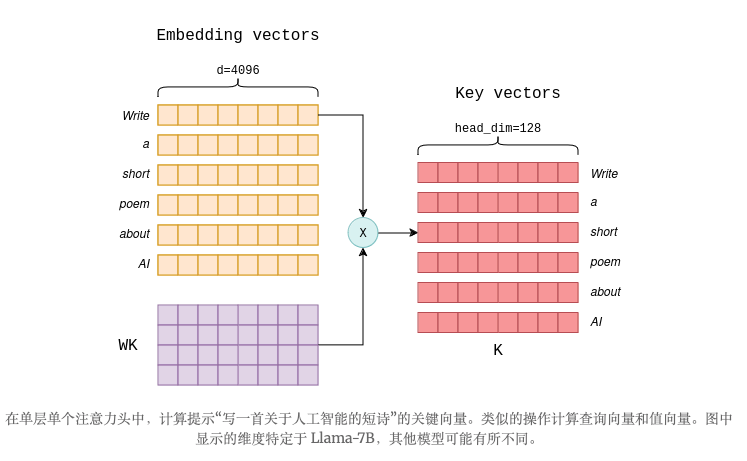
在标准的自注意力机制中,存在多个并行的“头”,它们独立地执行自注意力机制。因此,上述过程会在每个注意力头和每个层上重复,每个层都具有不同的参数矩阵。例如,在 Llama-7B 中,这意味着n_heads=32且n_layers=32只生成一个 token。
随着 token 数量的增加,这种矩阵乘法运算会涉及更大的矩阵,并可能使 GPU 的容量饱和。一篇名为《Transformer 推理算法》的文章估计,对于在 A100 GPU 上运行的 52B 参数模型,由于在此阶段执行了过多的浮点运算,性能在 208 个 token 时开始下降。
键值缓存 (KV cache) 解决了这个问题。其核心思想很简单:在连续生成 token 的过程中,为先前 token 计算的键和值向量保持不变。我们无需在每次迭代中为每个 token 重新计算它们,而是只需计算一次,然后缓存起来以供将来的迭代使用。
基本 KV 缓存
缓存的工作原理如下:
- 在初始解码迭代中,会计算所有输入标记的键和值向量,如上图所示。然后,这些向量会存储在 GPU 内存中的张量中,作为缓存。迭代结束后,会生成一个新的标记。
- 在后续解码迭代中,仅计算新生成 token 的键和值向量。先前迭代中缓存的键和值向量,以及新 token 的键和值向量,会被连接起来,形成自注意力所需的K和V矩阵。这样就无需重新计算所有先前 token 的键和值向量。新的键和值向量也会被添加到缓存中。
例如,假设第一次迭代生成了标记“In”(ChatGPT 喜欢用它来开始诗歌)。那么第二次迭代将按如下方式进行(与上图比较):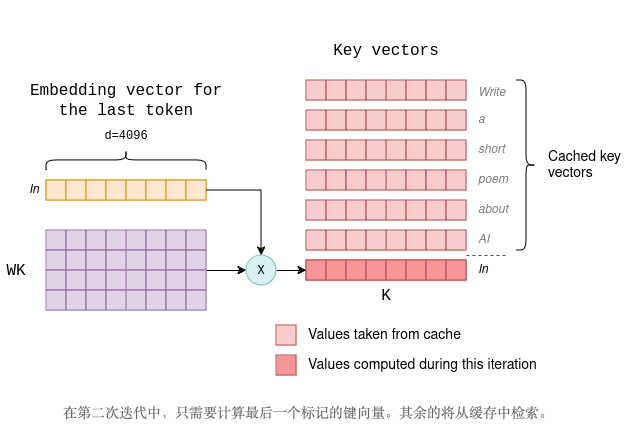
因此,每次连续生成的计算开销都保持较小且一致。正因如此,LLM 对第一个 token 和后续 token 分别设置了不同的性能指标,分别称为“生成第一个 token 的时间”和“每个输出 token 的时间”。生成第一个 token 时,必须计算所有键和值向量,而对于后续 token,只需计算一个键和一个值向量。
你可能想知道为什么我们不缓存查询向量。答案是,缓存了键和值向量后,后续迭代中之前的token的查询向量就变得没有必要了,只需要最新token的查询向量来计算自注意力机制。
缓存的大小
那么,KV 缓存到底需要多大呢?对于每个 token,它需要为每个注意力头和每个层存储两个向量。向量中的每个元素都是一个 16 位浮点数。因此,对于每个 token,缓存中的内存(以字节为单位)为:
2 * 2 * head_dim * n_heads * n_layers
其中head_dim是键和值向量的大小、n_heads注意力头的数量以及n_layers模型中的层数。
代入Llama 2的参数:
| 模型 | 每个令牌的缓存大小 |
|---|---|
| Llama-2-7B | 512KB |
| Llama-2-13B | 800KB |
如果你熟悉每个 LLM 开发人员都应该知道的数字,他们声称每个输出 token 大约需要 1MB 的 GPU 内存。这就是这个数字的由来。
现在,此计算针对每个标记。为了容纳单个推理任务的完整上下文大小,我们必须相应地分配足够的缓存空间。此外,如果我们分批运行推理(即同时对多个提示进行一次推理),则缓存大小会再次成倍增加。因此,缓存的完整大小为:
2 * 2 * head_dim * n_heads * n_layers * max_context_length * batch_size
如果我们想以 8 个为一个批次,利用包含 4096 个 token 的整个 Llama-2-13B 上下文,那么缓存大小将达到 25GB,几乎相当于存储模型参数所需的 26GB。这可是非常大的 GPU 内存!
因此 KV 缓存的大小限制了两件事:
- 可以支持的最大上下文大小。
- 每个推理批次的最大大小。
本文的其余部分将深入探讨减少缓存大小的常用技术。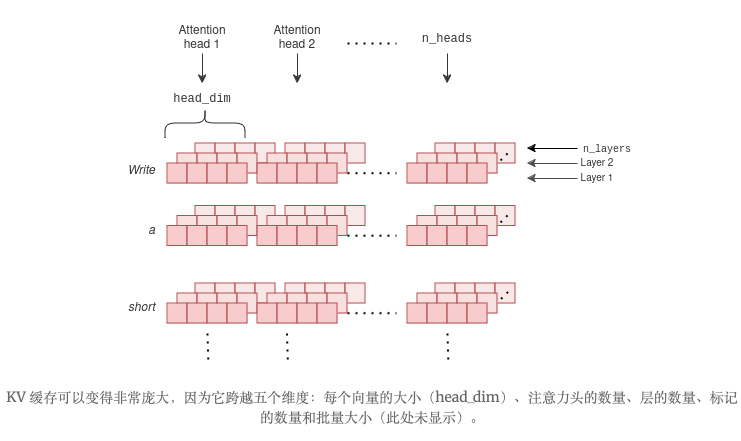
分组查询注意力机制
分组查询注意力机制 (GQA)是原始多头注意力机制的一种变体,它在保留大部分原始性能的同时减少了键值缓存的大小。Llama-2-70B 中就使用了该机制。以下引用Llama-2 论文的内容:
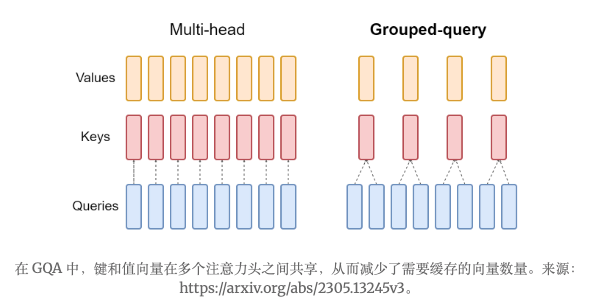
自回归解码的标准做法是缓存序列中前一个标记的键 (K) 和值 (V) 对,以加快注意力计算速度。然而,随着上下文窗口或批次大小的增加,多头注意力 (MHA) 模型中与键值缓存大小相关的内存成本会显著增长。对于较大的模型,键值缓存大小会成为瓶颈,键值投影可以在多个头之间共享,而不会显著降低性能 (Chowdhery 等人,2022)。可以使用原始的单个键值投影的多查询格式 (MQA,Shazeer,2019) 或具有 8 个键值投影的分组查询注意力变体 (GQA,Ainslie 等人,2023)。
使用 GQA 的模型减少了键值向量的注意力头数量,记为n_kv_heads。对于查询向量,注意力头的数量n_heads保持不变。键值向量对随后在多个查询头之间共享。这种方法有效地将键值缓存大小减少了 n_heads / n_kv_heads 倍。
https://arxiv.org/abs/2305.13245v3
例如,在 Llama-2-70B中n_heads = 64和n_kv_heads = 8,将缓存大小减少了 8 倍。下表总结了使用 GQA 的开源模型。
| 模型 | 不使用 GQA 时每个令牌的缓存大小(假设) | GQA 因素 | 使用 GQA 时每个令牌的缓存大小 |
|---|---|---|---|
| Gemma-2B | 144KB | 8 | 18KB |
| Mistral-7B | 512KB | 4 | 128KB |
| Mixtral 8x7B | 1MB | 4 | 256KB |
| Llama-2-70B | 2.5MB | 8 | 320KB |
滑动窗口注意力机制
滑动窗口注意力 (SWA) 是Mistral-7B采用的一种技术,用于支持更长的上下文大小而不增加 KV 缓存大小。
SWA 是对原始自注意力机制的修改。在原始自注意力机制中,使用每个标记的键和查询向量,为每个标记及其所有前面的标记计算一个分数。而 SWA 则W选择固定的窗口大小,并且仅计算每个标记与其前面的标记之间的分数W。
本质上,这意味着只W需要在缓存中保留最新的键和值向量。随着解码的进行,令牌数量超过W,较旧的键和值向量将通过滑动窗口从缓存中逐出,因为它们不再需要。
这里的诀窍在于,W由于 Transformer 的分层架构,模型仍然可以处理更早的 token。有关更早 token 的信息存储在 Transformer 上层的键和值向量中。理论上,该模型可以处理W * n_layerstoken,同时只将W向量保留在缓存中,尽管处理能力会逐渐下降。更详细的解释可以在Mistral 的论文中找到。
实际上,Mistral-7B 使用W=4096,官方支持的上下文大小为context_len=8192。因此,除了 GQA 的 4 倍之外,SWA 还将 KV 缓存大小减少了 2 倍。
滑动窗口注意力
在滑动窗口注意力机制中,只有 W 个键和向量保留在缓存中,较旧的向量将被逐出(此处 W=6)。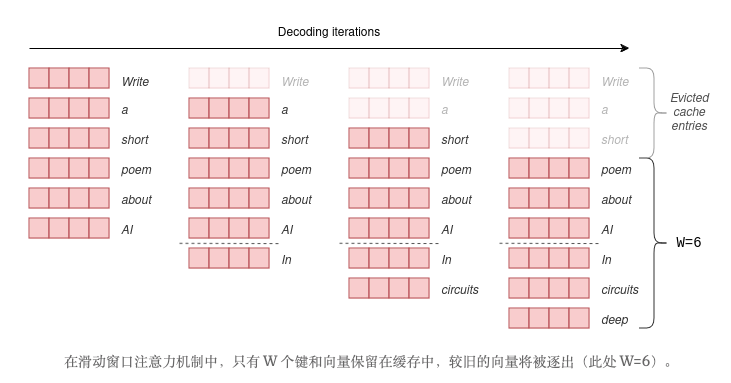
分页注意力机制
PagedAttention 是一个复杂的缓存管理层,由vLLM 推理框架推广和使用。
PagedAttention 背后的动机与 GQA 和 SWA 相同:旨在减少键值缓存大小,以支持更长的上下文长度和更大的批次大小。在大规模推理场景中,处理大批次的提示可以提高输出 token 的吞吐量。
然而,PagedAttention 不会改变模型的架构;相反,它充当缓存管理层,可以与前面提到的任何注意力机制(多头、GQA 和 SWA)无缝集成。因此,它可以与所有现代开源 LLM 模型一起使用。
PagedAttention 提出了两个关键观察:
- 由于过度预留,KV 缓存中存在大量内存浪费:始终会分配支持完整上下文大小所需的最大内存,但很少得到充分利用。
- 在多个推理请求共享同一提示符(或至少是其开头)的情况下,初始令牌的键和值向量相同,并且可以在请求之间共享。这种情况在共享较大初始系统提示符的应用请求中尤为常见。
PagedAttention 管理缓存条目的方式与操作系统管理虚拟和物理内存的方式类似:
- 物理 GPU 内存未预先分配。
- 当保存新的缓存条目时,PagedAttention 会在非连续块中分配新的物理 GPU 内存。
- 动态映射表将缓存的虚拟视图作为连续的张量与非连续的物理块进行映射。
根据他们的研究,这解决了过度预留的问题,将内存浪费从 60-80% 减少到 4%。此外,如果多个推理请求共享相同的初始提示,映射表允许它们重用相同的缓存条目。
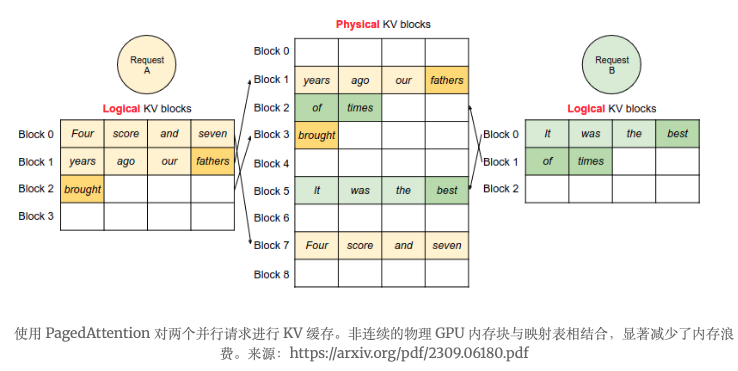
https://arxiv.org/pdf/2309.06180.pdf
跨多个 GPU 的分布式 KV 缓存
闭源模型最近都显著增加了其支持的上下文大小。例如,GPT-4 现在可以容纳 128k 个 token 的上下文,而 Gemini 1.5 则声称最多支持 1M 个 token。然而,使用这些庞大的上下文时,KV 缓存可能会超出单个 GPU 上的可用内存。
例如,假设 GPT-4 的每个令牌内存为 1MB(纯属猜测),则利用完整上下文将需要大约 128GB 的 GPU 内存,超过单个 A100 卡的容量。
分布式推理涉及在多个 GPU 上运行 LLM 请求。这不仅提供了额外的优势,也使 KV 缓存的内存容量超过了单个 GPU 的内存容量。
它的工作原理至少在理论上相当简单:由于自注意力机制由多个独立工作的注意力头组成,因此它可以分布在多个 GPU 上。每个 GPU 都会分配一个注意力头子集来执行。每个注意力头的键和值向量会被缓存在分配的 GPU 的内存中。完成后,所有注意力头的结果会被收集到一个 GPU 上,并在那里合并起来用于其余的 Transformer 层。这种方法允许将缓存分布到与注意力头数量相同的 GPU 上,例如,Llama-70b 最多可以分配 8 个。
像 vLLM 这样的框架提供了开箱即用的分布式推理功能。
概括
总结一下:
- KV 缓存是 LLM 中采用的一项关键优化技术,用于保持一致且高效的每个令牌生成时间。
- 然而,这会对 GPU 内存造成很大的成本,每个令牌可能需要多个 MB 的内存。
- 为了减少内存占用,开源模型利用改进的注意力机制,称为分组查询注意力(GQA)和滑动窗口注意力(SWA)。
- PagedAttention 在 vLLM 框架中实现,是一个透明的缓存管理层,可以减少 KV 缓存造成的 GPU 内存浪费。
- 为了支持具有数十万个标记的庞大上下文,模型可能会将其 KV 缓存分布在多个 GPU 上。
随着开源模型在巨大上下文规模方面赶上闭源模型,关注这一领域的发展肯定会很有趣,这将需要进一步的优化。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)