linux系统怎样指定gpu运行,linux服务器如何指定gpu以及用量
1.在终端执行程序时指定GPUCUDA_VISIBLE_DEVICES=0python your_file.py # 指定GPU集群中第一块GPU使用,其他的屏蔽掉CUDA_VISIBLE_DEVICES=1Only device 1 will be seenCUDA_VISIBLE_DEVICES=0,1Devices 0 and 1 will...
1.在终端执行程序时指定GPU
CUDA_VISIBLE_DEVICES=0 python your_file.py # 指定GPU集群中第一块GPU使用,其他的屏蔽掉
CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen
CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible
CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional 多GPU一起使用
CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked
CUDA_VISIBLE_DEVICES="" No GPU will be visible
z这段话摘抄的,错误:注意,服务器看到的GPU序号和手动在Linux上查看的序号是相反的,比如我们指定os.environ[“CUDA_VISIBLE_DEVICES”] = “0”的话,你会发现在watch nvidia-smi指令下,倒数第一块GPU正在满负荷的运行!
2.在Python代码中指定GPU
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" #指定第一块gpu
3.设置定量的GPU使用量
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.9 # 占用GPU90%的显存
session = tf.Session(config=config)
4.设置最小的GPU使用量
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
5.GPU状态显示和部分指标含义
输入查看:
watch nvidia-smi
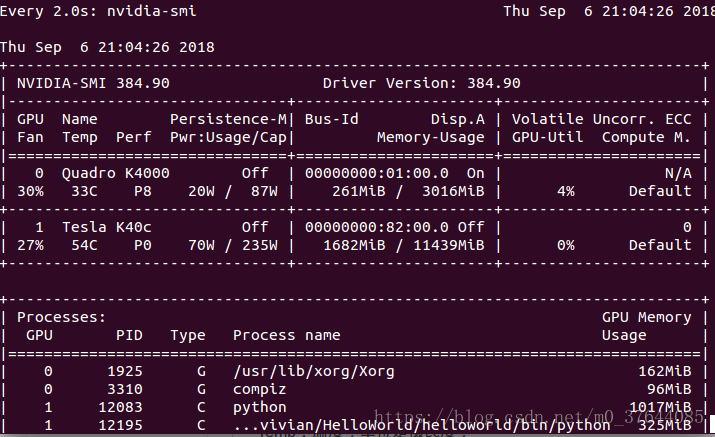
GPU:GPU 编号;
Name:GPU 型号;
Persistence-M:持续模式的状态。持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态;
Fan:风扇转速,从0到100%之间变动;
Temp:温度,单位是摄氏度;
Perf:性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能(即 GPU 未工作时为P0,达到最大工作限度时为P12)。
Pwr:Usage/Cap:能耗;
Memory Usage:显存使用率;
Bus-Id:涉及GPU总线的东西,domain:bus:device.function;
Disp.A:Display Active,表示GPU的显示是否初始化;
Volatile GPU-Util:浮动的GPU利用率;
Uncorr. ECC:Error Correcting Code,错误检查与纠正;
Compute M:compute mode,计算模式。
下方的 Processes 表示每个进程对 GPU 的显存使用率。

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)