我的NVIDA开发者之旅-在GPU上运行Pytorch代码
将Pytorch的实现的模型用GPU去训练
·
目录
介绍
Pytorch与CUDA的安装可以参照我之前写的深度学习环境搭建:Windows10安装cuDNN
Pytorch能够使用CPU或者GPU来实现网络的训练,如果训练的数据集大的话还是用GPU来训练,GPU的训练速度时CPU的10倍以上。我们在用GPU的时候可以用cuda()方法,用CPU的可以用cpu()方法。当然最常用的是to()方法:
| GPU | CPU |
|---|---|
| gpu() | cpu() |
| to(‘cuda’) | to(‘cpu’) |
| Note:使用GPU训练网络的时候,需要注意数据、标签、模型都要放到GPU上。 |
- 声明用GPU
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu') - 将model加载到GPU上
model.to(device) - 将数据、标签放到的GPU上
data,target =data.to(device), target.to(device)
默认情况下,创建Pytorch张量和网络模块的时候,会在CPU上初始化相应的数据。数据转移至GPU的方法叫做.cuda而不是.gpu,这是因为GPU的编程接口采用CUDA,而目前并不是所有的GPU都支持CUDA,只有部分Nvidia的GPU才支持。PyTorch从1.8版本开始支持AMD GPU,,而AMD GPU的编程接口采用ROCm,但是目前想要在AMD显卡运行pytorch仍然有不少问题。
查看GPU信息
-
查看显卡信息
nvidia-smi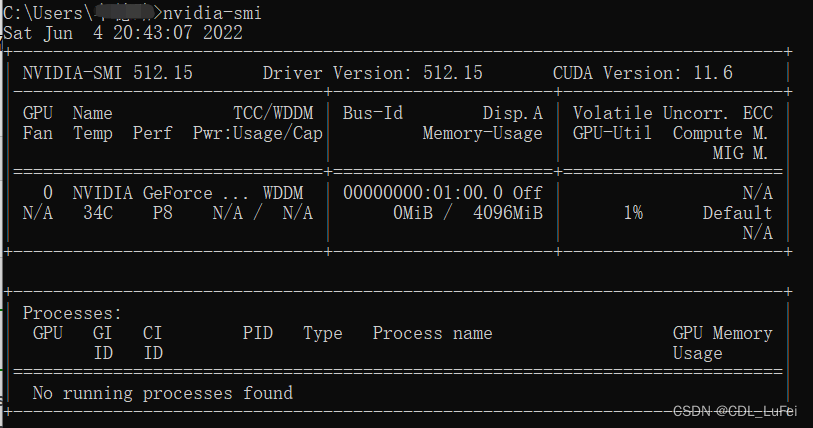
-
查看cuda是否可用
torch.cuda.is_available() -
查看GPU数量
torch.cuda.device_count() -
查看GPU索引号,默认从0开始
torch.cuda.get_device_name(0) -
查看当前使用的GPU,返回显卡的索引号
torch.cuda.current_device()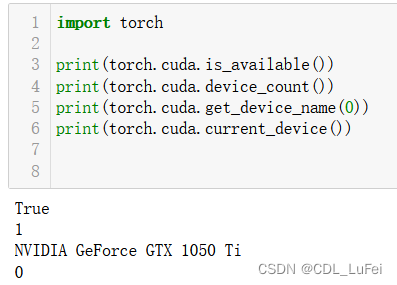
-
查看GPU属性:算力、最大线程数、
torch.cuda.get_device_properties(0)括号中0是显卡的索引
Pytorch指定显卡
- 环境变量设置,这也是Pytorch文档中推荐的方法
- export CUDA_VISIBLE_DEVICE=0
- import os os.environ[“CUDA_VISIBLE_DEVICES”]=‘0’ //改代码在程序中直接写入,可以在后边输入一组不同的索引号来使用多个显卡
- CUDA_VISBLE_DEVICES=0 python demo.py //在终端中运行demo时候指定GPU
- 使用troch.cuda接口
torch.cuda.set_device(0) - 使用pytorch并行接口
net = torch.nn.DataParallel(model, device_ids=[0]) - 初始化网络模型的时候
net =Net.cuda(0)
具体使用什么方法根据自己的情况来选,但还是推荐通过设置环境变量法来设置。
Demo
下面用Pytorch实现一个2层网络去拟合随机数据。这里只是实现前向传播和反向传播部分。
import torch
dtype = torch.float
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
N,D_in,H,D_out = 64,1000,100,10
x = torch.randn(N, D_in,device=device,dtype=dtype)
y = torch.randn(N,D_out,device=device,dtype=dtype)
w1 = torch.randn(D_in,H,device=device,dtype=dtype)
w2 = torch.randn(H,D_out,device=device,dtype=dtype)
learning_rate=1e-6
for t in range(500):
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
loss = (y_pred - y).pow(2).sum().item()
if t %100 ==99:
print(t,loss)
grad_y_pred = 2.0*(y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
参考

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)