CANN技术能力解析技术汇报
适合需自定义网络结构、灵活调整算子组合的场景,自由度高。省心高效:封装了AI开发中的适配、优化、部署细节,开发者可专注算法与业务逻辑。适配性强:兼容主流AI框架与昇腾硬件,无需大幅修改代码即可快速迁移。层次分明:从新手友好的ACL推理到资深开发者需要的自定义构图,覆盖不同需求场景。先说说最让我惊喜的图引擎(GE),这绝对是 CANN 的核心王牌。之前做模型部署,要么用 Eager 模式一步步执行,
昇腾CANN 8.3.RC1 图模式开发全指南:从部署到实践
一、CANN架构核心概述
1.1 什么是昇腾CANN?
昇腾异构计算架构CANN(Compute Architecture for Neural Networks)是昇腾针对AI场景推出的核心平台。它向上兼容MindSpore、PyTorch、TensorFlow等主流AI框架,向下对接昇腾AI处理器与编程层,提供多层次编程接口,是提升昇腾硬件计算效率、快速构建AI应用的关键支撑。
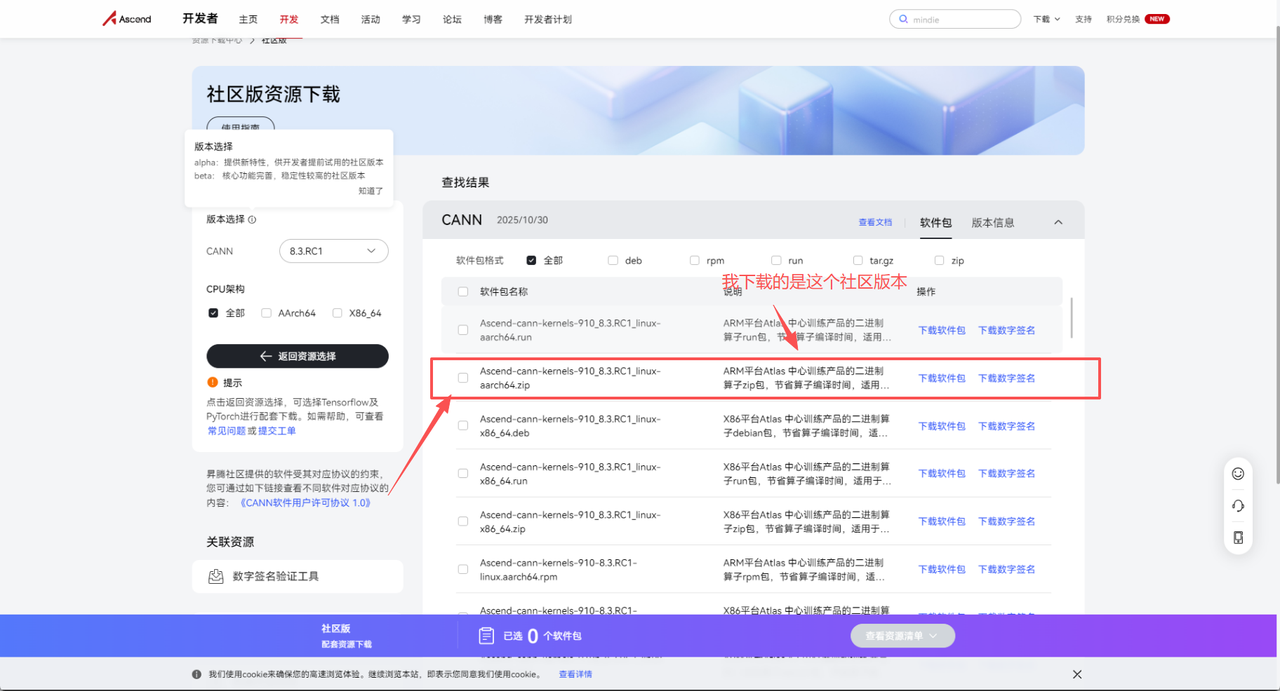
1.2 环境准备(基于Atlas 200I A2)
- 硬件要求:搭载昇腾AI处理器的设备(本文以Atlas 200I A2为例)。
- 关键配置:记录安装路径(示例路径:/usr/local/Ascend/ascend-toolkit/latest),后续编译、运行需依赖该路径。
二、CANN核心特性能力速览
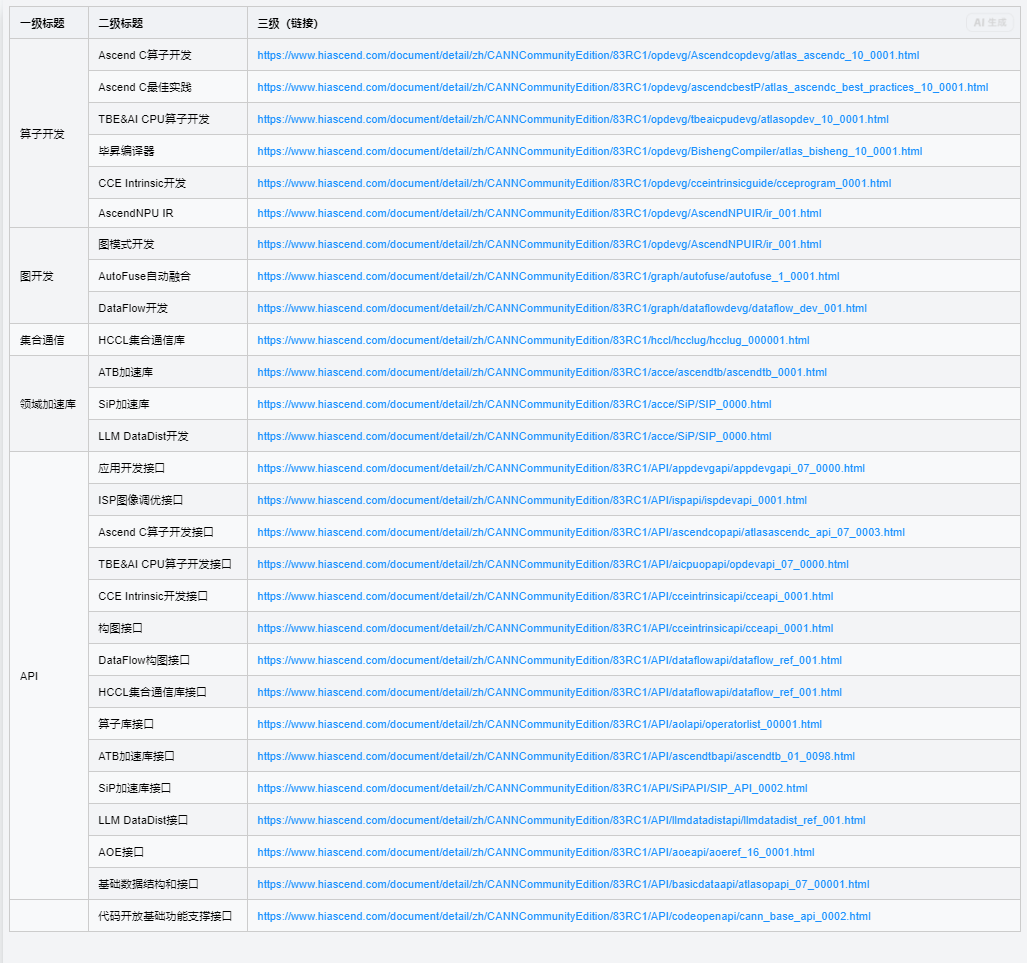
| 一级标题 | 二级标题 | 三级标题(官方文档链接) |
|---|---|---|
| 算子开发 | Ascend C算子开发 | Ascend C算子开发指南 |
| Ascend C最佳实践 | Ascend C最佳实践文档 | |
| TBE&AI CPU算子开发 | TBE&AI CPU算子开发指南 | |
| 毕昇编译器 | 毕昇编译器使用指南 | |
| CCE Intrinsic开发 | CCE Intrinsic开发指南 | |
| AscendNPU IR | AscendNPU IR参考文档 | |
| 图开发 | 图模式开发 | 图模式开发指南 |
| AutoFuse自动融合 | AutoFuse自动融合文档 | |
| DataFlow开发 | DataFlow开发指南 | |
| 集合通信 | HCCL集合通信库 | HCCL集合通信库使用指南 |
| 领域加速库 | ATB加速库 | ATB加速库文档 |
| SiP加速库 | SiP加速库文档 | |
| LLM DataDist开发 | LLM DataDist开发文档 | |
| API | 应用开发接口 | 应用开发接口参考 |
| ISP图像调优接口 | ISP图像调优接口参考 | |
| Ascend C算子开发接口 | Ascend C算子开发接口参考 | |
| TBE&AI CPU算子开发接口 | TBE&AI CPU算子开发接口参考 | |
| CCE Intrinsic开发接口 | CCE Intrinsic开发接口参考 | |
| 构图接口 | 构图接口参考 | |
| DataFlow构图接口 | DataFlow构图接口参考 | |
| HCCL集合通信库接口 | HCCL集合通信库接口参考 | |
| 算子库接口 | 算子库接口参考 | |
| ATB加速库接口 | ATB加速库接口参考 | |
| SiP加速库接口 | SiP加速库接口参考 | |
| LLM DataDist接口 | LLM DataDist接口参考 | |
| AOE接口 | AOE接口参考 | |
| 基础数据结构和接口 | 基础数据结构和接口参考 | |
| 代码开放基础功能支撑接口 | 代码开放基础功能支撑接口参考 |
三、核心组件:GE图引擎详解
3.1 GE图引擎的核心价值
深度学习框架主流运行模式分为Eager模式(即时执行)和图模式(构图后批量执行)。图模式凭借全局视角,能更高效地优化计算流程,提升执行性能。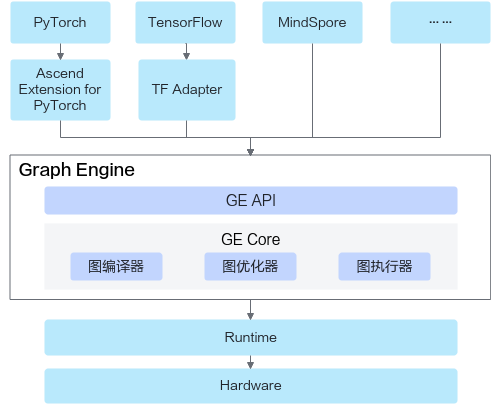
图引擎(Graph Engine,GE)是昇腾平台计算图编译与运行的核心,具备三大核心能力:
- 跨框架兼容:将PyTorch、TensorFlow等主流框架模型统一转换为Ascend IR表示的计算图(Ascend Graph)。
- 编译优化:通过图编译加速技术,最大化昇腾硬件执行效率。
- 灵活扩展:提供统一图开发接口,支持自定义图结构,快速部署神经网络业务。
3.2 GE图引擎的核心优势
- 简化模型转换:现成ONNX、PB模型可通过ATC命令一行转换为昇腾适配的OM离线模型,操作便捷且稳定性高。
- 自定义构图灵活:C++接口支持逐个添加内置算子,支持动态多输入、多输出算子,文档示例丰富,上手成本低。
- 性能优化彻底:依托全局图视角,实现算子融合、计算流程简化等优化,大幅提升模型运行效率。
四、图模式运行:两种实操方案
转换为OM模型后,可通过以下两种方式运行,按需选择即可:
4.1 方案1:ACL接口加载OM模型(推理首选)
适合直接使用预训练模型进行推理的场景,步骤简洁、通用性强。
[图片]
4.1.1 核心代码实现(main.cpp)
#include "acl/acl.h"
#include <iostream>
int main() {
// 1. ACL初始化
aclError ret = aclInit(nullptr);
if (ret != ACL_ERROR_NONE) {
std::cout << "ACL init failed!" << std::endl;
return -1;
}
// 2. 加载OM模型(需修改为实际模型路径)
const char* modelPath = "$HOME/module/out/onnx_resnet50.om";
uint32_t modelId;
ret = aclmdlLoadFromFile(modelPath, &modelId);
if (ret != ACL_ERROR_NONE) {
std::cout << "Load model failed!" << std::endl;
aclFinalize();
return -1;
}
// 3. 准备输入输出数据(实际场景需按模型输入shape分配内存、拷贝数据,参考《应用开发指南》)
// ...(内存分配、数据拷贝代码省略)
// 4. 执行推理
ret = aclmdlExecute(modelId, nullptr);
if (ret == ACL_ERROR_NONE) {
std::cout << "Inference success!" << std::endl;
} else {
std::cout << "Inference failed!" << std::endl;
}
// 5. 释放资源
aclmdlUnload(modelId);
aclFinalize();
return 0;
}
4.1.2 编译与运行
- 创建Makefile,指定头文件和库路径:
ASCEND_PATH := /usr/local/Ascend/ascend-toolkit/latest
INCLUDES := -I$(ASCEND_PATH)/include -I$(ASCEND_PATH)/include/acl
LIBS := -L$(ASCEND_PATH)/lib64 -lacl -lgraph
main: main.cpp
g++ main.cpp -o main $(INCLUDES) $(LIBS)
- 执行编译:
make,生成main可执行文件。 - 运行程序:
./main,输出“Inference success!”即为执行成功。
4.2 方案2:C++接口自定义构图(灵活定制)
适合需自定义网络结构、灵活调整算子组合的场景,自由度高。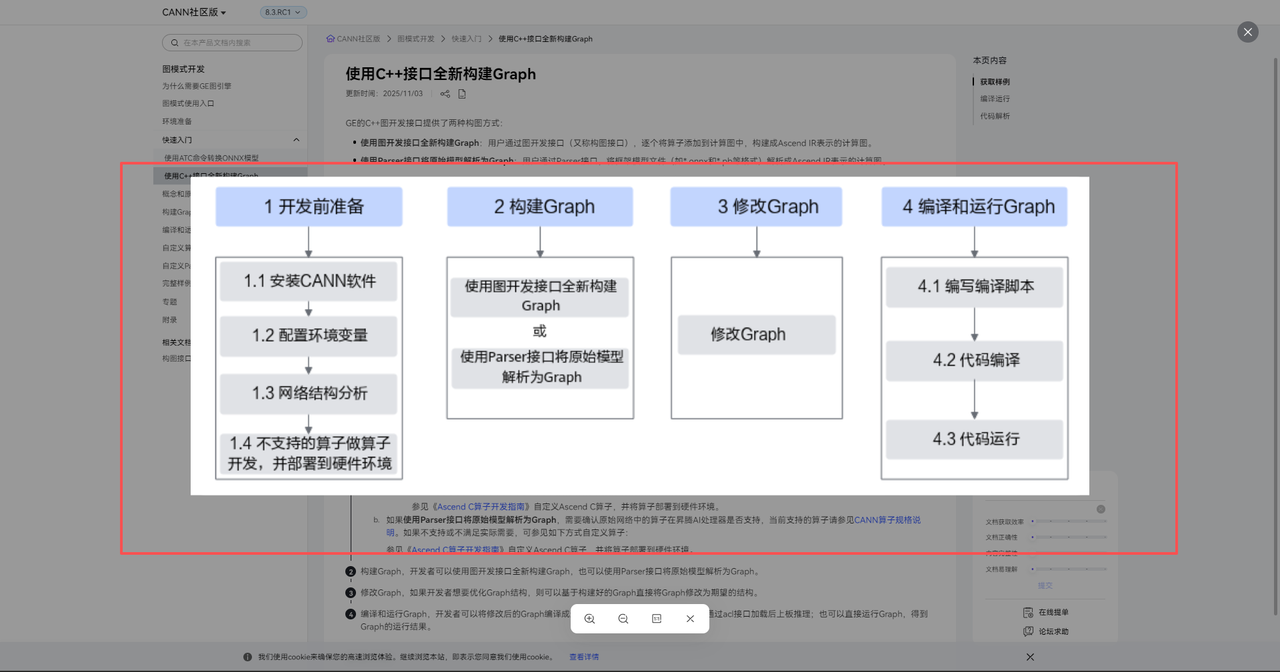
4.2.1 核心代码实现
#include "graph/graph.h"
#include "all_ops.h"
using namespace ge;
int main() {
// 1. 创建Graph对象
Graph graph("MyFirstGraph");
// 2. 定义Data节点(输入数据,shape为[1,1,28,28])
auto shape = vector<int64_t>({1, 1, 28, 28});
TensorDesc dataDesc(Shape(shape), FORMAT_NCHW, DT_FLOAT);
auto data = op::Data("data");
data.update_input_desc_x(dataDesc);
data.update_output_desc_y(dataDesc);
// 3. 定义Add算子(输入数据自加运算)
auto add = op::Add("add").set_input_x1(data).set_input_x2(data);
// 4. 定义Softmax算子(输出结果归一化)
auto softmax = op::SoftmaxV2("softmax").set_input_x(add);
// 5. 设置Graph输入输出节点
graph.SetInputs({data}).SetOutputs({softmax});
// 6. 编译Graph为OM模型(需调用aclgrphBuildInitialize、aclgrphBuildModel等接口,参考官方文档)
// ...(编译接口调用代码省略)
return 0;
}

4.2.2 编译与运行
- Makefile需新增
-lge库(支持构图功能),其余与方案1一致。 - 执行
make编译后运行,成功后可在指定路径生成OM模型。
4.2.3 查看更多特性
- 计算图优化
- 多流并行
- 内存复用
- 模型下沉
- 小shape算子计算优化技术
4.2.4 开放能力
1.面向上层AI框架对接和业务部署场景:GE提供了统一的图开发接口,支持对接上层基于图的开放框架,目前已适配PyTorch(TorchAir图模式)、TensorFlow、MindSpore、PaddlePaddle等主流AI框架;同时支持自定义图结构,帮助用户在昇腾硬件上高效部署神经网络业务。
2.面向AI模型整图编译和运行优化场景:GE开放了图编译优化和图执行能力,支持自定义图融合等功能,使能用户定制高性能图解决方案。
五、使用体验与总结
5.1 核心优势
- 省心高效:封装了AI开发中的适配、优化、部署细节,开发者可专注算法与业务逻辑。
- 适配性强:兼容主流AI框架与昇腾硬件,无需大幅修改代码即可快速迁移。
- 层次分明:从新手友好的ACL推理到资深开发者需要的自定义构图,覆盖不同需求场景。
六、使用体验与总结
先说说最让我惊喜的图引擎(GE),这绝对是 CANN 的核心王牌。之前做模型部署,要么用 Eager 模式一步步执行,速度慢还占资源;要么自己手动构图,调试起来费劲。GE 直接把这事儿简化到极致,支持两种构图方式:如果是现成的 ONNX、PB 模型,用 ATC 命令一行代码就能转换成昇腾适配的 OM 离线模型,我测试了 ResNet50 的转换,全程没报错,几分钟就搞定;如果是自定义网络,用 C++ 接口逐个添加算子就行,文档里给了 Data、Const、Conv2D 这些常用算子的完整示例,照着改改就能用,连动态多输入、多输出算子都支持得明明白白。
这段时间用下来,CANN 给我的最大感受就是 “省心” 和 “高效”。它把 AI 开发中最繁琐的适配、优化、部署工作都封装好了,开发者不用纠结底层细节,能专心做算法和业务。不管是刚入门的新手,还是需要深度定制的资深开发者,都能在里面找到适合自己的工具和接口。如果你的工作涉及 AI 模型开发、部署,尤其是要用到昇腾硬件,真心建议试试 CANN 社区版 8.3.RC1,它可能会让你在效率上有意外的收获~
再次祝愿CANN社区越来越好,引领AI鹏程万里,让智能无所不及~~

昇腾计算产业是基于昇腾系列(HUAWEI Ascend)处理器和基础软件构建的全栈 AI计算基础设施、行业应用及服务,https://devpress.csdn.net/organization/setting/general/146749包括昇腾系列处理器、系列硬件、CANN、AI计算框架、应用使能、开发工具链、管理运维工具、行业应用及服务等全产业链
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)